
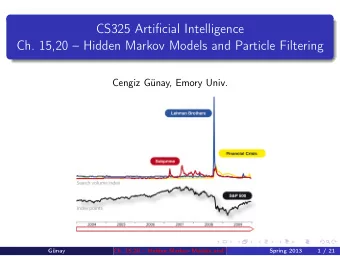
Particle Filtering Sometimes |X| is too big to use exact inference - PowerPoint PPT Presentation
Particle Filtering Sometimes |X| is too big to use exact inference |X| may be too big to even store B(X) E.g. X is continuous |X| 2 may be too big to do updates Solution: approximate inference Track samples of X, not
Particle Filtering Ø Sometimes |X| is too big to use exact inference • |X| may be too big to even store B(X) • E.g. X is continuous |X| 2 may be too big to do updates • Ø Solution: approximate inference • Track samples of X, not all values • Samples are called particles • Time per step is linear in the number of samples • But: number needed may be large • In memory: list of particles Ø This is how robot localization works in practice 1
Forward algorithm vs. particle filtering Forward algorithm Particle filtering Ø Elapse of time • Elapse of time B’(X t )= Σ x t-1 p(X t |x t-1 )B(x t-1 ) x--->x’ • Observe Ø Observe w(x’)=p(e t |x) B(X t ) ∝ p(e t |X t )B’(X t ) • Resample Ø Renormalize resample N particles B(x t ) sum up to 1 2
Today Ø Speech recognition • A massive HMM! Ø Introduction to machine learning 3
Speech and Language Ø Speech technologies • Automatic speech recognition (ASR) • Text-to-speech synthesis (TTS) • Dialog systems Ø Language processing technologies • Machine translation • Information extraction • Web search, question answering • Text classification, spam filtering, etc… 4
Digitizing Speech 5
The Input Ø Speech input is an acoustic wave form Graphs from Simon Arnfield’s web tutorial on speech, sheffield: http://www.psyc.leeds.ac.uk/research/cogn/speech/tutorial/ 6
7
The Input Ø Frequency gives pitch; amplitude gives volume • Sampling at ~8 kHz phone, ~16 kHz mic Ø Fourier transform of wave displayed as a spectrogram • Darkness indicates energy at each frequency 8
Acoustic Feature Sequence Ø Time slices are translated into acoustic feature vectors (~39 real numbers per slice) Ø These are the observations, now we need the hidden states X 9
State Space Ø p(E|X) encodes which acoustic vectors are appropriate for each phoneme (each kind of sound) Ø p(X|X’) encodes how sounds can be strung together Ø We will have one state for each sound in each word Ø From some state x, can only: • Stay in the same state (e.g. speaking slowly) • Move to the next position in the word • At the end of the word, move to the start of the next word Ø We build a little state graph for each word and chain them together to form our state space X 10
HMMs for Speech 11
Transitions with Bigrams 12
Decoding Ø While there are some practical issues, finding the words given the acoustics is an HMM inference problem Ø We want to know which state sequence x 1:T is most likely given the evidence e 1:T : * x argmax p x | e ( ) = 1: T 1: T 1: T x 1: T argmax p x , e ( ) = 1: T 1: T x 1: T Ø From the sequence x, we can simply read off the words 13
Machine Learning Ø Up until now: how to reason in a model and how to make optimal decisions Ø Machine learning: how to acquire a model on the basis of data / experience • Learning parameters (e.g. probabilities) • Learning structure (e.g. BN graphs) • Learning hidden concepts (e.g. clustering) 14
Parameter Estimation Ø Estimating the distribution of a random variable Ø Elicitation: ask a human Ø Empirically: use training data (learning!) • E.g.: for each outcome x, look at the empirical rate of that value: count x ( ) p x = ( ) ML p r = 1 3 ( ) total samples ML • This is the estimate that maximizes the likelihood of the data L x , p x ( ) ( ) θ = ∏ i θ i 15
Estimation: Smoothing Ø Relative frequencies are the maximum likelihood estimates (MLEs) count x argmax p X | ( ) ( ) θ = θ ML p x = ( ) θ ML total samples argmax p X ( ) ∏ = i θ θ i Ø In Bayesian statistics, we think of the parameters as just another random variable, with its own distribution argmax p | X ( ) θ = θ MAP θ argmax p X | p p X ???? ( ) ( ) ( ) = θ θ θ argmax p X | p ( ) ( ) = θ θ 16 θ
