
Survival Analysis APTS 2016/17 Ingrid Van Keilegom ORSTAT KU - PowerPoint PPT Presentation
Survival Analysis APTS 2016/17 Ingrid Van Keilegom ORSTAT KU Leuven Glasgow, August 21-25, 2017 Basic concepts Nonparametric estimation Hypothesis testing in a nonparametric Basic concepts setting Proportional hazards models
Basic concepts Interval censoring Nonparametric ⋄ The event of interest is only known to occur within a estimation Hypothesis certain interval ( L , U ) testing in a nonparametric ⋄ Contrary to right and left censoring, we never observe setting the exact survival time Proportional hazards ⋄ Typically occurs if diagnostic tests are used to assess models the event of interest Parametric survival models ⋄ Ex : Interval censoring in malaria trial → The exact time to malaria is between the last negative and the first positive test
Basic Truncation : Individuals of a subset of the population of concepts interest do not appear in the sample Nonparametric estimation Hypothesis Left truncation testing in a nonparametric ⋄ Occurs often in studies where a subject must first meet setting a particular condition before he/she can enter in the Proportional hazards study and followed up for the event of interest models ⇒ Subjects that experience the event of interest before Parametric survival the condition is met, will not appear in the study models ⋄ Data : ( T , L ) observed if T ≥ L , with T = survival time L = left truncation time
Basic concepts Nonparametric ⋄ Ex : Left truncation in HIV study estimation • Incubation period between HIV infection and Hypothesis testing in a seroconversion nonparametric setting • An individual is considered to have been infected with Proportional HIV only after seroconversion hazards models ⇒ If we study HIV infected individuals and follow them Parametric for survival, all subjects that died between HIV infection survival and seroconversion will not be considered for inclusion models in the study
Right truncation Basic concepts ⋄ Occurs when only subjects who have experienced the Nonparametric event of interest are included in the sample estimation ⋄ Data : ( T , R ) observed if T ≤ R , with Hypothesis testing in a nonparametric T = survival time setting R = right truncation time Proportional hazards ⋄ Ex : Right truncation in AIDS study models • Consider time between HIV seroconversion and Parametric survival development of AIDS models • Often use a sample of AIDS patients, and ascertain retrospectively time of HIV infection ⇒ Patients with long incubation time will not be part of the sample, nor patients that die from another cause before they develop AIDS
Basic concepts Nonparametric Remark estimation Hypothesis ⋄ Censoring : testing in a nonparametric At least some information is available for a ‘complete’ setting random sample of the population Proportional hazards models ⋄ Truncation : Parametric No information at all is available for a subset of the survival models population
Basic concepts Nonparametric estimation Hypothesis testing in a nonparametric Nonparametric estimation setting Proportional hazards models Parametric survival models
We will develop nonparametric estimators of the Basic ⋄ survival function concepts ⋄ cumulative hazard function Nonparametric estimation ⋄ hazard rate Hypothesis testing in a for censored and truncated data nonparametric setting Proportional All these estimators will be based on the nonparametric hazards models likelihood function : Parametric ⋄ Different from the likelihood for completely observed survival models data due to the presence of censoring and truncation ⋄ We will derive the likelihood function for : • right censored data • any type of censored data (right, left and interval censoring) • truncated data
Likelihood for randomly right censored data Basic concepts ⋄ Random sample of individuals of size n : Nonparametric estimation T 1 , . . . , T n survival time Hypothesis C 1 , . . . , C n censoring time testing in a nonparametric ⇒ Observed data : ( Y i , δ i ) ( i = 1 , . . . , n ) with setting Y i = min ( T i , C i ) Proportional hazards models δ i = I ( T i ≤ C i ) Parametric ⋄ Denote survival models f ( · ) and F ( · ) for the density and distribution of T g ( · ) and G ( · ) for the density and distribution of C and we assume that T and C are independent (called independent censoring)
Contribution to the likelihood of an event ( y i = t i , δ i = 1) : Basic concepts 1 lim 2 ǫ P ( y i − ǫ < Y < y i + ǫ, δ = 1 ) Nonparametric ǫ → 0 estimation > Hypothesis 1 testing in a = lim 2 ǫ P ( y i − ǫ < T < y i + ǫ, T ≤ C ) nonparametric ǫ → 0 setting > Proportional y i + ǫ ∞ hazards 1 � � models = lim dG ( c ) dF ( t ) (due to independence) 2 ǫ Parametric ǫ → 0 survival > y i − ǫ t models y i + ǫ 1 � = lim ( 1 − G ( t )) dF ( t ) 2 ǫ ǫ → 0 > y i − ǫ = ( 1 − G ( y i )) f ( y i )
Contribution to the likelihood of a right censored observation Basic concepts ( y i = c i , δ i = 0) : Nonparametric estimation 1 lim 2 ǫ P ( y i − ǫ < Y < y i + ǫ, δ = 0 ) Hypothesis ǫ → 0 testing in a > nonparametric setting 1 = lim 2 ǫ P ( y i − ǫ < C < y i + ǫ, T > C ) Proportional ǫ → 0 hazards > models = ( 1 − F ( y i )) g ( y i ) Parametric survival models This leads to the following formula of the likelihood : n � δ i � � 1 − δ i � � ( 1 − G ( y i )) f ( y i ) ( 1 − F ( y i )) g ( y i ) i = 1
