
4 2 5 6 6 7 1 Overfitting Overfitting 2 Examples - PDF document
Last Time ML II Decision trees and how to build them What might Information Gain we learn from these Entropy examples? Next up: Elements of a Learning System What can go wrong? How do we know how it went? 1 2
Last Time… ML II • Decision trees and how to build them What might • Information Gain we learn from these • Entropy examples? � • Next up: • Elements of a Learning System • What can go wrong? • How do we know how it went? 1 2 ML Intro: Review Learning Produces Models 1 What we have: • Trying to build a model of what 1 • Data: examples of our problem it means to be, e.g., yellow • Processed to produce features 2 2 1. Train over data • Average R, G, B values of pixels • Fuzzy or not fuzzy 2. Test on different data 3 3 • Turned into a feature vector 3. Deploy: the real test • X 1 : <200, 200, 40, yes> … • X 3 : <220, 10, 22, no> … • Sometimes labeled, sometimes not • Every step needs its own data 4 4 5 • X1: <200, 200, 40, yes, yellow=yes> • Split what we have into training data yellow? 6 What we want: and test data to see if our learner is good • A prediction over new data 5 6 3 4 One Possible Decision Tree One Possible Decision Tree sample attributes label • Predictions X 1 R G B Fuzzy? Yellow? X 2 X 3 ruh roh X 1 205 200 40 Y yes X 4 X 2 90 250 90 N no 7 8 X 3 220 10 22 N no X 4 205 210 10 N yes Prediction: X 5 235 210 30 N yes R G B Fuzzy? Is it yellow? X 6 50 215 60 Y no X 7 215 45 190 N no ✔ X 1 X 8 220 240 225 N yes ✗ X 2 X 4 1 3 ✔ 4 2 5 6 6 7 1
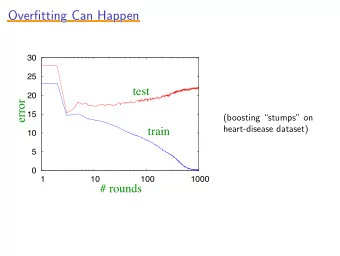
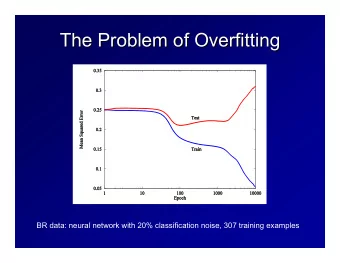
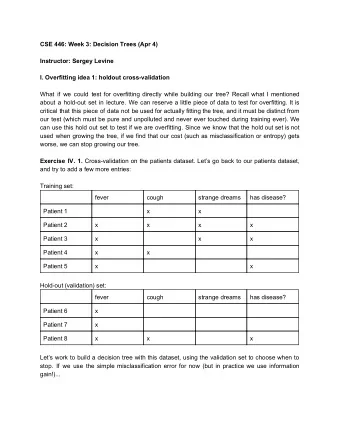
Overfitting Overfitting 2 Examples Attributes • Sometimes, model fits training data well but doesn’t • Irrelevant attributes à (training Class Bi- Feath- do well on test data overfitting data) pedal ers Attributes Examples (training Outcome Sparrow Y Y B • Can be it “overfit” to • If hypothesis space has Bipedal Flies Feathers data) Monkey Y N M the training data many dimensions (many Sparrow Y Y Y B Ostrich Y Y B attributes), may find • Model is too specific Monkey Y N N M meaningless regularity to training data Bat Y N M Ostrich Y N Y B • Doesn’t generalize to Bat Y Y N M Elephant N N M • Ex: Name starts with [A-M] à new information well Mammal Elephant N N N M • Learned model: (Y ∧ Y ∧ Y à B ∨ Y ∧ N ∧ N à M ∨ ...) 8 9 Overfitting 3 Overfitting • Incomplete training • Fix by by removing irrelevant features data à overfitting 1 • E.g., remove ‘first letter’ from feature vector 5 3 • Fix by getting more training data 2 6 4 • Fix by pruning low nodes in the decision tree • E.g., if improvement from best attribute at a node is below • Bad training/test 1 a threshold, stop and make this node a leaf rather than 5 split à overfitting generating child nodes 6 2 4 3 • Lots of other choices… 10 Noisy Data Pruning Decision Trees • Replace a whole subtree by a leaf node • Many kinds of “noise” can occur in the examples: • If: a decision rule establishes that he expected error rate in the subtree is • Two examples have same attribute/value pairs, but greater than in the single leaf. E.g., different classifications • Training: one training red success and two training blue failures • Test: three red failures and one blue success • Some values of attributes are incorrect • Consider replacing this subtree by a single Failure node. (leaf) • Errors in the data acquisition process, the preprocessing phase, // • After replacement we will have only two errors instead of five: • Classification is wrong (e.g., + instead of -) because of some error Pruned Test Training Color Color FAILURE • Some attributes are irrelevant to the decision-making red red process, e.g., color of a die is irrelevant to its outcome blue blue 2 success 1 success 4 failure 0 success 1 success 1 success • Some attributes are missing (are pangolins bipedal?) 1 failure 2 failures 3 failure 0 failure 12 13 2