Estimation: Laplace Smoothing Ø Laplace’s estimate: • Pretend you saw every outcome once more than you actually did ( ) + 1 c x ( ) = p LAP x ! # ( ) + 1 ∑ c x " $ p X ( ) = x ML ( ) + 1 c x = p X ( ) = N + X LAP 17
Estimation: Laplace Smoothing Ø Laplace’s estimate (extended): • Pretend you saw every outcome k extra times c x k ( ) + p x = ( ) LAP k , N k X + p X ( ) = • What’s Laplace with k=0? LAP ,0 • k is the strength of the prior p X ( ) = LAP ,1 Ø Laplace for conditionals: • Smooth each condition p X ( ) = LAP ,100 independently: c x y , k ( ) + p x y | = ( ) LAP k , c y k X ( ) + 18
Example: Spam Filter Ø Input: email Ø Output: spam/ham Ø Setup: • Get a large collection of example emails, each labeled “spam” or “ham” • Note: someone has to hand label all this data! • Want to learn to predict labels of new, future emails Ø Features: the attributes used to make the ham / spam decision • Words: FREE! • Text patterns: $dd, CAPS • Non-text: senderInContacts • …… 19
Example: Digit Recognition Ø Input: images / pixel grids Ø Output: a digit 0-9 Ø Setup: • Get a large collection of example images, each labeled with a digit • Note: someone has to hand label all this data! • Want to learn to predict labels of new, future digit images Ø Features: the attributes used to make the digit decision • Pixels: (6,8) = ON • Shape patterns: NumComponents, AspectRation, NumLoops • …… 20
A Digit Recognizer Ø Input: pixel grids Ø Output: a digit 0-9 21
Naive Bayes for Digits Ø Simple version: • One feature F ij for each grid position <i,j> • Possible feature values are on / off, based on whether intensity is more or less than 0.5 in underlying image • Each input maps to a feature vector, e.g. → F 0,0 = 0 F 0,1 = 0 F 0,2 = 1 F 0,3 = 1 F 0,4 = 0 F 15,15 = 0 • Here: lots of features, each is binary valued Ø Naive Bayes model: ( ) ( ) ∝ p Y ( ) p Y | F 0,0 F ∏ p F i , j | Y 15,15 i , j Ø What do we need to learn? 22
General Naive Bayes Ø A general naive Bayes model: n Y × F parameters ( ) = p Y , F 1 F n ( ) ( ) p Y ∏ p F i | Y i Y parameters n × Y × F parameters Ø We only specify how each feature depends on the class Ø Total number of parameters is linear in n 23
Inference for Naive Bayes Ø Goal: compute posterior over causes • Step 1: get joint probability of causes and evidence ( ) = p Y , f 1 f n " % ( ) ( ) p y 1 p f i | c 1 ∏ $ ' ! $ ( ) p y 1 , f 1 f n i $ ' # & ( ) ( ) p y 2 ∏ p f i | c 2 $ ' # & $ ' ( ) p y 2 , f 1 f n i $ ' # & $ ' # & ( ) ( ) p y k ∏ p f i | c k $ ' # & $ ' # & i ( ) p y k , f 1 f n # & ( ) " % p f 1 f n • Step 2: get probability of evidence • Step 3: renormalize ( ) p Y | f 1 f n 24
General Naive Bayes Ø What do we need in order to use naive Bayes? • Inference (you know this part) • Start with a bunch of conditionals, p(Y) and the p(F i |Y) tables • Use standard inference to compute p(Y|F 1 …F n ) • Nothing new here • Estimates of local conditional probability tables • p(Y), the prior over labels • p(F i |Y) for each feature (evidence variable) • These probabilities are collectively called the parameters of the model and denoted by θ • Up until now, we assumed these appeared by magic, but… • … they typically come from training data: we’ll look at this now 25
Examples: CPTs p Y ( ) ( ) ( ) p F on Y | p F on Y | = = 3,1 5,5 1 0.1 1 0.01 1 0.05 2 0.1 2 0.05 2 0.01 3 0.1 3 0.05 3 0.90 4 0.1 4 0.30 4 0.80 5 0.1 5 0.80 5 0.90 6 0.1 6 0.90 6 0.90 7 0.1 7 0.05 7 0.25 8 0.1 8 0.60 8 0.85 9 0.1 9 0.50 9 0.60 0 0.1 0 0.80 0 0.80 26
Important Concepts Ø Data: labeled instances, e.g. emails marked spam/ham • Training set • Held out set • Test set Ø Features: attribute-value pairs which characterize each x Ø Experimentation cycle • Learn parameters (e.g. model probabilities) on training set • (Tune hyperparameters on held-out set) • Compute accuracy of test set • Very important: never “peek” at the test set! Ø Evaluation • Accuracy: fraction of instances predicted correctly Ø Overfitting and generalization • Want a classifier which does well on test data • Overfitting: fitting the training data very closely, but not generalizing well 27
Recommend





















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.