Basic concepts We assume that the censoring is uninformative, i.e. the Nonparametric distribution of the censoring times does not depend on the estimation parameters of interest related to the survival function. Hypothesis testing in a nonparametric ⇒ The factors ( 1 − G ( y i )) δ i and g ( y i ) 1 − δ i are setting Proportional non-informative for inference on the survival function hazards models ⇒ They can be removed from the likelihood, leading to Parametric survival n n models � f ( y i ) δ i S ( y i ) 1 − δ i = � h ( y i ) δ i S ( y i ) i = 1 i = 1
Basic concepts Nonparametric ⋄ This likelihood can also be written as estimation Hypothesis � � L = f ( y i ) S ( y i ) testing in a nonparametric i ∈ D i ∈ R setting with D the index set of survival times and R the index Proportional hazards set of right censored times models Parametric ⋄ It is straightforward to see that the same survival survival models likelihood is also valid in the case of fixed censoring times (type I and type II)
Likelihood for right, left and/or interval censored data Basic concepts Generalization of the previous likelihood to include right, left Nonparametric estimation and interval censoring : Hypothesis testing in a nonparametric � � � � L = f ( y i ) S ( y i ) ( 1 − S ( y i )) ( S ( l i ) − S ( r i )) , setting i ∈ D i ∈ R i ∈ L i ∈ I Proportional hazards models with Parametric D index set of survival times survival models R index set of right censored times L index set of left censored times I index set of interval censored times (with l i the lower limit and r i the upper limit)
Likelihood for left truncated data Basic Suppose that the survival time T i is left truncated at a i concepts ⇒ We have to consider the conditional distribution of T i Nonparametric estimation given T i ≥ a i : Hypothesis testing in a 1 nonparametric f ( t i | T ≥ a i ) = lim 2 ǫ P ( t i − ǫ < T < t i + ǫ | T ≥ a i ) setting ǫ → 0 > Proportional hazards 1 P ( t i − ǫ < T < t i + ǫ, T ≥ a i ) models = lim 2 ǫ P ( T ≥ a i ) ǫ → 0 Parametric > survival models 1 P ( t i < T < t i + ǫ ) = P ( T ≥ a i ) lim ǫ ǫ → 0 > f ( t i ) = S ( a i )
Basic This leads to the following likelihood, accommodating left concepts truncation and any type of censoring : Nonparametric estimation f ( t i ) S ( t i ) S ( a i ) − S ( t i ) S ( l i ) − S ( r i ) Hypothesis � � � � L = testing in a S ( a i ) S ( a i ) S ( a i ) S ( a i ) nonparametric i ∈ D i ∈ R i ∈ L i ∈ I setting Proportional For right truncated data : hazards models ⋄ Consider the conditional density obtained by replacing Parametric survival S ( a i ) by 1 − S ( b i ) , where b i is the right truncation time models for subject i ⋄ The likelihood function can then be constructed in a similar way
Basic concepts Nonparametric Nonparametric estimation of the survival function estimation ⋄ The survival (or distribution) function is at the basis of Hypothesis testing in a many other quantities (mean, quantiles, ...) nonparametric setting ⋄ The survival function is also useful to identify an Proportional hazards appropriate parametric distribution models ⋄ For estimating the survival function in a nonparametric Parametric survival way, we need to take censoring and truncation into models account
Kaplan-Meier estimator of the survival function Basic ⋄ Kaplan and Meier ( JASA , 1958) concepts Nonparametric ⋄ Nonparametric estimation of the survival function for estimation right censored data Hypothesis testing in a ⋄ Based on the order in which events and censored nonparametric setting observations occur Proportional hazards Notations : models Parametric ⋄ n observations y 1 , . . . , y n with censoring indicators survival δ 1 , . . . , δ n models ⋄ r distinct event times ( r ≤ n ) ⋄ ordered event times : y ( 1 ) , . . . , y ( r ) and corresponding number of events: d ( 1 ) , . . . , d ( r ) ⋄ R ( j ) is the size of the risk set at event time y ( j )
⋄ Log-likelihood for right censored data : Basic n concepts � � � δ i log f ( y i ) + ( 1 − δ i ) log S ( y i ) Nonparametric estimation i = 1 ⋄ Replacing the density function f ( y i ) by S ( y i − ) − S ( y i ) , Hypothesis testing in a yields the nonparametric log-likelihood : nonparametric setting n � � � Proportional log L = δ i log ( S ( y i − ) − S ( y i )) + ( 1 − δ i ) log S ( y i ) hazards models i = 1 ⋄ Aim : finding an estimator ˆ Parametric S ( · ) which maximizes log L survival models ⋄ It can be shown that the maximizer of log L takes the following form : ˆ � S ( t ) = ( 1 − h ( j ) ) , j : y ( j ) ≤ t for some h ( 1 ) , . . . , h ( r )
Basic concepts ⋄ Plugging-in ˆ S ( · ) into the log-likelihood, gives after some Nonparametric algebra : estimation Hypothesis r � � testing in a � � � log L = d ( j ) log h ( j ) + R ( j ) − d ( j ) log ( 1 − h ( j ) ) nonparametric setting j = 1 Proportional ⋄ Using this expression to solve hazards models d log L = 0 Parametric dh ( j ) survival models leads to h ( j ) = d ( j ) ˆ R ( j )
Basic ⋄ Plugging in this estimate ˆ h ( j ) in ˆ S ( t ) = � j : y ( j ) ≤ t ( 1 − h ( j ) ) concepts we obtain : Nonparametric estimation R ( j ) − d ( j ) ˆ � S ( t ) = = Kaplan-Meier estimator Hypothesis R ( j ) testing in a j : y ( j ) ≤ t nonparametric setting ⋄ Step function with jumps at the event times Proportional ⋄ If the largest observation, say y n , is censored : hazards models • ˆ S ( t ) does not attain 0 Parametric • Impossible to estimate S ( t ) consistently beyond y n survival models • Various solutions : - Set ˆ S ( t ) = 0 for t ≥ y n - Set ˆ S ( t ) = ˆ S ( y n ) for t ≥ y n - Let ˆ S ( t ) be undefined for t ≥ y n
