
CS70: Jean Walrand: Lecture 26. Continuous Probability - Pick a real - PowerPoint PPT Presentation
CS70: Jean Walrand: Lecture 26. Continuous Probability - Pick a real number. Continuous Probability - Pick a random real number. Choose a real number X , uniformly at random in [ 0 , 1000 ] . What is the probability that X is exactly equal to 100
CS70: Jean Walrand: Lecture 26. Continuous Probability - Pick a real number. Continuous Probability - Pick a random real number. Choose a real number X , uniformly at random in [ 0 , 1000 ] . What is the probability that X is exactly equal to 100 π = 314 . 1592625 ... ? Well, ..., 0. Continuous Probability Note: A radical change in approach. For a finite probability space, 1. Examples Ω = { 1 , 2 ,..., N } , we started with Pr [ ω ] = p ω . We then defined Let [ a , b ] denote the event that the point X is in the interval [ a , b ] . 2. Events Pr [ A ] = ∑ ω ∈ A p ω for A ⊂ Ω . We used the same approach for countable Ω . 3. Continuous Random Variables Pr [[ a , b ]] = length of [ a , b ] length of [ 0 , L ] = b − a = b − a 1000 . L 4. Expectation For a continuous space, e.g., Ω = [ 0 , L ] , we cannot start with Pr [ ω ] , because this will typically be 0. Instead, we start with Pr [ A ] for some 5. Bayes’ Rule Intervals like [ a , b ] ⊆ Ω = [ 0 , L ] are events. events A . Here, we started with A = interval, or union of intervals. More generally, events in this space are unions of intervals. 6. Multiple Random Variables Thus, the probability is a function from events to [ 0 , 1 ] . Can any Example: the event A - “within 50 of 0 or 1000” is function make sense? No! At least, it should be additive!. In our A = [ 0 , 50 ] ∪ [ 950 , 1000 ] . Thus, example, Pr [[ 0 , 50 ] ∪ [ 950 , 1000 ]] = Pr [[ 0 , 50 ]]+ Pr [[ 950 , 1000 ]] . Pr [ A ] = Pr [[ 0 , 50 ]]+ Pr [[ 950 , 10000 ]] = 1 10 . Shooting.. Continuous Random Variables: CDF Example: CDF A James Bond example. In Spectre, Mr. Hinx is chasing Bond who is in a Aston Martin DB10 . Example: Value of X in [ 0 , L ] with L = 1000. Hinx shoots at the DB10 and hits it at a random spot. Pr [ a < X ≤ b ] instead of Pr [ X = a ] . What is the chance Hinx hits the gas tank? For all a and b : specifies the behavior! 0 for x < 0 Assume the gas tank is a one foot circle and the DB10 is an Simpler: P [ X ≤ x ] for all x . x F X ( x ) = Pr [ X ≤ x ] = for 0 ≤ x ≤ 1000 1000 expensive 4 × 5 rectangle. 1 for x > 1000 Cumulative probability Distribution Function of X is Probability that X is within 50 of center: DB10 F X ( x ) = Pr [ X ≤ x ] 1 Pr [ a < X ≤ b ] = Pr [ X ≤ b ] − Pr [ X ≤ a ] = F X ( b ) − F X ( a ) . Pr [ 450 < X ≤ 550 ] = Pr [ X ≤ 550 ] − Pr [ X ≤ 450 ] gas 1000 − 450 550 Idea: two events X ≤ b and X ≤ a . = 1000 Difference is the event a < X ≤ b . 1000 = 1 100 Indeed: { X ≤ b }\{ X ≤ a } = { X ≤ b }∩{ X > a } = { a < X ≤ b } . Ω = { ( x , y ) : x ∈ [ 0 , 4 ] , y ∈ [ 0 , 5 ] } . = 10 The size of the event is π ( 1 ) 2 = π . The “size” of the sample space which is 4 × 5 . Since uniform, probability of event is π 20 . 1 The subscript X reminds us that this corresponds to the RV X .
