
Introduction to High Performance Computing and Optimization Oliver - PowerPoint PPT Presentation
Institut fr Numerische Mathematik und Optimierung Introduction to High Performance Computing and Optimization Oliver Ernst Audience: 1./3. CMS, 5./7./9. Mm, doctoral students Wintersemester 2012/13 Contents 1. Introduction 2. Processor
Institut für Numerische Mathematik und Optimierung Introduction to High Performance Computing and Optimization Oliver Ernst Audience: 1./3. CMS, 5./7./9. Mm, doctoral students Wintersemester 2012/13
Contents 1. Introduction 2. Processor Architecture 3. Optimization of Serial Code 4. Parallel Computers 5. Parallelisation Fundamentals 6. OpenMP Programming 7. MPI Programming Oliver Ernst (INMO) Wintersemester 2012/13 1 HPC
Contents 1. Introduction 2. Processor Architecture 3. Optimization of Serial Code 4. Parallel Computers 5. Parallelisation Fundamentals 6. OpenMP Programming 7. MPI Programming Oliver Ernst (INMO) Wintersemester 2012/13 5 HPC
High Performance Computing Computing Three broad domains: Scientific Computing Engineering, earth sciences, medicine, finance, . . . Consumer Computing Audio/image/video processing, graph analysis, . . . Embedded Computing source: IPAM, TU München Control, communication, signal processing, . . . Limited number of critical kernels Dense and sparse linear algebra Convolution, stencils, filter-type operations source: Apple Inc. Graph algorithms Codecs . . . Cf. the 13 dwarfs/motifs of computing http://www.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-183.pdf source: Drexel U Oliver Ernst (INMO) Wintersemester 2012/13 6 HPC
High Performance Computing Hardware then and now IBM 360 Series (1964) ENIAC (1946) Cray 1 (1976) Connection Machine 2 IBM Blue Gene/Q (2012) (1987) SGI Origin 2000 (1996) Oliver Ernst (INMO) Wintersemester 2012/13 7 HPC
High Performance Computing Developments 70 years of electronic computing initially unique pioneering machines Later (1970s-1990s) specialized designs and hardware industry (CDC, Cray, TMC) Up to here: leading edge in computing determined by HPC requirements. Last 20 years: commodity hardware designed for other purposes (business transactions, gaming) adapted/modified for HPC Dominant design: general-purpose microprocessor with hierarchical memory structure Oliver Ernst (INMO) Wintersemester 2012/13 8 HPC
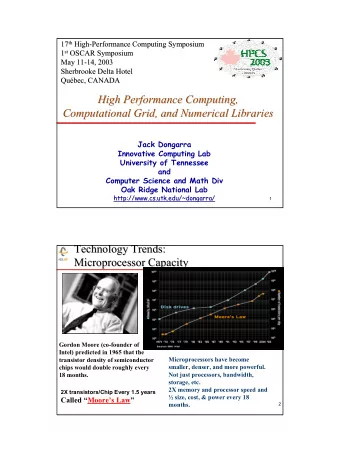
High Performance Computing Moore’s Law Gordon Moore , cofounder of Intel, in 1965 1 “Integrated circuits will lead to such won- ders as home computers—or at least terminals connected to a central computer—automatic controls for automobiles, and personal porta- ble communications equipment. [. . . ] The complexity for minimum component costs has increased at a rate of roughly a factor of two per year (see graph). Certainly over the short term this rate can be expected to conti- nue, if not to increase.” Folklore: period of 18 months for performance doubling of computer chips. 1 Gordon E. Moore, “Cramming More Components onto Integrated Circuits,” Electronics, pp. 114–117, April 19, 1965. Oliver Ernst (INMO) Wintersemester 2012/13 9 HPC
