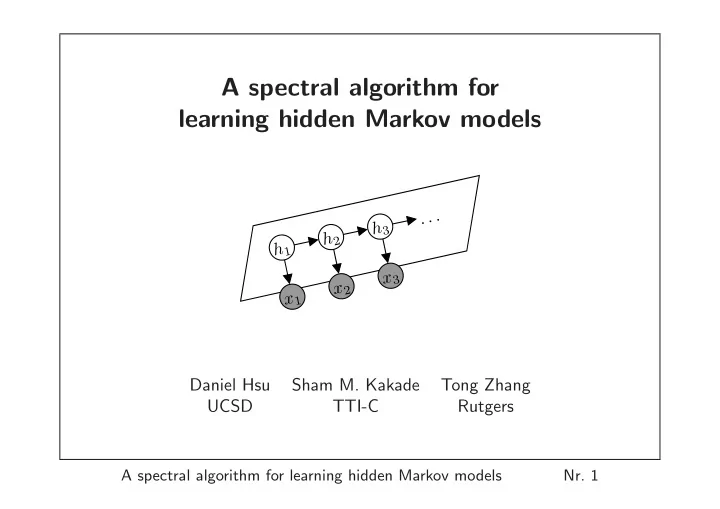
A spectral algorithm for learning hidden Markov models . . . h 3 h - PowerPoint PPT Presentation
A spectral algorithm for learning hidden Markov models . . . h 3 h 2 h 1 x 3 x 2 x 1 Daniel Hsu Sham M. Kakade Tong Zhang UCSD TTI-C Rutgers A spectral algorithm for learning hidden Markov models Nr. 1 Motivation Hidden Markov Models
A spectral algorithm for learning hidden Markov models . . . h 3 h 2 h 1 x 3 x 2 x 1 Daniel Hsu Sham M. Kakade Tong Zhang UCSD TTI-C Rutgers A spectral algorithm for learning hidden Markov models Nr. 1
Motivation • Hidden Markov Models (HMMs) – popular model for sequential data ( e.g. speech, bio-sequences, natural language) Hidden state process (Markovian) h 1 h 2 h 3 . . . Each state defines distribution over x 1 x 2 x 3 observations Observation sequence • Hidden state sequence not observed; hence, unsupervised learning . A spectral algorithm for learning hidden Markov models Nr. 2
Motivation • Why HMMs? – Handle temporally-dependent data – Succinct “factored” representation when state space is low-dimensional ( c.f. autoregressive model) • Some uses of HMMs: – Monitor “belief state” of dynamical system – Infer latent variables from time series – Density estimation A spectral algorithm for learning hidden Markov models Nr. 3
Preliminaries: parameters of discrete HMMs Sequences of hidden states ( h 1 , h 2 , . . . ) and observations ( x 1 , x 2 , . . . ) . π ∈ R m • Hidden states { 1 , 2 , . . . , m } ; • Initial state distribution � Observations { 1 , 2 , . . . , n } π i = Pr[ h 1 = i ] � • Transition matrix T ∈ R m × m • Conditional independences T ij = Pr[ h t +1 = i | h t = j ] h 1 h 2 h 3 . . . • Observation matrix O ∈ R n × m x 1 x 2 x 3 O ij = Pr[ x t = i | h t = j ] X X X Pr[ x 1: t ] = Pr[ h 1 ] · Pr[ h 2 | h 1 ] Pr[ x 1 | h 1 ] · . . . · Pr[ h t +1 | h t ] Pr[ x t | h t ] h 1 h 2 h t +1 A spectral algorithm for learning hidden Markov models Nr. 4
Preliminaries: learning discrete HMMs • Popular heuristic: Expectation-Maximization (EM) ( a.k.a. Baum-Welch algorithm) • Computationally hard in general under cryptographic assumptions (Terwijn, ’02) • This work: Computationally efficient algorithm with learning guarantees for invertible HMMs : Assume T ∈ R m × m and O ∈ R n × m have rank m . (here, n ≥ m ). A spectral algorithm for learning hidden Markov models Nr. 5
Our contributions • Simple and efficient algorithm for learning invertible HMMs. • Sample complexity bounds for – Joint probability estimation (total variation distance): X | Pr[ x 1: t ] − c Pr[ x 1: t ] | ≤ � x 1: t (relevant for density estimation tasks) – Conditional probability estimation (KL distance): KL (Pr[ x t | x 1: t − 1 ] � c Pr[ x t | x 1: t − 1 ]) ≤ � (relevant for next-symbol prediction / “belief states”) • Connects subspace identification to observation operators . A spectral algorithm for learning hidden Markov models Nr. 6