Example: CDF Calculation of event with dartboard.. Density function. Example: hitting random location on gas tank. Random location on circle. Is the dart more like to be (near) . 5 or . 1 ? Probability between . 5 and . 6 of center? 1 Probability of “Near x” is Pr [ x < X ≤ x + δ ] . Recall CDF . Goes to 0 as δ goes to zero. y Try 0 for y < 0 Pr [ x < X ≤ x + δ ] y 2 . F Y ( y ) = Pr [ Y ≤ y ] = for 0 ≤ y ≤ 1 δ Random Variable: Y distance from center. 1 for y > 1 The limit as δ goes to zero. Probability within y of center: Pr [ x < X ≤ x + δ ] Pr [ X ≤ x + δ ] − Pr [ X ≤ x ] area of small circle lim = lim Pr [ Y ≤ y ] = Pr [ 0 . 5 < Y ≤ 0 . 6 ] = Pr [ Y ≤ 0 . 6 ] − Pr [ Y ≤ 0 . 5 ] δ δ δ → 0 δ → 0 area of dartboard = F Y ( 0 . 6 ) − F Y ( 0 . 5 ) F X ( x + δ ) − F X ( x ) π y 2 = lim = y 2 . = δ δ → 0 = . 36 − . 25 π d ( F X ( x )) Hence, = . 11 = . dx for y < 0 0 y 2 F Y ( y ) = Pr [ Y ≤ y ] = for 0 ≤ y ≤ 1 1 for y > 1 Density Examples: Density. Examples: Density. Example: “Dart” board. Example: uniform over interval [ 0 , 1000 ] Recall that Definition: (Density) A probability density function for a random variable X with cdf F X ( x ) = Pr [ X ≤ x ] is the function 0 for x < 0 0 for y < 0 f X ( x ) where f X ( x ) = F ′ 1 X ( x ) = for 0 ≤ x ≤ 1000 y 2 � x F Y ( y ) = Pr [ Y ≤ y ] = for 0 ≤ y ≤ 1 1000 F X ( x ) = − ∞ f X ( u ) du . 0 for x > 1000 1 for y > 1 Example: uniform over interval [ 0 , L ] Thus, 0 for y < 0 f Y ( y ) = F ′ Y ( y ) = 2 y for 0 ≤ y ≤ 1 0 for x < 0 Pr [ X ∈ ( x , x + δ ]] = F X ( x + δ ) − F X ( x ) ≈ f X ( x ) δ . 0 for y > 1 f X ( x ) = F ′ 1 X ( x ) = for 0 ≤ x ≤ L L 0 for x > L The cumulative distribution function (cdf) and probability distribution function (pdf) give full information. Use whichever is convenient.
Target U [ a , b ] Expo ( λ ) The exponential distribution with parameter λ > 0 is defined by f X ( x ) = λ e − λ x 1 { x ≥ 0 } � 0 , if x < 0 F X ( x ) = 1 − e − λ x , if x ≥ 0 . Note that Pr [ X > t ] = e − λ t for t > 0. Random Variables A Picture Some Examples Continuous random variable X , specified by 1. Expo is memoryless. Let X = Expo ( λ ) . Then, for s , t > 0, 1. F X ( x ) = Pr [ X ≤ x ] for all x . Pr [ X > t + s ] Cumulative Distribution Function (cdf) . Pr [ X > t + s | X > s ] = Pr [ X > s ] Pr [ a < X ≤ b ] = F X ( b ) − F X ( a ) e − λ ( t + s ) 1.1 0 ≤ F X ( x ) ≤ 1 for all x ∈ ℜ . = e − λ t = e − λ s 1.2 F X ( x ) ≤ F X ( y ) if x ≤ y . = Pr [ X > t ] . � x − ∞ f X ( u ) du or f X ( x ) = d ( F X ( x )) 2. Or f X ( x ) , where F X ( x ) = . dx ‘Used is a good as new.’ Probability Density Function (pdf). The pdf f X ( x ) is a nonnegative function that integrates to 1. � b Pr [ a < X ≤ b ] = a f X ( x ) dx = F X ( b ) − F X ( a ) 2. Scaling Expo . Let X = Expo ( λ ) and Y = aX for some a > 0. Then The cdf F X ( x ) is the integral of f X . 2.1 f X ( x ) ≥ 0 for all x ∈ ℜ . Pr [ Y > t ] = Pr [ aX > t ] = Pr [ X > t / a ] � ∞ − ∞ f X ( x ) dx = 1 . 2.2 e − λ ( t / a ) = e − ( λ / a ) t = Pr [ Z > t ] for Z = Expo ( λ / a ) . = Recall that Pr [ X ∈ ( x , x + δ )] ≈ f X ( x ) δ . Think of X taking Pr [ x < X < x + δ ] ≈ f X ( x ) δ discrete values n δ for n = ..., − 2 , − 1 , 0 , 1 , 2 ,... with Thus, a × Expo ( λ ) = Expo ( λ / a ) . � x Pr [ X = n δ ] = f X ( n δ ) δ . Pr [ X ≤ x ] = F x ( x ) = − ∞ f X ( u ) du
