ACCT 420: Logistic Regression for Bankruptcy Session 6 Dr. Richard M. Crowley 1
Front matter 2 . 1
Learning objectives ▪ Theory: ▪ Academic research ▪ Application: ▪ Predicting bankruptcy over the next year for US manufacturing firms ▪ Extend to credit downgrades ▪ Methodology: ▪ Logistic regression ▪ Models from academic research 2 . 2
Datacamp ▪ Explore on your own ▪ No specific required class this week 2 . 3
Final exam expectations ▪ 2 hour exam (planned) ▪ Multiple choice (~30%) ▪ Focused on coding ▪ Long format (~70%), possible questions: ▪ Propose and explain a model to solve a problem ▪ Explain the implementation of a model ▪ Interpret results ▪ Propose visualizations to illustrate a result ▪ Interpret visualizations 2 . 4
Logistic regression interpretation 3 . 1
A simple interpretation ▪ Last week we had the model: logodds ( Double sales ) = −3.44 + 0.54 Holiday ▪ There are two ways to interpret this: 1. Coefficient by coefficient 2. In total 3 . 2
Interpretting specific coefficients logodds ( Double sales ) = −3.44 + 0.54 Holiday ▪ Interpreting specific coefficients is easiest done manually ▪ Odds for Holiday are exp(0.54) = 1.72 ▪ This means that having a holiday modifies the baseline (i.e., non- Holiday) odds by 1.72 to 1 ▪ Where 1 to 1 is considered no change ▪ Probability for Holiday is 1.72 / (1 + 1.72) = 0.63 ▪ This means that having a holiday modifies the baseline (i.e., non- Holiday) probability by 63% ▪ Where 50% is considered no change 3 . 3
Interpretting in total ▪ It is important to note that log odds are additive ▪ So, calculate a new log odd by plugging in values for variables and adding it all up ▪ Holiday: −3.44 + 0.54 ∗ 1 = −2.9 ▪ No holiday: −3.44 + 0.54 ∗ 0 = −3.44 ▪ Then calculate odds and log odds like before 3 . 4
Using predict() to simplify it can calculate log odds and probabilities for us with minimal ▪ predict() effort ▪ Specify type="response" to get probabilities test_data <- as.data.frame (IsHoliday = c (0,1)) predict (model, test_data) # log odds ## [1] -3.44 -2.90 predict (model, test_data, type="response") #probabilities ## [1] 0.03106848 0.05215356 ▪ Here, we see the baseline probability is 3.1% ▪ The probability of doubling sales on a holiday is higher, at 5.2% These are a lot easier to interpret 3 . 5
Academic research 4 . 1
History of academic research in accounting ▪ Academic research in accounting, as it is today, began in the 1960s ▪ What we call Positive Accounting Theory ▪ Positive theory: understanding how the world works ▪ Prior to the 1960s, the focus was on Prescriptive theory ▪ How the world should work ▪ Accounting research builds on work from many fields: ▪ Economics ▪ Finance ▪ Psychology ▪ Econometrics ▪ Computer science (more recently) 4 . 2
Types of academic research ▪ Theory ▪ Pure economics proofs and simulation ▪ Experimental ▪ Proper experimentation done on individuals ▪ Can be psychology experiments or economic experiments ▪ Empirical/Archival ▪ Data driven research ▪ Based on the usage of historical data (i.e., archives) ▪ Most likely to be easily co-optable by businesses and regulators 4 . 3
Who leverages accounting research ▪ Hedge funds ▪ Mutual funds ▪ Auditors ▪ Law firms 4 . 4
Where can you find academic research ▪ The SMU library has access to seemingly all high quality accounting research Google Scholar is a great site to discover research past and present ▪ SSRN is the site to find cutting edge research at ▪ List of top accounting papers on SSRN (by downloads) ▪ 4 . 5
Academic models: Altman Z-Score 5 . 1
Where does the model come from? ▪ Altman 1968, Journal of Finance ▪ A seminal paper in Finance cited over 15,000 times by other academic papers 5 . 2
What is the model about? ▪ The model was developed to identify firms likely to go bankrupt from a pool of firms ▪ Focuses on using ratio analysis to determine such firms 5 . 3
Model specification Z = 1.2 x + 1.4 x + 3.3 x + 0.6 x + 0.999 x 1 2 3 4 5 ▪ x : Working capital to assets ratio 1 ▪ x : Retained earnings to assets ratio 2 ▪ x : EBIT to assets ratio 3 ▪ x : Market value of equity to book value of 4 liabilities ▪ x : Sales to total assets 5 This looks like a linear regression without a constant 5 . 4
