
Training Neural Networks Using Features Replay Zhouyuan Huo 1 , Bin - PowerPoint PPT Presentation
Training Neural Networks Using Features Replay Zhouyuan Huo 1 , Bin Gu 1 , 2 , Heng Huang 1 , 2 1 Department of Electrical and Computer Engineering, University of Pittsburgh 2 JD.com November 28, 2018 Zhouyuan Huo 1 , Bin Gu 1 , 2 , Heng Huang 1 ,
Training Neural Networks Using Features Replay Zhouyuan Huo 1 , Bin Gu 1 , 2 , Heng Huang 1 , 2 1 Department of Electrical and Computer Engineering, University of Pittsburgh 2 JD.com November 28, 2018 Zhouyuan Huo 1 , Bin Gu 1 , 2 , Heng Huang 1 , 2 (Pitt) FR November 28, 2018 1 / 8
Motivation poster #12 Backpropagation algorithm: step 1: Forward pass. step 2: Backward pass. Problem: Backward time is about 2 times of forward time. Backward locking. Backward cannot be parallellized. Zhouyuan Huo 1 , Bin Gu 1 , 2 , Heng Huang 1 , 2 (Pitt) FR November 28, 2018 2 / 8
Problem Reformulation poster #12 New formulation: Original formulation: 2 ( w t ) � � K − 1 ∂ f ht � � min f ( h L , y ) � � δ t Lk � h t L K , y t � min k − + f � � ∂ h t w w ,δ Lk � k =1 2 s . t . h l = F l ( h l − 1 ; w l ) h t L k = F G ( k ) ( h t L k − 1 ; w t s . t . G ( k ) ) Zhouyuan Huo 1 , Bin Gu 1 , 2 , Heng Huang 1 , 2 (Pitt) FR November 28, 2018 3 / 8
Problem Reformulation (Continued) poster #12 Module 1: 2 � � ( w t ) ∂ f ht � � � δ t L 1 Module 4: min 1 − � � ∂ h t � � w ,δ L 1 � h t L 4 , y t � min f � 2 w ,δ h t L 1 = F G (1) ( h t L 0 ; w t G (1) ) s . t . h t L 4 = F G (4) ( h t L 3 ; w t s . t . G (4) ) ( w t ) ∂ f ht − 3 We approximate δ t L 1 1 = . ∂ h t − 3 L 1 Zhouyuan Huo 1 , Bin Gu 1 , 2 , Heng Huang 1 , 2 (Pitt) FR November 28, 2018 4 / 8
Features Replay poster #12 Module 1 Module 2 Module 3 Module 4 layer 1 layer 2 layer 3 layer 10 layer 11 layer 12 layer 4 layer 5 layer 6 layer 7 layer 8 layer 9 loss δ t δ t δ t 1 2 3 h t − 3 t t t t t t t t ˜ ˜ ˜ h t − 2 ˜ ˜ ˜ h t − 1 ˜ ˜ t h t h t h t h t h h h h h h h h ˜ h 0 1 2 3 3 4 5 10 11 6 6 7 8 9 9 12 h t − 2 h t − 1 h t 0 3 6 h t − 1 h t 0 3 h Forward pass Activation h t 0 Backward pass Error gradient δ Backward pass: Forward pass: ˜ L k = F G ( k ) ( h t + k − K h t ; w t G ( k ) ) (Replay) L k − 1 � � h t h t L k − 1 ; w t L k = F G ( k ) (Play) Apply chain rule using ˜ h t L k and δ t G ( k ) k in each module. Zhouyuan Huo 1 , Bin Gu 1 , 2 , Heng Huang 1 , 2 (Pitt) FR November 28, 2018 5 / 8
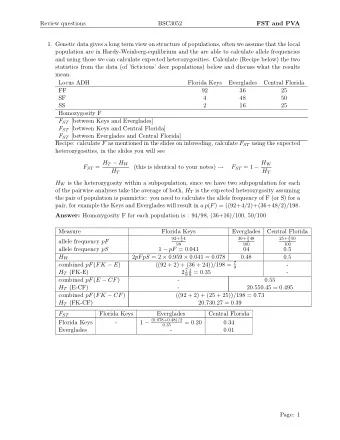
Convergence Guarantee poster #12 Convergence Guarantee: T − 1 γ 2 � T − 1 t f ( w 0 ) − f ( w ∗ ) 1 + LM � 2 � t =0 � � ∇ f ( w t ) � γ t E . (1) ≤ 2 2 σ T − 1 T − 1 T − 1 � t =0 � � γ t σ γ t γ t t =0 t =0 t =0 Zhouyuan Huo 1 , Bin Gu 1 , 2 , Heng Huang 1 , 2 (Pitt) FR November 28, 2018 6 / 8
Experimental Results poster #12 Faster Convergence. Lower Memory Consumption. Better Generalization Error. Zhouyuan Huo 1 , Bin Gu 1 , 2 , Heng Huang 1 , 2 (Pitt) FR November 28, 2018 7 / 8
Thanks ! Welcome to poster #12 Room 210 & 230 AB Zhouyuan Huo 1 , Bin Gu 1 , 2 , Heng Huang 1 , 2 (Pitt) FR November 28, 2018 8 / 8
Recommend






















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.