Next Up Summary: Decision Tree Learning • One of the most widely used learning methods in practice • Evaluating a Learned Model • Can out-perform human experts in many problems • Elements of a Learning System • Strengths include • Fast • Simple to implement • Can convert result to a set of easily interpretable rules • Empirically valid in many commercial products • Handles noisy data • Weaknesses: • Univariate splits/partitioning using only one attribute at a time (limits types of possible trees) • Large decision trees may be hard to understand • Requires fixed-length feature vectors • Non-incremental (i.e., batch method) 14 15 A Learning System General Model of Learning Agents Four components of a machine learning system: Performance Standard 1. Representation: how do we describe the problem Sensors Critic space? Environment feedback 2. Actor: the part of the system that actually does changes Learning Performer things Element with KB knowledge learning goals 3. Critic: Provides the experience we learn from Problem Effectors Generator 4. Learner: the actual learning algorithm Agent Representing The Problem Representation: Examples to think about • Representing the problem to be solved is the first • How do we describe a problem? decision to be made (and most important) • Guessing an animal? • Playing checkers? • Requires understanding the domain – the field in • Labeling spam email? which the problem is set • OCRing a check? • There are two aspects of representing a problem: • Noticing new help desk topics? 1. Behavior that we want to learn • What data do you need to represent for each of 2. Inputs we will learn from these? What model might you learn? 3
Representation: Examples Actor • Guessing an animal: a tree of questions and answers • Want a system to do something. • Playing checkers: board, piece positions, rules; weights • Make a prediction for legal moves. • Sort into categories • Look for similarities • Labeling spam email: the frequencies of words used in this email and in our entire mailbox; Naive Bayes. • Once a model has been learned, we keep • OCRing: matrix of light/dark pixels; % light pixels; # using this piece straight lines, etc.; neural net. • Noticing new help desk topics: Clustering algorithms How Does the Actor Act? Critic • Guessing an animal: walk the tree, ask the questions • Provides the experience we learn from • Playing checkers: look through rules and weights to • Typically a set of examples + action that should identify a move be taken • Identifying spam: examine the set of features, • But, can be any kind of feedback that indicates calculate the probability of spam how close we are to where we want to be • OCRing a check: input the features for a digit, output probability for each of 0 through 9 • Feedback may be after one action, or a sequence • Help desk topics: output a representation of clusters Critic: Think About Critic: Possible Answers • How do we judge correct actions? • How do we judge correct actions? • Guessing an animal: Human feedback. • Guessing an animal: • OCRing digits: Human-categorized training set. • OCRing digits: • Identifying spam: Match to a set of human-categorized • Identifying spam: test documents. • Playing checkers: • Playing checkers: Who won? • Grouping documents: • Grouping documents: Which are most similar in language or content? • Can be generally categorized as supervised, unsupervised, reinforcement. 4
Recommend



















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.