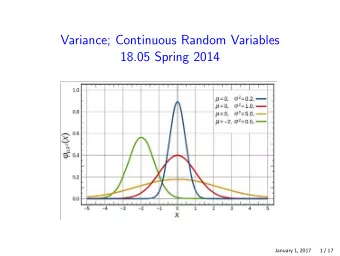
Some More Examples Expectation Expectation of function of RV 3. Scaling Uniform. Let X = U [ 0 , 1 ] and Y = a + bX where b > 0. Definition The expectation of a random variable X with pdf f ( x ) is Then, defined as � ∞ E [ X ] = − ∞ xf X ( x ) dx . Pr [ a + bX ∈ ( y , y + δ )] = Pr [ X ∈ ( y − a , y + δ − a Definition The expectation of a function of a random variable is Pr [ Y ∈ ( y , y + δ )] = )] defined as b b � ∞ Justification: Say X = n δ w.p. f X ( n δ ) δ . Then, Pr [ X ∈ ( y − a , y − a + δ b )] = 1 b δ , for 0 < y − a E [ h ( X )] = − ∞ h ( x ) f X ( x ) dx . = < 1 � ∞ b b b E [ X ] = ∑ ( n δ ) Pr [ X = n δ ] = ∑ ( n δ ) f X ( n δ ) δ = − ∞ xf X ( x ) dx . 1 Justification: Say X = n δ w.p. f X ( n δ ) δ . Then, = b δ , for a < y < a + b . n n � g ( x ) dx ≈ ∑ n g ( n δ ) δ . Choose � ∞ Thus, f Y ( y ) = 1 Indeed, for any g , one has E [ h ( X )] = ∑ h ( n δ ) Pr [ X = n δ ] = ∑ b for a < y < a + b . Hence, Y = U [ a , a + b ] . h ( n δ ) f X ( n δ ) δ = − ∞ h ( x ) f X ( x ) dx . 4. Scaling pdf. Let f X ( x ) be the pdf of X and Y = a + bX where g ( x ) = xf X ( x ) . n n b > 0. Then � g ( x ) dx ≈ ∑ n g ( n δ ) δ . Choose Indeed, for any g , one has Pr [ a + bX ∈ ( y , y + δ )] = Pr [ X ∈ ( y − a , y + δ − a Pr [ Y ∈ ( y , y + δ )] = ] g ( x ) = h ( x ) f X ( x ) . b b Pr [ Pr [ X ∈ ( y − a , y − a + δ b ] = f X ( y − a ) δ = b . b b b Fact Expectation is linear. Proof: As in the discrete case. Now, the left-hand side is f Y ( y ) δ . Hence, f Y ( y ) = 1 bf X ( y − a ) . b Variance Motivation for Gaussian Distribution Summary Continuous Probability Definition: The variance of a continuous random variable X is Key fact: The sum of many small independent RVs has a defined as Gaussian distribution. 1. pdf: Pr [ X ∈ ( x , x + δ ]] = f X ( x ) δ . � x This is the Central Limit Theorem. (See later.) 2. CDF: Pr [ X ≤ x ] = F X ( x ) = − ∞ f X ( y ) dy . E (( X − E ( X )) 2 ) = E ( X 2 ) − ( E ( X )) 2 var [ X ] = 3. U [ a , b ] , Expo ( λ ) , target. Examples: Binomial and Poisson suitably scaled. � ∞ � � ∞ � 2 � ∞ 4. Expectation: E [ X ] = − ∞ xf X ( x ) dx . − ∞ x 2 f ( x ) dx − This explains why the Gaussian distribution (the bell curve) = − ∞ xf ( x ) dx . � ∞ shows up everywhere. 5. Expectation of function: E [ h ( X )] = − ∞ h ( x ) f X ( x ) dx . 6. Variance: var [ X ] = E [( X − E [ X ]) 2 ] = E [ X 2 ] − E [ X ] 2 . 7. Gaussian: N ( µ , σ 2 ) : f X ( x ) = ... “bell curve”
Recommend






















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.