Lesson 3 MEDICAL SUPPORT SYSTEMS FOR CHRONIC DISEASES Engineering and Management for Health University of Bergamo Overfitting Validation process. Overfitting Ettore Lanzarone March 18, 2020 LESSON 3
Lesson 3 Overfitting Linear regression R 2 = 0.6624 A decent model fit even though R 2 is not close to 1. Residuals are normally distributed and this confirm the goodness of fit. Overfitting Polynomial regression with a high order polynomial R 2 = 0.72 Is it a better model? No, the model includes the variability of data due to random errors associated with the observations.
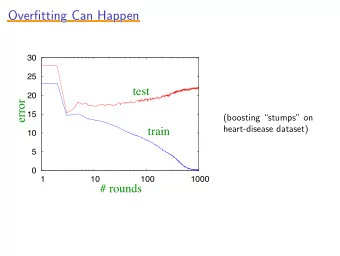
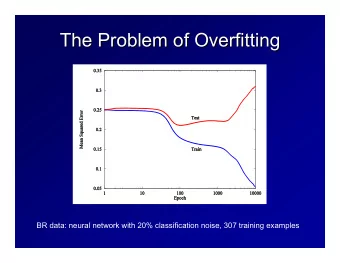
Lesson 3 Overfitting Modeling techniques tend to overfit the data. For example, let us consider multiple regression: • Every new variable added to the regression model increases the R 2 . • Interpretation: every additional predictive variable helps to explain yet more of the variability of the data variance. But this variability cannot be true! Solutions: • Expert evaluation. • Use proper validation techniques and not only simple metrics as the R 2 . Overfitting The solution is to assess the capability of the model to predict new data. This is actually the goal of estimating a model. You estimate the model on the black points and then new blue points arrive. Lower R 2 Higher R 2 Which one do you prefer?
Lesson 3 Overfitting • As models are used for prediction purposes, it is useful to evaluate the capacity to make accurate predictions for new samples of data. This process is referred to as “ validation ”. • One way is to literally obtain new observations. Once the model is developed from the original sample, a new study is conducted (replicating the original one as closely as possible) and the new data are used to assess the predictive validity of the model. • This procedure is usually viewed as impractical because of the requirement to conduct a new study, as well as the difficulty in truly replicating the original study. • An alternative, more practical procedure is cross-validation Cross-validation Cross-validation
Lesson 3 Cross-validation In cross-validation the original dataset is split into two parts: • Training set part of the dataset used to develop the model • Testing (or validation) set part of the dataset used to assess the goodness of fit A valid model should show good predictive accuracy. While R 2 offers no protection against is overfitting, cross validation inherently offers protection against overfitting. How to divide the dataset? Cross-validation QUESTION 1 Which portion of the sample should be in each part? • If the sample size is very large, it is often best to split the sample in half. • For smaller samples, it is more conventional to split the sample such that 2/3 of the observations are in the training set and 1/3 are in the testing set. • This also depends on the cross-validation technique.
Lesson 3 Cross-validation QUESTION 2 How should the sample be split? • The most common approach is to randomly divide the dataset, thus theoretically eliminating any systematic differences. • One alternative is to define matched pairs of subjects in the original dataset and to assign one member of each pair to the training set and the other to the testing set. Cross-validation 1. Model development (propose structure and parameters) 2. Cross-validation ITERATE UNTIL VALIDATION RESULTS ARE ACCEPTABLE 3. Model fitting considering the entire dataset; once validated all the dataset can be used to determine model parameters 4. Model applicable in real cases (e.g., integrated in a machine)
Lesson 3 Cross-validation Cross-Validation metrics Let us consider each point i in the testing set. The quality of the prediction is measured through the error Cross-validation Cross-Validation metrics There exist several indicators based on this error. They can be used to compare alternative models. The best model is associated with the lowest value of the adopted indicator.