How did the measure come to be? ▪ It actually isn’t a linear regression ▪ It is a clustering method called MDA (multiple discriminant analysis) ▪ There are newer methods these days, such as SVM ▪ Used data from 1946 through 1965 ▪ 33 US manufacturing firms that went bankrupt, 33 that survived More about this, from Altman himself in 2000: rmc.link/420class6 ▪ Read the section “Variable Selection” starting on page 8 ▪ Skim through x , x , x , x , and x if you are interested in 1 2 3 4 5 the ratios 5 . 5
Who uses it? ▪ Despite the model’s simplicity and age, it is still in use ▪ The simplicity of it plays a large part ▪ Frequently used by financial analysts Recent news mentioning it 5 . 6
Application 6 . 1
Main question Can we use bankruptcy models to predict supplier bankruptcies? But first: Does the Altman Z-score [still] pick up bankruptcy? 6 . 2
Question structure Is this a forecasting or forensics question? 6 . 3
The data ▪ Compustat provides data on bankruptcies, including the date a company went bankrupt ▪ Bankruptcy information is included in the “footnote” items in Compustat ▪ If dlsrn == 2 , then the firm went bankrupt ▪ Bankruptcy date is dldte ▪ All components of the Altman Z-Score model are in Compustat ▪ But we’ll pull market value from CRSP, since it is more complete ▪ All components of our later models are from Compustat as well ▪ Company credit rating data also from Compustat (Rankings) 6 . 4
Bankruptcy in the US ▪ Chapter 7 ▪ The company ceases operating and liquidates ▪ Chapter 11 ▪ For firms intending to reorganize the company to “try to become profitable again” ( US SEC ) 6 . 5
Common outcomes of bankruptcy 1. Cease operations entirely (liquidated) ▪ In which case the assets are often sold off 2. Acquired by another company 3. Merge with another company 4. Successfully restructure and continue operating as the same firm 5. Restructure and operate as a new firm 6 . 6
Calculating bankruptcy # initial cleaning df <- df %>% filter (at >= 1, revt >= 1, gvkey != 100338) ## Merge in stock value df $ date <- as.Date (df $ datadate) df_mve $ date <- as.Date (df_mve $ datadate) df_mve <- df_mve %>% rename (gvkey=GVKEY) df_mve $ MVE <- df_mve $ csho * df_mve $ prcc_f df <- left_join (df, df_mve[, c ("gvkey","date","MVE")]) ## Joining, by = c("gvkey", "date") df <- df %>% group_by (gvkey) %>% mutate (bankrupt = ifelse ( row_number () == n () & dlrsn == 2 & !is.na (dlrsn), 1, 0)) %>% ungroup () ▪ row_number() gives the current row within the group, with the first row as 1, next as 2, etc. ▪ n() gives the number of rows in the group 6 . 7
Calculating the Altman Z-Score # Calculate the measures needed df <- df %>% mutate (wcap_at = wcap / at, # x1 re_at = re / at, # x2 ebit_at = ebit / at, # x3 mve_lt = MVE / lt, # x4 revt_at = revt / at) # x5 # cleanup df <- df %>% mutate_if (is.numeric, funs ( replace (., !is.finite (.), NA))) # Calculate the score df <- df %>% mutate (Z = 1.2 * wcap_at + 1.4 * re_at + 3.3 * ebit_at + 0.6 * mve_lt + 0.999 * revt_at) # Calculate date info for merging df $ date <- as.Date (df $ datadate) df $ year <- year (df $ date) df $ month <- month (df $ date) ▪ Calculate x through 1 x 5 ▪ Apply the model directly 6 . 8
Build in credit ratings We’ll check our Z-score against credit rating as a simple validation # df_ratings has ratings data in it # Ratings, in order from worst to best ratings <- c ("D", "C", "CC", "CCC-", "CCC","CCC+", "B-", "B", "B+", "BB-", "BB", "BB+", "BBB-", "BBB", "BBB+", "A-", "A", "A+", "AA-", "AA", "AA+", "AAA-", "AAA", "AAA+") # Convert string ratings (splticrm) to numeric ratings df_ratings $ rating <- factor (df_ratings $ splticrm, levels=ratings, ordered=T) df_ratings $ date <- as.Date (df_ratings $ datadate) df_ratings $ year <- year (df_ratings $ date) df_ratings $ month <- month (df_ratings $ date) # Merge together data df <- left_join (df, df_ratings[, c ("gvkey", "year", "month", "rating")]) ## Joining, by = c("gvkey", "year", "month") 6 . 9
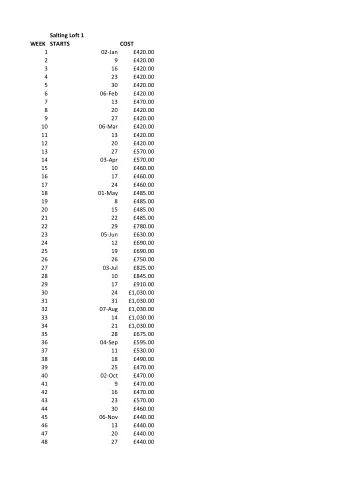
Z vs credit ratings, 1973-2017 df %>% filter ( !is.na (Z), !is.na (bankrupt)) %>% group_by (bankrupt) %>% 6 mutate (mean_Z= mean (Z,na.rm=T)) %>% slice (1) %>% ungroup () %>% select (bankrupt, mean_Z) %>% Mean Altman Z html_df () 4 bankrupt mean_Z 0 3.939223 1 0.927843 2 0 CCC- CCC+ B- B B+ BB- BB BB+ BBB- BBB BBB+ A- A A+ AA- AA AA+ AAA D CC CCC Credit rating 6 . 10
Recommend
More recommend
Unleash a World of Digital Possibilities—Browse, Share, and Explore Content Without Boundaries