Uncensored case When all data are uncensored, the Kaplan-Meier estimator Basic concepts reduces to the empirical distribution function Nonparametric Consider case without ties for simplicity : estimation Hypothesis ⋄ If no censoring, R ( j ) − d ( j ) = R ( j + 1 ) for j = 1 , . . . , r testing in a nonparametric ⋄ We can rewrite the KM estimator as setting Proportional R ( 2 ) R ( 3 ) · · · R ( k + 1 ) hazards ˆ S ( t ) = where y ( k ) ≤ t < y ( k + 1 ) models R ( 1 ) R ( 2 ) R ( k ) Parametric R ( k + 1 ) survival = models R ( 1 ) # subjects with survival time ≥ y ( k + 1 ) = # at risk before first death time n 1 � = I ( y i > t ) n i = 1
Asymptotic normality of the KM estimator ⋄ Asymptotic variance of the KM estimator : Basic concepts � t dH u ( s ) V As (ˆ S ( t )) = n − 1 S 2 ( t ) ( 1 − H ( s ))( 1 − H ( s − )) , Nonparametric estimation 0 Hypothesis where testing in a - H ( t ) = P ( Y ≤ t ) = 1 − S ( t )( 1 − G ( t )) nonparametric setting - H u ( t ) = P ( Y ≤ t , δ = 1 ) Proportional hazards ⋄ This variance can be consistently estimated as models (Greenwood formula) Parametric survival d ( j ) models V As (ˆ ˆ S ( t )) = ˆ � S 2 ( t ) R ( j ) ( R ( j ) − d ( j ) ) j : y ( j ) ≤ t ⋄ Asymptotic normality of ˆ S ( t ) : ˆ S ( t ) − S ( t ) d → N ( 0 , 1 ) � V As (ˆ ˆ S ( t ))
Nelson-Aalen estimator of the cumulative hazard function Basic concepts ⋄ Proposed independently by Nelson ( Technometrics , Nonparametric estimation 1972) and Aalen ( Annals of Statistics , 1978) : Hypothesis d ( j ) ˆ � testing in a H ( t ) = for t ≤ y ( r ) nonparametric R ( j ) setting j : y ( j ) ≤ t Proportional ⋄ Its asymptotic variance can be estimated by hazards models d ( j ) V As ( ˆ ˆ � H ( t )) = Parametric R 2 survival ( j ) j : y ( j ) ≤ t models ⋄ Asymptotic normality : ˆ H ( t ) − H ( t ) d → N ( 0 , 1 ) � V As ( ˆ ˆ H ( t ))
Basic concepts Alternative for KM estimator Nonparametric ⋄ An alternative estimator for S ( t ) can be obtained based estimation Hypothesis on the Nelson-Aalen estimator using the relation testing in a nonparametric S ( t ) = exp ( − H ( t )) , setting Proportional leading to hazards − d ( j ) models � � ˆ � S alt ( t ) = exp Parametric R ( j ) survival j : y ( j ) ≤ t models ⋄ ˆ S ( t ) and ˆ S alt ( t ) are asymptotically equivalent ⋄ ˆ S alt ( t ) performs often better than ˆ S ( t ) for small samples
Basic concepts Example : Survival function for 6 HIV diagnosed patients Nonparametric ⋄ Ordered observed times: 3*, 5*, 6, 12*, 22, 37* estimation Hypothesis ⋄ Only two contributions to KM and NA estimator : testing in a nonparametric setting Event time Proportional 6 22 hazards Number of events d ( j ) 1 1 models Number at risk R ( j ) 4 2 Parametric KM contribution 1 − d ( j ) / R ( j ) 3/4 1/2 survival ˆ models KM estimator S ( y ( j ) ) 3/4=0.75 3/8=0.375 NA contribution exp ( − d ( j ) / R ( j ) ) 0.7788 0.6065 NA estimator � j : y ( j ) ≤ t exp ( − d ( j ) / R ( j ) ) 0.7788 0.4723
Basic concepts 1.0 Nonparametric estimation Hypothesis 0.8 testing in a nonparametric setting Estimated survival 0.6 Proportional hazards models 0.4 Parametric survival models 0.2 Kaplan−Meier Nelson−Aalen 0.0 0 5 10 15 20 25 30 35 Time
Basic concepts Confidence intervals for the survival function Nonparametric estimation ⋄ From the asymptotic normality of ˆ S ( t ) , a 100 ( 1 − α )% Hypothesis confidence interval (CI) for S ( t ) ( t fixed) is given by : testing in a nonparametric setting � ˆ V As (ˆ ˆ S ( t ) ± z α/ 2 S ( t )) Proportional hazards models ⋄ However, this CI may contain points outside the [ 0 , 1 ] Parametric survival interval models ⇒ Use an appropriate transformation to determine the CI on the transformed scale and then transform back
⋄ A popular transformation is log ( − log S ( t )) , which takes Basic values between −∞ and ∞ . concepts Nonparametric ⋄ One can show that estimation log ( − log ˆ S ( t )) − log ( − log S ( t )) d Hypothesis → N ( 0 , 1 ) , testing in a � ˆ log ( − log ˆ � � V As S ( t )) nonparametric setting where Proportional d ( j ) hazards 1 ˆ log ( − log ˆ � models � � V As S ( t )) = log ˆ � 2 R ( j ) ( R ( j ) − d ( j ) ) � S ( t ) Parametric j : y ( j ) ≤ t survival models ⋄ Hence, CI for log ( − log S ( t )) is given by � log ( − log ˆ ˆ log ( − log ˆ � � S ( t )) ± z α/ 2 V As S ( t )) ⋄ By transforming back, we get the following CI for S ( t ) : � � � � � ˆ log ( − log ˆ exp ± z α/ 2 V As S ( t )) ˆ S ( t )
Point estimate of the mean survival time ⋄ Nonparametric estimator can be obtained using the Basic Kaplan-Meier estimator, since concepts � ∞ � ∞ Nonparametric µ = E ( T ) = xf ( x ) dx = S ( x ) dx estimation 0 0 Hypothesis ⇒ We can estimate µ by replacing S ( x ) by the KM testing in a nonparametric estimator ˆ S ( x ) setting ⋄ But, ˆ Proportional S ( t ) is inconsistent in the right tail if the largest hazards observation (say y n ) is censored models • Proposal 1 : assume y n experiences the event Parametric survival immediately after the censoring time : models � y n ˆ µ y n = ˆ S ( t ) dt 0 • Proposal 2 : restrict integration to a predetermined interval [ 0 , t max ] and consider ˆ S ( t ) = ˆ S ( y n ) for y n ≤ t ≤ t max : � t max ˆ µ t max = ˆ S ( t ) dt 0
