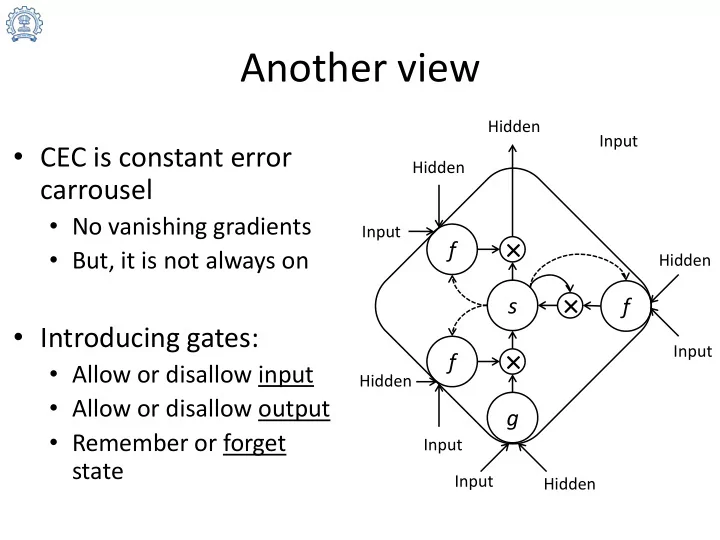
Another view Hidden Input CEC is constant error Hidden carrousel - PowerPoint PPT Presentation
Another view Hidden Input CEC is constant error Hidden carrousel No vanishing gradients Input f But, it is not always on Hidden s f Introducing gates: Input f Allow or disallow input Hidden Allow or
Another view Hidden Input • CEC is constant error Hidden carrousel • No vanishing gradients Input × f • But, it is not always on Hidden × s f • Introducing gates: Input × f • Allow or disallow input Hidden • Allow or disallow output g • Remember or forget Input state Input Hidden
A few words about the LSTM • CEC: With the forget gate, influence of the state forward can be modulated such that it can be remembered for a long time, until the state or the input changes to make LSTM forget it. This ability or the path to pass the past-state unaltered to the future-state (and the gradient backward) is called constant error carrousel (CEC). It gives LSTM the ability to remember long term (hence, long short term memory) • Blocks: Since there are just too many weights to be learnt for a single state bit, several state bits can be combined into a single block such that the state bits in a block share gates • Peepholes: The state itself can be an input for the gate using peephole connections • GRU: In a variant of LSTM called gated recurrent unit (GRU), input gate can simply be one-minus-forget-gate. That is, if the state is being forgotten , then replace it by input, and if it is being remembered , then block the input
… … Output Layer t t t y 1 y k y K 𝑥 𝑑𝑙 … … t-1 t-1 b h b H Hidden Layer … Block H/C t b c Block 1 w h ω t b ω f w i ω t ) h(s c h t b ϕ w h ϕ s c t s c t t s c f w i ϕ CEC w h ι t b ι f Legend w i ι t ) g(a c Current g Delayed w ic w hc Peephole LSTM block … … Input Layer t t t x 1 x i x I Adapted from: “Supervised Sequence Labelling with Recurrent Neural Networks .” by Alex Graves
… … Output Layer t t t y 1 y k y K 𝑥 𝑑𝑙 … … t-1 t-1 b h b H Hidden Layer … Block H/C t b c Block 1 w h ω t b ω f w i ω t ) h(s c h t-1 s c t b ϕ w h ϕ s c t s c t t s c f w i ϕ CEC w h ι t b ι f Legend w i ι t ) g(a c Current g Delayed w ic w hc Peephole Adding peep-holes … … Input Layer t t t x 1 x i x I Adapted from: “Supervised Sequence Labelling with Recurrent Neural Networks .” by Alex Graves