Outline 1. Motivation and preliminaries 2. Discrete HMMs: key ideas 3. Observable representation for HMMs 4. Learning algorithm and guarantees 5. Conclusions and future work A spectral algorithm for learning hidden Markov models Nr. 7
Outline 1. Motivation and preliminaries 2. Discrete HMMs: key ideas 3. Observable representation for HMMs 4. Learning algorithm and guarantees 5. Conclusions and future work A spectral algorithm for learning hidden Markov models Nr. 8
Discrete HMMs: linear model e n } (coord. vectors in R m and R n ) Let � h t ∈ { � e 1 , . . . ,� e m } and � x t ∈ { � e 1 , . . . ,� E [ � h t +1 | � h t ] = T � x t | � h t ] = O � h t and E [ � h t In expectation, dynamics and observation process are linear! e.g. conditioned on h t = 2 ( i.e. � h t = � e 2 ): 2 3 2 3 2 3 0 . 2 0 . 4 0 . 6 0 0 . 4 E [ � h t +1 | � 4 5 4 5 = 4 5 h t ] = 0 . 3 0 . 6 0 . 4 1 0 . 6 0 . 5 0 0 0 0 Upshot: Can borrow “subspace identification” techniques from linear systems theory. A spectral algorithm for learning hidden Markov models Nr. 9
Discrete HMMs: linear model Exploiting linearity • Subspace identification for general linear models – Use SVD to discover subspace containing relevant states, then learn effective transition and observation matrices (Ljung, ’87). – Analysis typically assumes additive noise (independent of state), e.g. Gaussian noise (Kalman filter); not applicable to HMMs. • This work: Use subspace identification, then learn alternative HMM parameterization. A spectral algorithm for learning hidden Markov models Nr. 10
Discrete HMMs: observation operators For x ∈ { 1 , . . . , n } : define O x, 1 0 ... T △ ∈ R m × m A x = 0 O x,m [ A x ] i,j = Pr[ h t +1 = i ∧ x t = x | h t = j ] . The { A x } are observation operators (Sch¨ utzenberger, ’61; Jaeger, ’00). T h t . . . O x t A x t A spectral algorithm for learning hidden Markov models Nr. 11
Discrete HMMs: observation operators Using observation operators Matrix multiplication handles “local” marginalization of hidden variables: e.g. X X X Pr[ x 1 , x 2 ] = Pr[ h 1 ] · Pr[ h 2 | h 1 ] Pr[ x 1 | h 1 ] · Pr[ h 3 | h 2 ] Pr[ x 2 | h 2 ] h 1 h 2 h 3 = � 1 ⊤ m A x 2 A x 1 � π 1 m ∈ R m is the all-ones vector. where � Upshot: The { A x } contain the same information as T and O . A spectral algorithm for learning hidden Markov models Nr. 12
Discrete HMMs: observation operators Learning observation operators • Previous methods face the problem of discovering and extracting the relationship between hidden states and observations (Jaeger, ’00). – Various techniques proposed ( e.g. James and Singh, ’04; Wiewiora, ’05). – Formal guarantees were unclear. • This work: Combine subspace identification with observation operators to yield observable HMM representation that is efficiently learnable . A spectral algorithm for learning hidden Markov models Nr. 13
Outline 1. Motivation and preliminaries 2. Discrete HMMs: key ideas 3. Observable representation for HMMs 4. Learning algorithm and guarantees 5. Conclusions and future work A spectral algorithm for learning hidden Markov models Nr. 14