Basic concepts ⋄ ˆ µ y n and ˆ µ t max are inconsistent estimators of µ , but given Nonparametric estimation the lack of data in the right tail, we cannot do better (at Hypothesis least not nonparametrically) testing in a nonparametric ⋄ Variance of ˆ µ τ (with τ either y n or t max ) : setting � 2 �� τ Proportional r d ( j ) hazards ˆ � ˆ V As (ˆ µ τ ) = S ( t ) dt models R ( j ) ( R ( j ) − d ( j ) ) y ( j ) j = 1 Parametric survival ⋄ A 100 ( 1 − α )% CI for µ is given by : models � ˆ µ τ ± z α/ 2 ˆ V As (ˆ µ τ )
Point estimate of the median survival time Basic ⋄ Advantages of the median over the mean : concepts • As survival function is often skewed to the right, the Nonparametric mean is often influenced by outliers, whereas the estimation median is not Hypothesis testing in a • Median can be estimated in a consistent way (if nonparametric setting censoring is not too heavy) Proportional ⋄ An estimator of the p th quantile x p is given by : hazards models � � t | ˆ ˆ x p = inf S ( t ) ≤ 1 − p Parametric survival ⇒ An estimate of the median is given by ˆ models x p = 0 . 5 ⋄ Asymptotic variance of ˆ x p : V As (ˆ ˆ S ( x p )) ˆ V As (ˆ x p ) = , ˆ f 2 ( x p ) where ˆ f is an estimator of the density f
⋄ Estimation of f involves smoothing techniques and the Basic concepts choice of a bandwidth sequence Nonparametric ⇒ We prefer not to use this variance estimator in the estimation construction of a CI Hypothesis testing in a ⋄ Thanks to the asymptotic normality of ˆ nonparametric S ( x p ) : setting ˆ S ( x p ) − S ( x p ) Proportional � � P − z α/ 2 ≤ ≤ z α/ 2 ≈ 1 − α, hazards � models V As (ˆ ˆ S ( x p )) Parametric survival with obviously S ( x p ) = 1 − p . models ⇒ A 100 ( 1 − α )% CI for x p is given by ˆ S ( t ) − ( 1 − p ) t : − z α/ 2 ≤ ≤ z α/ 2 � V As (ˆ ˆ S ( t ))
Example : Schizophrenia patients Basic ⋄ Schizophrenia is one of the major mental illnesses concepts Nonparametric encountered in Ethiopia estimation → disorganized and abnormal thinking, behavior and Hypothesis testing in a language + emotionally unresponsive nonparametric setting → higher mortality rates due to natural and unnatural Proportional hazards causes models ⋄ Project on schizophrenia in Butajira, Ethiopia Parametric survival models → survey of the entire population (68491 individuals) in the age group 15-49 years ⇒ 280 cases of schizophrenia identified and followed for 5 years (1997-2001)
Basic Table: Data on schizophrenia patients concepts Nonparametric estimation Patid Time Censor Education Onset Marital Gender Age Hypothesis testing in a 1 1 1 1 37 3 1 44 nonparametric setting 2 3 1 3 15 2 2 23 Proportional 3 4 1 6 26 1 1 33 hazards models 4 5 1 12 25 1 1 31 Parametric survival 5 5 0 5 29 3 1 33 models . . . 278 1787 0 2 16 2 1 18 279 1792 0 2 23 1 1 25 280 1794 1 2 28 1 1 35
⋄ In R : survfit Basic concepts schizo<-read.table("c://...//Schizophrenia.csv", Nonparametric header=T,sep=";") estimation KM_schizo_l<-survfit(Surv(Time,Censor) ∼ 1,data=schizo, Hypothesis type="kaplan-meier", conf.type="log-log") testing in a plot(KM_schizo_l, conf.int=T, xlab="Estimated survival", nonparametric setting ylab="Time", yscale=1) mtext("Kaplan-Meier estimate of the survival function Proportional for Schizophrenic patients", 3,-3) hazards models mtext("(confidence interval based on log-log transformation)", 3,-4) Parametric survival models ⋄ In SAS : proc lifetest title1 ’Kaplan-Meier estimate of the survival function for Schizophrenic patients’; proc lifetest method=km width=0.5 data=schizo; time Time*Censor(0); run;
Basic concepts 1.0 Nonparametric Kaplan−Meier estimate of the survival function for Schizophrenic patients estimation (confidence interval based on log−log transformation) Hypothesis 0.8 testing in a nonparametric setting 0.6 Proportional Time hazards models 0.4 Parametric survival models 0.2 0.0 0 500 1000 1500 Estimated survival
Basic concepts > KM_schizo_l Nonparametric Call: survfit(formula = Surv(Time, Censor) ~ 1, data = schizo, type = estimation "kaplan-meier", conf.type = "log-log") Hypothesis n events median 0.95LCL 0.95UCL testing in a 280 163 933 757 1099 nonparametric setting > summary(KM_schizo_l) Proportional Call: survfit(formula = Surv(Time, Censor) ~ 1, data = schizo, type = hazards "kaplan-meier", conf.type = "log-log") models time n.risk n.event survival std.err lower 95% CI upper 95% CI Parametric 1 280 1 0.996 0.00357 0.9749 0.999 3 279 1 0.993 0.00503 0.9717 0.998 survival 4 277 1 0.989 0.00616 0.9671 0.997 models … 1770 13 1 0.219 0.03998 0.1465 0.301 1773 12 1 0.201 0.04061 0.1283 0.285 1784 8 2 0.151 0.04329 0.0782 0.245 1785 6 2 0.100 0.04092 0.0387 0.197 1794 1 1 0.000 NA NA NA
Basic concepts 1.0 Nonparametric Kaplan−Meier estimate of the survival function for Schizophrenic patients estimation (confidence interval based on Greenwood formula) Hypothesis 0.8 testing in a nonparametric setting 0.6 Proportional Time hazards models 0.4 Parametric survival models 0.2 0.0 0 500 1000 1500 Estimated survival