… … Output Layer t t t y 1 y k y K 𝑥 𝑑𝑙 … … t-1 t-1 b h b H Hidden Layer … Block H/C t b c Block 1 w h ω t b ω f w i ω t ) h(s c Forward Pass h t-1 s c t b ϕ w h ϕ s c t s c t t s c f w i ϕ Input gate: CEC w h ι t b ι f 𝐽 𝐼 𝐷 w i ι 𝑢 = 𝑥 𝑗𝑚 𝑦 𝑗 𝑢 𝑢−1 𝑢−1 𝑏 𝑚 + 𝑥 ℎ𝑚 𝑐 ℎ + 𝑥 𝑑𝑚 𝑡 𝑑 t ) g(a c 𝑗=1 ℎ=1 𝑑=1 g 𝑢 = 𝑔(𝑏 𝑚 𝑢 ) 𝑐 𝑚 w ic w hc … … Input Layer t t t x 1 x i x I Adapted from: “Supervised Sequence Labelling with Recurrent Neural Networks .” by Alex Graves
… … Output Layer t t t y 1 y k y K 𝑥 𝑑𝑙 … … t-1 t-1 b h b H Hidden Layer … Block H/C t b c Block 1 w h ω t b ω f Forward Pass w i ω t ) h(s c h t-1 s c Forget gate: t b ϕ w h ϕ 𝐽 𝐼 𝐷 s c t s c t t s c f 𝑢 = 𝑥 𝑗𝜚 𝑦 𝑗 𝑢 𝑢−1 w i ϕ 𝑢−1 𝑏 𝜚 + 𝑥 ℎ𝜚 𝑐 ℎ + 𝑥 𝑑𝜚 𝑡 𝑑 CEC 𝑗=1 ℎ=1 𝑑=1 w h ι t b ι 𝑢 = 𝑔(𝑏 𝜚 𝑢 ) 𝑐 𝜚 f w i ι t ) g(a c Cell input: g 𝐽 𝐼 𝑢 = 𝑥 𝑗𝑑 𝑦 𝑗 𝑢 𝑢−1 𝑏 𝑑 + 𝑥 ℎ𝑑 𝑐 ℎ w ic w hc 𝑗=1 ℎ=1 𝑢 = 𝑐 𝜚 𝑢 𝑡 𝑑 𝑢−1 + 𝑐 𝑚 … … Input Layer t t t 𝑢 (𝑏 𝑑 𝑢 ) x 1 x i x I 𝑡 𝑑 Adapted from: “Supervised Sequence Labelling with Recurrent Neural Networks .” by Alex Graves
… … Output Layer t t t y 1 y k y K 𝑥 𝑑𝑙 … … t-1 t-1 b h b H Hidden Layer … Block H/C t b c Block 1 w h ω t b ω f w i ω t ) h(s c Forward Pass h t-1 s c t b ϕ w h ϕ s c t s c t t s c f Output gate: w i ϕ 𝐽 𝐼 𝐷 CEC 𝑢 = 𝑥 𝑗𝜕 𝑦 𝑗 𝑢 𝑢−1 𝑢 𝑏 𝜕 + 𝑥 ℎ𝜕 𝑐 ℎ + 𝑥 𝑑𝜕 𝑡 𝑑 w h ι t b ι f 𝑗=1 ℎ=1 𝑑=1 w i ι t ) g(a c 𝑢 = 𝑔(𝑏 𝜕 𝑢 ) 𝑐 𝜕 g w ic w hc Cell output: 𝑢 = 𝑐 𝜕 𝑢 𝑖(𝑡 𝑑 𝑢 ) 𝑐 𝑑 … … Input Layer t t t x 1 x i x I Adapted from: “Supervised Sequence Labelling with Recurrent Neural Networks .” by Alex Graves
Revisiting backpropagation through b- diagrams • An efficient way to perform gradient descent in NNs • Efficiency comes from local computations • This can be visualized using b-diagrams – Propagate x (actually w ) forward – Propagate 1 backward Source: “Neural Networks - A Systematic Introduction,” by Raul Rojas, Springer-Verlag, Berlin, New-York, 1996.
Chain rule using b-diagram Source: “Neural Networks - A Systematic Introduction,” by Raul Rojas, Springer-Verlag, Berlin, New-York, 1996.
Addition of functions using b-diagram Source: “Neural Networks - A Systematic Introduction,” by Raul Rojas, Springer-Verlag, Berlin, New-York, 1996.
Weighted edge on a b-diagram Source: “Neural Networks - A Systematic Introduction,” by Raul Rojas, Springer-Verlag, Berlin, New-York, 1996.
