
RNN Input Layer RNN Hidden Layer RNN h t-1 h t x t (Picture - PowerPoint PPT Presentation
Outline Recurrent Neural Networks (RNNs) Neural Machine Transla/on NMT basics (Sutskever et al., 2014) ABenCon mechanism (Bahdanau et al., 2015) Marcello Federico 2016 Recurrent Neural Networks (RNNs) Based on slides kindly provided
Outline • Recurrent Neural Networks (RNNs) Neural Machine Transla/on • NMT basics (Sutskever et al., 2014) • ABenCon mechanism (Bahdanau et al., 2015) Marcello Federico 2016 Recurrent Neural Networks (RNNs) Based on slides kindly provided by RNN Thang Luong, Stanford U. (Picture adapted from Andrej Karparthy)
RNN – Input Layer RNN – Hidden Layer RNN h t-1 h t x t (Picture adapted from Andrej Karparthy) (Picture adapted from Andrej Karparthy) RNNs to represent sequences! RNN – Hidden Layer Outline • Recurrent Neural Networks (RNNs) • NMT basics (Sutskever et al., 2014) h t-1 h t – Encoder-Decoder. – Training vs. TesCng. – BackpropagaCon. – More about RNNs. x t • ABenCon mechanism (Bahdanau et al., 2015) (Picture adapted from Andrej Karparthy)
Neural Machine Transla/on (NMT) Neural Machine Transla/on (NMT) _ _ Je Je suis étudiant suis étudiant _ _ I am a student Je suis étudiant I am a student Je suis étudiant • Model P(target | source) directly. • RNNs trained end-to-end (Sutskever et al., 2014). Neural Machine Transla/on (NMT) Neural Machine Transla/on (NMT) _ _ Je suis étudiant Je suis étudiant _ _ I am a student Je suis étudiant I am a student Je suis étudiant • RNNs trained end-to-end (Sutskever et al., 2014). • RNNs trained end-to-end (Sutskever et al., 2014).
Neural Machine Transla/on (NMT) Neural Machine Transla/on (NMT) _ _ Je Je suis étudiant suis étudiant _ _ I am a student Je suis étudiant I am a student Je suis étudiant • RNNs trained end-to-end (Sutskever et al., 2014). • RNNs trained end-to-end (Sutskever et al., 2014). Neural Machine Transla/on (NMT) Neural Machine Transla/on (NMT) _ _ Je suis étudiant Je suis étudiant _ _ I am a student Je suis étudiant I am a student Je suis étudiant • RNNs trained end-to-end (Sutskever et al., 2014). • RNNs trained end-to-end (Sutskever et al., 2014).
Recurrent Connec/ons Neural Machine Transla/on (NMT) IniCal _ _ Je Je suis étudiant suis étudiant states Encoder Decoder _ I am a student Je suis étudiant • RNNs trained end-to-end (Sutskever et al., 2014). _ I am a student Je suis étudiant • Encoder-decoder approach. • OYen set to 0. Word Embeddings Recurrent Connec/ons _ _ Je suis étudiant Je suis étudiant Encoder 1 st layer Source Target embeddings embeddings _ _ I am a student Je suis étudiant I am a student Je suis étudiant • Randomly iniCalized, one for each language. • Different across layers and encoder / decoder. – Learnable parameters.
Recurrent Connec/ons Recurrent Connec/ons _ _ Je Je suis étudiant suis étudiant Encoder Decoder 2 nd layer 2 nd layer _ _ I am a student Je suis étudiant I am a student Je suis étudiant • Different across layers and encoder / decoder. • Different across layers and encoder / decoder. Recurrent Connec/ons Outline _ Je suis étudiant • Recurrent Neural Networks (RNNs) • NMT basics (Sutskever et al., 2014) Decoder – Encoder-Decoder. 1 st layer – Training vs. TesCng. – BackpropagaCon. – More about RNNs. _ I am a student Je suis étudiant • Different across layers and encoder / decoder. • ABenCon mechanism (Bahdanau et al., 2015)
_ Je suis étudiant Training vs. Tes/ng Training – So1max _ Je suis étudiant SoYmax • Training parameters – Correct translaCons Scores Probs are available. = Je suis so+max _ |V| I am a student Je suis étudiant func)on P( suis | Je, source) suis étudiant • Tes)ng – Only source • Scores � probabiliCes. sentences are given. _ I am a student Je suis étudiant _ Je suis étudiant Training – So1max Training Loss _ Je suis étudiant SoYmax parameters Scores = Je suis |V| suis étudiant _ I am a student Je suis étudiant • Hidden states � scores. • Maximize P(target | source): – Decompose into individual word predicCons.