Basic concepts > KM_schizo_g Nonparametric Call: survfit(formula = Surv(Time, Censor) ~ 1, data = schizo, type = estimation "kaplan-meier", conf.type = "plain") Hypothesis n events median 0.95LCL 0.95UCL testing in a 280 163 933 766 1099 nonparametric setting > summary(KM_schizo_g) Call: survfit(formula = Surv(Time, Censor) ~ 1, data = schizo, type = Proportional "kaplan-meier", conf.type = "plain") hazards models time n.risk n.event survival std.err lower 95% CI upper 95% CI 1 280 1 0.996 0.00357 0.9894 1.000 Parametric 3 279 1 0.993 0.00503 0.9830 1.000 4 277 1 0.989 0.00616 0.9772 1.000 survival … models 1770 13 1 0.219 0.03998 0.1409 0.298 1773 12 1 0.201 0.04061 0.1214 0.281 1784 8 2 0.151 0.04329 0.0659 0.236 1785 6 2 0.100 0.04092 0.0203 0.181 1794 1 1 0.000 NA NA NA
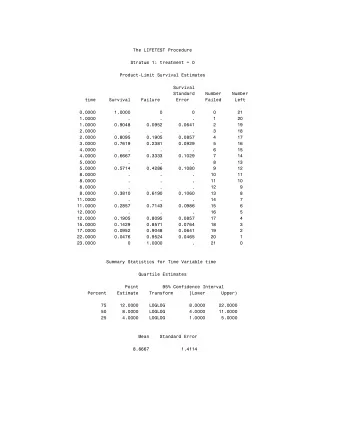
Basic concepts Nonparametric ⋄ Median survival time is estimated to be 933 days estimation ⋄ 95% CI for the median : [757, 1099] Hypothesis testing in a nonparametric ⋄ Survival at, e.g., 505 days is estimated to be 0.6897 setting with std error 0.0290 Proportional hazards ⋄ 95% CI for S ( 505 ) : [0.6329, 0.7465] (without models transformation) Parametric survival models ⋄ 95% CI for S ( 505 ) : [0.6290, 0.7426] (using log-log transformation)
Estimation of the survival function for left truncated and right Basic concepts censored data Nonparametric estimation ⋄ We need to redefine R ( j ) : Hypothesis R ( j ) = number of individuals at risk at time y ( j ) testing in a nonparametric setting and under observation prior to time y ( j ) Proportional = # { i : l i ≤ y ( j ) ≤ y i } , hazards models where l i is the truncation time. Parametric survival ⋄ We cannot estimate S ( t ) , but only a conditional survival models function S l ( t ) = P ( T ≥ t | T ≥ l ) for some fixed value l ≥ min ( l 1 , . . . , l n )
Basic concepts Nonparametric estimation ⋄ The conditional survival function S l ( t ) is estimated by Hypothesis testing in a nonparametric � 1 if t < l setting ˆ S l ( t ) = � d ( j ) � Proportional � 1 − if t ≥ l j : l ≤ y ( j ) ≤ t R ( j ) hazards models ⋄ Proposed and named after Lynden-Bell (1971), an Parametric survival astronomer models
Estimation of the hazard function for right censored data ⋄ Usually more informative about the underlying Basic concepts population than the survival or the cumulative hazard Nonparametric function estimation Hypothesis ⋄ Crude estimator : take the size of the jumps of the testing in a nonparametric cumulative hazard function setting ⋄ Ex : Crude estimator of the hazard function for data on Proportional hazards schizophrenic patients models Parametric 0.015 survival models 0.010 Hazard estimate 0.005 0.000 0 200 400 600 800 1000 Time (in days)
⋄ Smoothed estimator of h ( t ) : (weighted) average of the Basic crude estimator over all time points in the interval concepts [ t − b , t + b ] for a certain value b , called the bandwidth Nonparametric estimation ⋄ Uniform weight over interval [ t − b , t + b ] : Hypothesis testing in a r nonparametric ˆ � ∆ ˆ h ( t ) = ( 2 b ) − 1 � � I − b ≤ t − y ( j ) ≤ b H ( y ( j ) ) , setting j = 1 Proportional hazards where models - ˆ H ( t ) = Nelson-Aalen estimator Parametric survival - ∆ ˆ H ( y ( j ) ) = ˆ H ( y ( j ) ) − ˆ H ( y ( j − 1 ) ) models ⋄ General weight function : r � t − y ( j ) � ˆ � ∆ ˆ h ( t ) = b − 1 K H ( y ( j ) ) , b j = 1 where K ( · ) is a density function, called the kernel
⋄ Example of kernels : Name Density function Support Basic concepts K ( x ) = 1 − 1 ≤ x ≤ 1 uniform 2 Nonparametric K ( x ) = 3 4 ( 1 − x 2 ) Epanechnikov − 1 ≤ x ≤ 1 estimation K ( x ) = 15 Hypothesis 16 ( 1 − x 2 ) 2 biweight − 1 ≤ x ≤ 1 testing in a nonparametric setting Proportional ⋄ Ex : Smoothed estimator of the hazard function for data hazards models on schizophrenic patients Parametric survival 1e−03 models 8e−04 6e−04 Smoothed hazard 4e−04 2e−04 Uniform Epanechnikov 0e+00 0 200 400 600 800 1000 Time
Basic concepts ⋄ The choice of the kernel does not have a major impact Nonparametric on the estimated hazard rate, but the choice of the estimation bandwidth does Hypothesis testing in a ⇒ It is important to choose the bandwidth in an nonparametric setting appropriate way, by e.g. plug-in, cross-validation, Proportional bootstrap, ... techniques hazards models ⋄ Variance of ˆ h ( t ) can be estimated by Parametric survival r � 2 � t − y ( j ) models V As (ˆ ˆ h ( t )) = b − 2 � ∆ ˆ V As ( ˆ K H ( y ( j ) )) , b j = 1 where ∆ ˆ V As ( ˆ H ( y ( j ) )) = ˆ V As ( ˆ H ( y ( j ) )) − ˆ V As ( ˆ H ( y ( j − 1 ) ))
Basic concepts Nonparametric estimation Hypothesis testing in a Hypothesis testing in a nonparametric setting nonparametric setting Proportional hazards models Parametric survival models
Hypothesis testing in a nonparametric setting Basic ⋄ Hypotheses concerning the hazard function of one concepts Nonparametric population estimation ⋄ Hypotheses comparing the hazard function of two or Hypothesis testing in a more populations nonparametric setting Note that Proportional hazards ⋄ It is important to consider overall differences over time models Parametric ⋄ We will develop tests that look at weighted differences survival models between observed and expected quantities (under H 0 ) ⋄ Weights allow to put more emphasis on certain part of the data (e.g. early or late departure from H 0 ) ⋄ Particular cases : log-rank test, Breslow’s test, Cox Mantel test, Peto and Peto test, ...