Lesson 3 Cross-validation Cross-Validation metrics There exist several indicators based on this error. They can be used to compare alternative models. The best model is associated with the lowest value of the adopted indicator. Cross-validation Cross-Validation metrics
Lesson 3 Cross-validation Leave-one-out Cross Validation (LOOCV) Cross-validation Example Model 1 – linear regression
Lesson 3 Cross-validation Example Model 2 – quadratic regression This second model is associated with a lower MSE. Thus, it provides a better goodness of fit. Cross-validation Example Model 3 – join the dots Bad model, just to provide an example. Even though the R 2 is zero, this model is the worst one.
Lesson 3 Cross-validation The LOOCV is a good approach because every time the data in the training set are “ similar ” to those of the entire dataset ( about same quantity ). As the quality of the fitting depends on the amount of data, this preserve this information. However, the LOOCV is computationally expensive! The model has to be identified as many times as the cardinality of the dataset (number of observations in the dataset). Cross-validation K -Fold Cross Validation 1. Split the sample into k subsets of equal size 2. For each fold estimate a model on all the subsets except one 3. Use the left out subset to test the model, by calculating a cross validation metric of choice 4. Average the CV metric across subsets to get the cross validation error This k -fold validation reduces the computational effort (less replications required) while at the same time tries to have a relevant number of observations in the training set at each replication.
Lesson 3 Cross-validation K -Fold Cross Validation Example: 1. Split the data into 5 samples 2. Fit a model to the training subsets and use the testing subset to calculate a cross validation metric. 3. Repeat the process for the next sample, until all samples have been used to test the model Cross-validation Monte Carlo cross validation Randomly splits the dataset into training and validation data. The results are then averaged over the splits. In a stratified variant of this approach, the random samples are generated in such a way that the mean response value (i.e. the dependent variable in the regression) is equal in the training and testing sets.
Lesson 3 Cross-validation Other cross-validation approaches exist. All of them based on the same idea of dividing the dataset and computing the metrics above mentioned. Simulated and real data Simulated and real data
Lesson 3 Simulated and real data When the data are complex is also useful to first use simulated data. The overall process is: 1. Validate the model on simulated data 2. Validate the model on real acquired data • In-sample validation • Out-of-sample validation (the accurate cross validation) Some parts can be omitted depending on the features of the case. Simulated and real data Validate the model on simulated data Data Define the model for the dataset Assume a set of realistic model parameters
Lesson 3 Simulated and real data Validate the model on simulated data Data Define the model for the dataset Assume a set of Generate a simulated dataset realistic model considering the model parameters and the assumed parameters Simulated and real data Validate the model on simulated data Data Define the model for the dataset Assume a set of Generate a simulated dataset Estimate the model realistic model considering the model parameters based parameters and the assumed parameters on the simulated data Compare the estimated parameters with the assumed ones
Lesson 3 Simulated and real data • Compare the When we have point estimates, we can evaluate the error between the estimated parameters estimated value and the assumed value. with the assumed ones • When we have probability density function, we can consider the position of the assumed value with respect to the confidence interval of the estimation. This analysis allows to consider the effectiveness of the estimation approach: - Is the set of coefficient identifiable? - Is the approach suitable? However, it assumes that the model perfectly describe the real problem and the real data (observations are matematically generated considering the same model). Simulated and real data Compare the estimated parameters with the assumed ones It neglects the gap between the model and the reality. Each model is an abstraction of reality, which includes assumptions and simplifications. This analysis is only preliminary, devoted to assess the techical functioning of the modeling and estimation framework.
Lesson 3 Simulated and real data Validate the model on real acquired data This analysis includes the gap between the reality and the mathematical description. The best is to consider the out-of-sample validation (i.e., the cross-validation approaches above mentioned). If the results of the out-of-sample validation are not very satisfying, analyze the reasons. The in-sample validation can provide useful insights. For example, if the in-sample validation is satisfying, it could mean that a larger amount of observations are required but the structure of the model and the approach are appropriate. R A statistical tool: R
Recommend
More recommend
Unleash a World of Digital Possibilities—Browse, Share, and Explore Content Without Boundaries