Training Loss Training Loss -log P(Je) -log P(suis) -log P(étudiant) _ _ I am a student Je suis étudiant I am a student Je suis étudiant • Sum of all individual losses • Sum of all individual losses Training Loss Training Loss -log P(Je) -log P(suis) -log P(_) _ _ I am a student Je suis étudiant I am a student Je suis étudiant • Sum of all individual losses • Sum of all individual losses
Tes/ng Tes/ng • Feed the most likely word • Feed the most likely word Tes/ng Tes/ng • Feed the most likely word • Feed the most likely word
Tes/ng Outline • Recurrent Neural Networks (RNNs) • NMT basics (Sutskever et al., 2014) – Encoder-Decoder. – Training vs. TesCng. – BackpropagaCon. – More about RNNs. NMT beam-search decoders • ABenCon mechanism (Bahdanau et al., 2015) are much simpler! Possible beam search decoder Backpropaga/on Through Time -log P(_) Init to 0 _ I am a student Je suis étudiant
Backpropaga/on Through Time Backpropaga/on Through Time -log P(étudiant) -log P(suis) _ _ I am a student Je suis étudiant I am a student Je suis étudiant Backpropaga/on Through Time Backpropaga/on Through Time -log P(étudiant) -log P(suis) _ _ I am a student Je suis étudiant I am a student Je suis étudiant
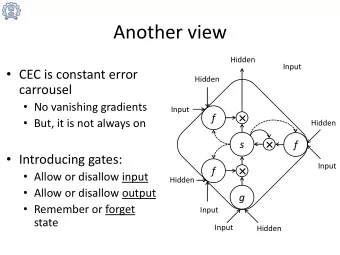
Backpropaga/on Through Time Recurrent types – vanilla RNN RNN Vanishing gradient problem! _ I am a student Je suis étudiant RNN gradients are accumulated. Vanishing gradients Outline • Recurrent Neural Networks (RNNs) • NMT basics (Sutskever et al., 2014) Chain Rule – Encoder-Decoder. – Training vs. TesCng. Bound Rules – BackpropagaCon. – More about RNNs. Bound Largest singular value • ABenCon mechanism (Bahdanau et al., 2015) (Pascanu et al., 2013)
C’mon, it’s Vanishing gradients been around Recurrent types – LSTM for 20 years! LSTM Chain Rule LSTM cells Bound Rules • Long-Short Term Memory (LSTM) – (Hochreiter & Schmidhuber, 1997) Sufficient Cond Chain Rule • LSTM cells are addiCvely updated – Make backprop through Cme easier. (Pascanu et al., 2013) Vanishing gradients LSTM Building LSTM Chain Rule Nice gradients! Bound Rules Sufficient Cond • A naïve version. (Pascanu et al., 2013)
LSTM LSTM Building LSTM Building LSTM Input gates Output gates • Add output gates: extract informaCon. • Add input gates: control input signal. • (Zaremba et al., 2014). LSTM Building LSTM Why LSTM works? LSTM t-1 LSTM t + Forget gates • The addiCve operaCon is the key! • BackpropaCon path through the cell is effecCve. • Add forget gates: control memory.
Why LSTM works? LSTM t-1 LSTM t + • The addiCve operaCon is the key! • BackpropaCon path through the cell is effecCve. Forget gates are important! Deep RNNs (Sutskever et al., 2014) Other RNN units Summary _ Je suis étudiant • (Graves, 2013): revived LSTM. • Generalize well. – Direct connecCons between cells and gates. • Small memory. _ I am a student Je suis étudiant • Gated Recurrent Unit (GRU) – (Cho et al., 2014a) BidirecConal RNNs • Simple decoder. (Bahdanau et al., 2015) – No cells, same addiCve idea. _ Je suis étudiant • LSTM vs. GRU: mixed results (Chung et al., 2015). _ Je suis étudiant I am a student
Outline Why? _ Je suis étudiant • Recurrent Neural Networks (RNNs) • NMT basics • ABenCon mechanism _ I am a student Je suis étudiant • A fixed-dimensional source vector. • Rare words • Problem: Markovian process. Sentence Length Problem AQen/on Mechanism _ Je suis étudiant Without aBenCon With aBenCon Pool of source states _ I am a student Je suis étudiant • SoluCon: random access memory – Retrieve as needed. – cf. Neural Turing Machine (Graves et al., 2014). (Bahdanau et al., 2015)
_ Je suis étudiant Alignments as a by-product suis Attention Layer _ I am a student Je suis étudiant Context What’s next? vector ? (Bahdanau et al., 2015) _ I am a student Je • Recent innovaCon in deep learning: – Control problem (Mnih et al., 14) – Speech recogniCon (Chorowski et al., 15) – Image capCon generaCon (Xu et al., 15) AQen/on Mechanism – Scoring suis Attention Layer Context Simplified ABenCon vector (Bahdanau et al., 2015) ? + _ Je suis étudiant Deep LSTM _ I am a student Je (Sutskever et al., 2014) • Compare target and source hidden states. _ I am a student Je suis étudiant
AQen/on Mechanism – Scoring AQen/on Mechanism – Scoring suis suis Attention Layer Attention Layer Context Context vector vector 3 3 5 1 ? ? _ _ I am a student Je I am a student Je • Compare target and source hidden states. • Compare target and source hidden states. AQen/on Mechanism – Scoring AQen/on Mechanism – Scoring suis suis Attention Layer Attention Layer Context Context vector vector 3 5 3 5 1 1 ? ? _ _ I am a student Je I am a student Je • Compare target and source hidden states. • Compare target and source hidden states.
Recommend





















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.