Ex : Survival differences in leukemia patients : chemotherapy vs. chemotherapy + autologous Basic transplantation concepts Nonparametric estimation Hypothesis testing in a 1.0 nonparametric setting 0.8 Proportional 0.6 Survival hazards models 0.4 Parametric survival 0.2 Transplant+chemo models Only chemo 0.0 100 200 300 Time (in days)
Hypotheses for the hazard function of one population Basic concepts ⋄ Test whether a censored sample of size n comes from Nonparametric estimation a population with a known hazard function h 0 ( t ) : Hypothesis testing in a H 0 : h ( t ) = h 0 ( t ) for all t ≤ y ( r ) nonparametric setting H 1 : h ( t ) � = h 0 ( t ) for some t ≤ y ( r ) Proportional hazards ⋄ Based on the NA estimator of the cumulative hazard models function, a crude estimator of the hazard function at Parametric survival time y ( j ) is models d ( j ) R ( j ) ⋄ Under H 0 , the hazard function at time y ( j ) is h 0 ( y ( j ) )
⋄ Let w ( t ) be some weight function, with w ( t ) = 0 for Basic concepts t > y ( r ) Nonparametric ⋄ Test statistic : estimation � y ( r ) r w ( y ( j ) ) d ( j ) Hypothesis � Z = − w ( s ) h 0 ( s ) ds testing in a R ( j ) nonparametric 0 j = 1 setting ⋄ Under H 0 : Proportional � y ( r ) hazards w 2 ( s ) h 0 ( s ) models V ( Z ) = R ( s ) ds Parametric 0 survival with R ( s ) corresponding to the number of subjects in models the risk set at time s ⋄ For large samples : Z ≈ N ( 0 , 1 ) � V ( Z )
One sample log-rank test ⋄ Weight function : w ( t ) = R ( t ) Basic concepts ⋄ Test statistic : � y ( r ) r Nonparametric estimation � Z = d ( j ) − R ( s ) h 0 ( s ) ds Hypothesis 0 j = 1 testing in a nonparametric � y i r n setting � � = d ( j ) − h 0 ( s ) ds Proportional 0 hazards j = 1 i = 1 models r n � � Parametric = d ( j ) − H 0 ( y i ) = O − E survival models j = 1 i = 1 ⋄ Under H 0 : � y ( r ) V ( Z ) = R ( s ) h 0 ( s ) ds = E 0 and O − E √ ≈ N ( 0 , 1 ) E
Basic Example : Survival in patients with Paget disease concepts ⋄ Benign form of breast cancer Nonparametric estimation ⋄ Compare survival in a sample of patients to the survival Hypothesis in the overall population testing in a nonparametric • Data : Finkelstein et al. (2003) setting • Hazard function of the population : standardized Proportional hazards actuarial table models ⋄ Compute the expected number of deaths under H 0 Parametric survival using models • follow-up information of the group of patients with Paget disease • relevant hazard function from standardized actuarial table
Paget disease data: ⋄ age (in years) at diagnosis Basic concepts ⋄ time to death or censoring (in years) Nonparametric ⋄ censoring indicator estimation Hypothesis ⋄ gender (1=male, 2=female) testing in a nonparametric ⋄ race (1=Caucasian, 2=black) setting Proportional hazards Age Follow-up Status Gender Race models Parametric 52 22 0 2 1 survival 53 4 0 2 1 models 57 8 0 2 1 57 7 0 2 1 ... 85 6 1 2 1 86 1 0 2 1
Standardized actuarial table : ⋄ age (in years) Basic concepts ⋄ hazard (per 100 subjects) for respectively Caucasian Nonparametric males, Caucasian females, black males, and black estimation Hypothesis females testing in a nonparametric setting Hazard function Proportional Age Caucasian Caucasian black black hazards models male female male female Parametric survival 50-54 0.6070 0.3608 1.3310 0.7156 models 55-59 0.9704 0.5942 1.9048 1.0558 60-64 1.5855 0.9632 2.8310 1.6048 ... 80-84 9.3128 6.2880 10.4625 7.2523 85- 17.7671 14.6814 16.0835 13.7017
Basic concepts ⋄ E.g. first patient : Caucasian female followed from 52 Nonparametric estimation years on for 22 years : Hypothesis hazard for the 52 th year testing in a (1) = 0.3608 nonparametric hazard for the 53 th year setting (2) = 0.3608 Proportional ... ... ... hazards models hazard for the 73 th year (22) = 2.3454 Parametric Total (cumulative hazard) = 25.637 survival models ⇒ for one particular patient (/100) = 0.25637 and do the same for all patients
Basic concepts Nonparametric ⋄ Expected number of deaths under H 0 : E = 9 . 55 estimation Hypothesis ⋄ Observed number of deaths : O = 13 testing in a nonparametric ⋄ Test statistic : setting O − E = 13 − 9 . 55 Proportional √ √ = 1 . 116 hazards E 9 . 55 models ⋄ Two-sided hypothesis test : Parametric survival 2 P ( Z > 1 . 116 ) = 0 . 264 models ⇒ We do not reject H 0
Basic Other weight functions concepts Weight function proposed by Harrington and Fleming Nonparametric estimation (1982): Hypothesis testing in a w ( t ) = R ( t ) S p 0 ( t )( 1 − S 0 ( t )) q p , q ≥ 0 nonparametric setting Proportional ⋄ p = q = 0 : log-rank test hazards models ⋄ p > q : more weight on early deviations from H 0 Parametric survival ⋄ p < q : more weight on late deviations from H 0 models ⋄ p = q > 0 : more weight on deviations in the middle ⋄ p = 1 , q = 0 : generalization of the one-sample Wilcoxon test to censored data
Basic Comparing the hazard functions of two populations concepts ⋄ Hypothesis test : Nonparametric estimation H 0 : h 1 ( t ) = h 2 ( t ) for all t ≤ y ( r ) Hypothesis testing in a H 1 : h 1 ( t ) � = h 2 ( t ) for some t ≤ y ( r ) nonparametric setting ⋄ Notations : Proportional hazards • y ( 1 ) , y ( 2 ) , . . . , y ( r ) : ordered event times in the pooled models sample Parametric • d ( j ) k : number of events at time y ( j ) in sample k survival models ( j = 1 , . . . , r and k = 1 , 2) • R ( j ) k : number of individuals at risk at time y ( j ) in sample k • d ( j ) = � 2 k = 1 d ( j ) k and R ( j ) = � 2 k = 1 R ( j ) k