Product in a b-diagram f * fg g f ’g * 1 g’f
… … Output Layer t t t y 1 y k y K 𝑥 𝑑𝑙 … … Hidden Layer … Block H/C t b c Block 1 w h ω t b ω f w i ω t ) h(s c Backpropagation h t-1 s c 𝑢 ≝ 𝜖𝑀 𝑢 ≝ 𝜖𝑀 t b ϕ w h ϕ ϵ 𝑑 𝑢 𝜗 𝑡 𝑢 s c t s c t t 𝜖𝑐 𝑑 𝜖𝑡 𝑑 s c f w i ϕ CEC w h ι t b ι f Cell output: w i ι t ) g(a c g 𝐿 𝐻 w ic w hc 𝑢 = 𝑥 𝑑𝑙 𝜀 𝑙 𝑢 𝑢+1 𝜗 𝑑 + 𝑥 𝑑 𝜀 … … 𝑙=1 =1 Input Layer t t t x 1 x i x I Adapted from: “Supervised Sequence Labelling with Recurrent Neural Networks .” by Alex Graves
… … Output Layer t t t y 1 y k y K 𝑥 𝑑𝑙 … … t-1 t-1 b h b H Hidden Layer … Block H/C t b c Block 1 w h ω t b ω f Backpropagation w i ω t ) h(s c h t-1 s c 𝐷 𝑢 = 𝑔 ′ (𝑏 𝜕 𝑢 ) 𝑖(𝑡 𝑑 𝑢 )𝜗 𝑑 𝑢 Output gate: 𝜀 𝜕 t b ϕ w h ϕ s c t s c t t s c f 𝑑=1 w i ϕ State: CEC w h ι t b ι 𝑢 𝜗 𝑡 𝑢 = 𝑐 𝜕 𝑢 𝑖 ′ 𝑡 𝑑 𝑢 𝜗 𝑑 𝑢 + 𝑐 ∅ 𝑢+1 𝜗 𝑡 𝑢+1 𝜀 𝜕 f 𝑢+1 + 𝑥 𝑑∅ 𝜀 ∅ 𝑢+1 + 𝑥 𝑑𝜕 𝜀 𝜕 𝑢 w i ι +𝑥 𝑑𝑚 𝜀 𝑚 t ) g(a c g w ic w hc 𝑢 = 𝑐 𝑚 𝑢 ′ (𝑏 𝑑 𝑢 )𝜗 𝑡 𝑢 Cells: 𝜀 𝑑 … … Input Layer t t t x 1 x i x I Adapted from: “Supervised Sequence Labelling with Recurrent Neural Networks .” by Alex Graves
… … Output Layer t t t y 1 y k y K 𝑥 𝑑𝑙 … … t-1 t-1 b h b H Hidden Layer … Block H/C t b c Block 1 w h ω t b ω f w i ω t ) h(s c Backpropagation h t-1 s c t b ϕ w h ϕ s c t s c t t s c f Forget gate: w i ϕ CEC 𝐷 𝑢 = 𝑔 ′ (𝑏 ∅ 𝑢 ) 𝑡 𝑑 𝑢−1 𝜗 𝑡 𝑢 𝜀 ∅ w h ι t b ι f 𝑑=1 w i ι t ) g(a c Input gate: g 𝐷 w ic w hc 𝑢 = 𝑔 ′ (𝑏 𝑚 𝑢 ) (𝑏 𝑑 𝑢 )𝜗 𝑡 𝑢 𝜀 𝑚 𝑑=1 … … Input Layer t t t x 1 x i x I Adapted from: “Supervised Sequence Labelling with Recurrent Neural Networks .” by Alex Graves
Contents • Need for memory to process sequential data • Recurrent neural networks • LSTM basics • Some applications of LSTM in NLP
Gated Recurrent Unit (GRU) Hidden Input • Reduces the need for Hidden input gate by reusing Input the forget gate × f Hidden × s f Input × 1-x Hidden g Input Input Hidden
GRUs combine input and forget gates LSTM unit with LSTM unit RNN unit peepholes Gated Recurrent Unit combines input and forget gate as f and 1-f Source: Cho, et al. (2014), and “Understanding LSTM Networks”, by C Olah, http://colah.github.io/posts/2015-08-Understanding-LSTMs/
Sentence generation • Very common for image captioning • Input is given only in the beginning • This is a one-to-many task A boy swimming in water <END> LSTM LSTM LSTM LSTM LSTM LSTM CNN
Video Caption Generation Source: “Translating Videos to Natural Language Using Deep Recurrent Neural Networks”, Venugopal et al., ArXiv 2014
Pre-processing for NLP • The most basic pre-processing is to convert words into an embedding using Word2Vec or GloVe • Otherwise, a one-hot-bit input vector can be too long and sparse, and require lots on input weights
Sentiment analysis • Very common for customer review or new article analysis • Output before the end can be discarded (not used for backpropagation) • This is a many-to-one task Positive LSTM LSTM LSTM LSTM LSTM LSTM Embed Embed Embed Embed Embed Embed Very pleased with their service <END>
Machine translation using encoder- decoder Source: “ Learning Phrase Representations using RNN Encoder – Decoderfor Statistical Machine Translation”, Cho et al., ArXiv 2014
Multi-layer LSTM • More than one hidden layer can be used y n-3 y n-2 y n-1 y n Second hidden layer LSTM2 LSTM2 LSTM2 LSTM2 First hidden layer LSTM1 LSTM1 LSTM1 LSTM1 x n-3 x n-2 x n-1 x n
Bi-directional LSTM • Many problems require a reverse flow of information as well • For example, POS tagging may require context from future words y n-3 y n-2 y n-1 y n Backward layer LSTM2 LSTM2 LSTM2 LSTM2 Forward layer LSTM1 LSTM1 LSTM1 LSTM1 x n-3 x n-2 x n-1 x n
Recommend



















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.