High Performance Computing Moore’s Law: some data Year of Transistor Name CPU Transistor counts 1971-2012 Introduction Count 1E+10 1971 2.300 Intel 4004 1972 3.500 Intel 8008 1E+09 1974 4.100 Motorola 6800 1E+08 1974 4.500 Intel 8080 Transistor Count 1976 8.500 Zilog Z80 1E+07 1978 29.000 Intel 8086 1E+06 1979 68.000 Motorola 68000 1982 134.000 Intel 80286 1E+05 1985 275.000 Intel 80386 1E+04 1989 1.180.000 Intel 80484 1993 3.100.000 Intel Pentium 1E+03 1995 5.500.000 Intel Pentium Pro 1970 1974 1978 1983 1987 1991 1995 1999 2004 2008 2012 1996 4.300.000 AMD K5 Year of Introduction 1997 7.500.000 Pentium II 1997 8.800.000 AMD K6 1999 9.500.000 Pentium III 2000 42.000.000 Pentium 4 2003 105.900.000 AMD K8 2003 220.000.000 Itanium 2 2006 291.000.000 Core 2 Duo 2007 904.000.000 Opteron 2400 2007 789.000.000 Power 6 2008 758.000.000 AMD K10 2010 2.300.000.000 Nehalem-EX For a long time, increased transistor count translated to 2010 1.170.000.000 Core i7 Gulftown 2011 2.600.000.000 Xeon Westmere-EX reduced cycle time for CPUs . . . 2011 2.270.000.000 Core i7 Sandy Bridge 2012 1.200.000.000 AMD Bulldozer Oliver Ernst (INMO) Wintersemester 2012/13 10 HPC
High Performance Computing Moore’s Law: heat wall source: M. Püschel, ETH Zürich Oliver Ernst (INMO) Wintersemester 2012/13 11 HPC
High Performance Computing Top 500, June 2012 Rank Site Computer Sequoia - BlueGene/Q, Power BQC 16C 1.60 DOE/NNSA/LLNL 1 GHz, Custom United States IBM RIKEN Advanced Institute for K computer, SPARC64 VIIIfx 2.0GHz, Tofu Computational Science 2 interconnect (AICS) Fujitsu Japan DOE/SC/Argonne National Mira - BlueGene/Q, Power BQC 16C 1.60GHz, 3 Laboratory Custom United States IBM SuperMUC - iDataPlex DX360M4, Xeon E5-2680 Leibniz Rechenzentrum 4 8C 2.70GHz, Infiniband FDR Germany IBM Ranking based on perfor- National Supercomputing Tianhe-1A - NUDT YH MPP, Xeon X5670 6C 2.93 5 Center in Tianjin GHz, NVIDIA 2050 mance running L INPACK - China NUDT benchmark, the LU facto- DOE/SC/Oak Ridge National Jaguar - Cray XK6, Opteron 6274 16C 2.200GHz, 6 Laboratory Cray Gemini interconnect, NVIDIA 2090 rization of a matrix. United States Cray Inc. Fermi - BlueGene/Q, Power BQC 16C 1.60GHz, CINECA 7 Custom Italy IBM Forschungszentrum Juelich JuQUEEN - BlueGene/Q, Power BQC 16C 8 (FZJ) 1.60GHz, Custom Germany IBM Curie thin nodes - Bullx B510, Xeon E5-2680 8C CEA/TGCC-GENCI 9 2.700GHz, Infiniband QDR France Bull National Supercomputing Nebulae - Dawning TC3600 Blade System, Xeon Centre in Shenzhen (NSCS) X5650 6C 2.66GHz, Infiniband QDR, NVIDIA 2050 10 China Dawning Oliver Ernst (INMO) Wintersemester 2012/13 12 HPC
High Performance Computing Top 500, June 2012 Top ranked system: Sequoia - BlueGene/Q Location: Lawrence Livermore National Laboratory (CA/USA) Purpose: nuclear weapons simulations Manufacturer: IBM source: LLNL Operating system: Linux 1,572,864 cores Memory: 1,572,864 GB Power consumption: 7.89 MW Peak performance: 20,132.7 TFlops 2 Sustained performance: 16,324.8 TFlops (81%) Cf. 10,510 TFlops of top system November 2011 (K Computer, Japan) Cf. top system of 1st Top500 (TNC CM5): 273,930 times faster. 2 1 TFlop = 10 12 Flops Oliver Ernst (INMO) Wintersemester 2012/13 13 HPC
High Performance Computing Top 500, progress Oliver Ernst (INMO) Wintersemester 2012/13 14 HPC
High Performance Computing Efficiency Most numerical code runs at ≈ 10% efficiency. Coping strategies: Do nothing and hope hardware gets faster. (Worked up to 2004) Rely on compiler to generate optimal code. (Not yet) Understand intricacies of modern computer architectures and learn to write optimized code. Write code which is efficient for any architecture. Know the most efficient numerical libraries and use them. Oliver Ernst (INMO) Wintersemester 2012/13 15 HPC
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.