⋄ Derive a 2 × 2 contingency table for each event time y ( j ) : Basic concepts Group Event No Event Total Nonparametric estimation 1 d ( j ) 1 R ( j ) 1 − d ( j ) 1 R ( j ) 1 Hypothesis 2 d ( j ) 2 R ( j ) 2 − d ( j ) 2 R ( j ) 2 testing in a nonparametric Total d ( j ) R ( j ) − d ( j ) R ( j ) setting Proportional ⋄ Test the independence between the rows and the hazards models columns, which corresponds to the assumption that the Parametric hazard in the two groups at time y ( j ) is the same survival models ⋄ Test statistic with group 1 as reference group : O j − E j = d ( j ) 1 − d ( j ) R ( j ) 1 R ( j ) with O j = observed number of events in the first group E j = expected number of events in the first group assuming that h 1 ≡ h 2
Basic ⋄ Test statistic : weighted average over the different event concepts times : Nonparametric r estimation � U = w ( y ( j ) )( O j − E j ) Hypothesis testing in a j = 1 nonparametric setting r d ( j ) 1 − d ( j ) R ( j ) 1 � � � = w ( y ( j ) ) Proportional R ( j ) hazards j = 1 models Parametric Different weights can be used, but choice must be survival models made before looking at the data ⋄ For large samples and under the null hypothesis : U ≈ N ( 0 , 1 ) � V ( U )
Basic concepts Variance of U : Nonparametric ⋄ Can be obtained by observing that conditional on d ( j ) , estimation R ( j ) 1 and R ( j ) , the statistic d ( j ) 1 has a hypergeometric Hypothesis testing in a distribution nonparametric setting ⋄ Hence, Proportional hazards r models � w 2 ( y ( j ) ) V ( d ( j ) 1 ) V ( U ) = Parametric j = 1 survival � R ( j ) 1 models �� R ( j ) 1 � r d ( j ) 1 − ( R ( j ) − d ( j ) ) R ( j ) R ( j ) � w 2 ( y ( j ) ) = R ( j ) − 1 j = 1
Basic Weights : concepts ⋄ w ( y ( j ) ) = 1 Nonparametric estimation ֒ → log-rank test Hypothesis ֒ → optimum power to detect alternatives when the hazard testing in a nonparametric rates in the two populations are proportional to each setting other Proportional hazards models ⋄ w ( y ( j ) ) = R ( j ) Parametric ֒ → generalization by Gehan (1965) of the two sample survival models Wilcoxon test ֒ → puts more emphasis on early departures from H 0 ֒ → weights depend heavily on the event times and the censoring distribution
⋄ w ( y ( j ) ) = f ( R ( j ) ) Basic ֒ → Tarone and Ware (1977) concepts → a suggested choice is f ( R ( j ) ) = � R ( j ) ֒ Nonparametric ֒ → puts more weight on early departures from H 0 estimation Hypothesis � d ( k ) � testing in a ⋄ w ( y ( j ) ) = ˆ S ( y ( j ) ) = � 1 − nonparametric y ( k ) ≤ y ( j ) R ( k ) + 1 setting ֒ → Peto and Peto (1972) and Kalbfleisch and Prentice Proportional (1980) hazards models ֒ → based on an estimate of the common survival function Parametric close to the pooled product limit estimate survival models � p � � q � ˆ 1 − ˆ ⋄ w ( y ( j ) ) = S ( y ( j − 1 ) ) S ( y ( j − 1 ) ) p ≥ 0 , q ≥ 0 ֒ → Fleming and Harrington (1981) ֒ → include weights of the log-rank as special case ֒ → q = 0 , p > 0 : more weight is put on early differences ֒ → p = 0 , q > 0 : more weight is put on late differences
Example : Comparing survival for male and female schizophrenic patients Basic concepts Nonparametric estimation Hypothesis 1 testing in a nonparametric setting 0.8 Proportional hazards Estimated survival 0.6 models Parametric survival 0.4 Male models Female 0.2 0 0 500 1000 1500 2000 Time
Basic concepts Nonparametric ⋄ Observed number of events in female group : 93 estimation Hypothesis ⋄ Expected number of events under H 0 : 62 testing in a nonparametric ⋄ Log-rank weights : setting � • U / V ( U ) = 4 . 099 Proportional hazards • p -value (2-sided) = 0.000042 models ⋄ Peto and Peto weights : Parametric survival � • U / V ( U ) = 4 . 301 models • p -value (2-sided) = 0.000017
Comparing the hazard functions of more than 2 populations ⋄ Hypothesis test : Basic concepts H 0 : h 1 ( t ) = h 2 ( t ) = . . . = h l ( t ) for all t ≤ y ( r ) Nonparametric estimation H 1 : h i ( t ) � = h j ( t ) for at least one pair ( i , j ) Hypothesis for some t ≤ y ( r ) testing in a nonparametric ⋄ Notations : same as earlier but now k = 1 , . . . , l setting Proportional ⋄ Test statistic based on the l × 2 contingency tables for hazards models the different event times y ( j ) Parametric survival Group Event No Event Total models 1 d ( j ) 1 R ( j ) 1 − d ( j ) 1 R ( j ) 1 2 d ( j ) 2 R ( j ) 2 − d ( j ) 2 R ( j ) 2 . . . l d ( j ) l R ( j ) l − d ( j ) l R ( j ) l Total d ( j ) R ( j ) − d ( j ) R ( j )
⋄ The random vector d ( j ) = ( d ( j ) 1 , . . . , d ( j ) l ) t has a multivariate hypergeometric distribution Basic concepts ⋄ We can define analogues of the test statistic U defined Nonparametric estimation previously : Hypothesis r d ( j ) k − d ( j ) R ( j ) k testing in a � � � U k = w ( y ( j ) ) , nonparametric R ( j ) setting j = 1 Proportional which is a weighted sum of the differences between the hazards models observed and expected number of events under H 0 Parametric survival ⋄ The components of the vector ( U 1 , . . . , U l ) are linearly models dependent because � l k = 1 U k = 0 ⇒ define U = ( U 1 , . . . , U l − 1 ) t ⇒ derive V ( U ) , the variance-covariance matrix of U ⋄ For large sample size and under H 0 : U t V ( U ) − 1 U ≈ χ 2 l − 1
Example : Comparing survival for schizophrenic patients according to their marital status Basic concepts Nonparametric estimation 1 Hypothesis Single Married testing in a Again alone nonparametric 0.8 setting Proportional hazards 0.6 Estimated survival models Parametric survival 0.4 models 0.2 0 0 500 1000 1500 2000 Time
Basic concepts Nonparametric estimation Hypothesis ⋄ Observed number of events : 55 (single), 37 (married), testing in a 71 (alone again) nonparametric setting ⋄ Expected number of events under H 0 : 67, 55, 41 Proportional hazards ⋄ Test statistic : U t V ( U ) − 1 U = 31 . 44 models ⋄ p -value = 1 . 5 × 10 − 7 (based on a χ 2 Parametric 2 ) survival models