Observable representation for HMMs Key rank condition: require T ∈ R m × m and O ∈ R n × m to have rank m (rules out pathological cases from hardness reductions) Define P 1 ∈ R n , P 2 , 1 ∈ R n × n , P 3 ,x, 1 ∈ R n × n for x = 1 , . . . , n by [ P 1 ] i = Pr[ x 1 = i ] [ P 2 , 1 ] i,j = Pr[ x 2 = i, x 1 = j ] [ P 3 ,x, 1 ] i,j = Pr[ x 3 = i, x 2 = x, x 1 = j ] (probabilities of singletons, doubles, and triples). Claim: Can recover equivalent HMM parameters from P 1 , P 2 , 1 , { P 3 ,x, 1 } , and these quantities can be estimated from data . A spectral algorithm for learning hidden Markov models Nr. 15
Observable representation for HMMs “Thin” SVD: P 2 , 1 = UΣV ⊤ where U = [ � u m ] ∈ R n × m u 1 | . . . | � Guaranteed m non-zero singular values by rank condition. x t | � E [ � h t ] u 2 � � u 1 R ( U ) = R ( O ) New parameters (based on U ) implicitly transform hidden states � ( U ⊤ O ) � x t | � U ⊤ E [ � h t �→ h t = h t ] x t | � ( i.e. change to coordinate representation of E [ � h t ] w.r.t. { � u 1 , . . . , � u m } ). A spectral algorithm for learning hidden Markov models Nr. 16
Observable representation for HMMs For each x = 1 , . . . , n , ( X + is pseudoinv. of X ) = ( U ⊤ P 3 ,x, 1 ) ( U ⊤ P 2 , 1 ) + △ B x = ( U ⊤ O ) A x ( U ⊤ O ) − 1 . (algebra) The B x operate in the coord. system defined by { � u 1 , . . . , � u m } (columns of U ). Pr[ x 1: t ] = � π = � m ( U ⊤ O ) − 1 B x t . . . B x 1 ( U ⊤ O ) � 1 ⊤ 1 ⊤ m A x t . . . A x 1 � π U ⊤ ( O� h t ) T h t u 2 � B xt ( U ⊤ O� h t ) = U ⊤ ( OA xt � h t ) O x t u 1 � A xt ∼ B xt Upshot: Suffices to learn { B x } instead of { A x } . A spectral algorithm for learning hidden Markov models Nr. 17
Outline 1. Motivation and preliminaries 2. Discrete HMMs: key ideas 3. Observable representation for HMMs 4. Learning algorithm and guarantees 5. Conclusions and future work A spectral algorithm for learning hidden Markov models Nr. 18
Learning algorithm The algorithm 1. Look at triples of observations ( x 1 , x 2 , x 3 ) in data; estimate frequencies � P 1 , � P 2 , 1 , and { � P 3 ,x, 1 } 2. Compute SVD of � P 2 , 1 to get matrix of top m singular vectors � U (“subspace identification”) U ⊤ � U ⊤ � P 2 , 1 ) + for each x 3. Compute � = ( � △ P 3 ,x, 1 )( � B x (“observation operators”) U ⊤ � U ) + � 4. Compute � = � △ P 1 and � = ( � △ 2 , 1 � P ⊤ b 1 b ∞ P 1 A spectral algorithm for learning hidden Markov models Nr. 19
Learning algorithm • Joint probability calculations: � = � ∞ � B x t . . . � B x 1 � △ b ⊤ Pr[ x 1 , . . . , x t ] b 1 . • Conditional probabilities: Given x 1: t − 1 , � = � ∞ � B x t � △ b ⊤ Pr[ x t | x 1: t − 1 ] b t where B x t − 1 . . . � � B x 1 � b 1 ≈ ( U ⊤ O ) E [ � � △ b t = h t | x 1: t − 1 ] . � ∞ � B x t − 1 . . . � B x 1 � b ⊤ b 1 “Belief states” � b t linearly related to conditional hidden states. ( b t live in hypercube [ − 1 , +1] m instead simplex ∆ m ) A spectral algorithm for learning hidden Markov models Nr. 20
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.