Test for trend Basic concepts ⋄ Sometimes there exists a natural ordering in the hazard Nonparametric functions estimation Hypothesis ⋄ If such an ordering exists, tests that take it into testing in a nonparametric consideration have more power to detect significant setting effects Proportional hazards ⋄ Test for trend : models Parametric H 0 : h 1 ( t ) = h 2 ( t ) = . . . = h l ( t ) for all t ≤ y ( r ) survival models H 1 : h 1 ( t ) ≤ h 2 ( t ) ≤ . . . ≤ h l ( t ) for some t ≤ y ( r ) with at least one strict inequality ( H 1 implies that S 1 ( t ) ≥ S 2 ( t ) ≥ . . . ≥ S l ( t ) for some t ≤ y ( r ) with at least one strict inequality)
⋄ Test statistic for trend : l Basic � U = w k U k , concepts k = 1 Nonparametric estimation with Hypothesis • U k the summary statistic of the k th population testing in a • w k the weight assigned to the k th population, e.g. nonparametric setting w k = k (corresponds to a linear trend in the groups) Proportional hazards ⋄ Variance of U : models l l Parametric � � V ( U ) = w k w k ′ Cov ( U k , U k ′ ) survival models k ′ = 1 k = 1 ⋄ For large sample size and under H 0 : U ≈ N ( 0 , 1 ) � V ( U ) � ⋄ If w k = k , we reject H 0 for large values of U / V ( U ) (one-sided test)
Example : Comparing survival for schizophrenic patients according to their educational level Basic concepts 4 educational groups : none, low, medium, high Nonparametric estimation Hypothesis testing in a 1 None nonparametric Low Medium setting High 0.8 Proportional hazards models 0.6 Estimated survival Parametric survival models 0.4 0.2 0 0 500 1000 1500 2000 Time
Basic concepts ⋄ Observed number of events : 79 (none), 43 (low), 32 Nonparametric (medium), 9 (high) estimation Hypothesis ⋄ Expected number of events under H 0 : 71.3, 51.6, 31.1, testing in a nonparametric 9.0 setting ⋄ Consider H 1 : h 1 ( t ) ≥ . . . ≥ h 4 ( t ) Proportional hazards models ⋄ Using weights 0, 1, 2, 3 we have : Parametric � • U = − 6 . 77 and V ( U ) = 134 so U / V ( U ) = − 0 . 58 survival • One-sided p -value : models P ( Z < − 0 . 58 ) = 0 . 28 ⋄ p -value for ‘global test’ : p = 0 . 49
Stratified tests Basic ⋄ In some cases, subjects in a study can be grouped concepts according to particular characteristics, called strata Nonparametric estimation Ex : prognosis group (good, average, poor) Hypothesis ⋄ It is often advisable to adjust for strata as it reduces testing in a nonparametric variance setting ⇒ Stratified test : obtain an overall assessment of the Proportional hazards difference, by combining information over the different models Parametric strata to gain power survival models ⋄ Hypothesis test : H 0 : h 1 b ( t ) = h 2 b ( t ) = . . . = h lb ( t ) for all t ≤ y ( r ) and b = 1 , . . . , m , where h kb ( · ) is the hazard of group k and stratum b ( k = 1 , . . . , l ; b = 1 , . . . , m )
⋄ Test statistic : Basic • U kb = summary statistic for population k ( k = 1 , . . . , l ) in concepts stratum b ( b = 1 , . . . , m ) Nonparametric • Stratified summary statistic for population k : estimation U k . = � m b = 1 U kb Hypothesis testing in a • Define U . = ( U 1 . , . . . , U ( l − 1 ) . ) t nonparametric setting ⋄ Entries of the variance-covariance matrix V ( U ) of U . : Proportional m hazards � models Cov ( U k . , U k ′ . ) = Cov ( U kb , U k ′ b ) Parametric b = 1 survival ⋄ For large sample size and under H 0 : models U t . V ( U ) − 1 U . ≈ χ 2 l − 1 ⋄ If only two populations : � m b = 1 U b ≈ N ( 0 , 1 ) �� m b = 1 V ( U b )
Example : Comparing survival for schizophrenic patients according to gender stratified by marital status Basic concepts Nonparametric estimation 1 Male Estimated survival Female Hypothesis 0.6 testing in a 0.2 nonparametric 0 setting 0 500 1000 1500 2000 Time Proportional hazards b 1 models Estimated survival 0.6 Parametric 0.2 survival 0 models 0 500 1000 1500 2000 Time 1 Estimated survival 0.6 0.2 0 0 500 1000 1500 2000 Time
Basic ⋄ Log-rank test (weights=1) : concepts Nonparametric single married alone again estimation U b 5.81 5.98 6.06 Hypothesis testing in a V ( U b ) 9.77 4.12 15.71 nonparametric setting ⋄ � 3 b = 1 U b = 17 . 85 and � 3 Proportional b = 1 V ( U b ) = 29 . 60 hazards models ⋄ Test statistic : Parametric survival � 3 √ b = 1 U b models = 10 . 76 �� 3 b = 1 V ( U b ) ⋄ p -value (2-sided) = 0.00103
Basic concepts Matched pairs test Nonparametric estimation ⋄ Particular case of the stratified test when each stratum Hypothesis consists of only 2 subjects testing in a nonparametric setting ⋄ m matched pairs of censored data : ( y 1 b , y 2 b , δ 1 b , δ 2 b ) for b = 1 , . . . , m , with Proportional hazards • 1 st subject of the pair receiving treatment 1 models • 2 nd subject of the pair receiving treatment 2 Parametric survival models ⋄ Hypothesis test : H 0 : h 1 b ( t ) = h 2 b ( t ) for all t ≤ y ( r ) and b = 1 , . . . , m
Basic concepts Nonparametric ⋄ It can be shown that under H 0 and for large m : estimation Hypothesis testing in a D 1 − D 2 U . √ D 1 + D 2 nonparametric = ≈ N ( 0 , 1 ) , setting � V ( U . ) Proportional hazards models where D j = number of matched pairs in which the Parametric individual from sample j dies first ( j = 1 , 2) survival models ⇒ Weight function has no effect on final test statistic in this case
Basic concepts Nonparametric estimation Hypothesis testing in a nonparametric Proportional hazards models setting Proportional hazards models Parametric survival models
Basic The semiparametric proportional hazards model concepts Nonparametric ⋄ Cox, 1972 estimation ⋄ Stratified tests not always the optimal strategy to adjust Hypothesis testing in a for covariates : nonparametric setting • Can be problematic if we need to adjust for several Proportional covariates hazards • Do not provide information on the covariate(s) on which models we stratify Parametric survival • Stratification on continuous covariates requires models categorization ⋄ We will work with semiparametric proportional hazards models, but there also exist parametric variations
Recommend






















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.