Penalized Linear Regression Prof. Mike Hughes Many slides - PowerPoint PPT Presentation
Tufts COMP 135: Introduction to Machine Learning https://www.cs.tufts.edu/comp/135/2020f/ Penalized Linear Regression Prof. Mike Hughes Many slides attributable to: Erik Sudderth (UCI) Finale Doshi-Velez (Harvard) James, Witten, Hastie,
Tufts COMP 135: Introduction to Machine Learning https://www.cs.tufts.edu/comp/135/2020f/ Penalized Linear Regression Prof. Mike Hughes Many slides attributable to: Erik Sudderth (UCI) Finale Doshi-Velez (Harvard) James, Witten, Hastie, Tibshirani (ISL/ESL books) 2
Today’s objectives (day 05) • Recap: Overfitting with high-degree features • Remedy: Add L2 penalty to the loss (“Ridge”) • Avoid high magnitude weights • Remedy: Add L1 penalty to the loss (“Lasso”) • Avoid high magnitude weights • Often, some weights exactly zero (feature selection) Mike Hughes - Tufts COMP 135 - Fall 2020 3
What will we learn? Evaluation Supervised Training Learning Data, Label Pairs Performance { x n , y n } N measure Task n =1 Unsupervised Learning data label x y Reinforcement Learning Prediction Mike Hughes - Tufts COMP 135 - Fall 2020 4
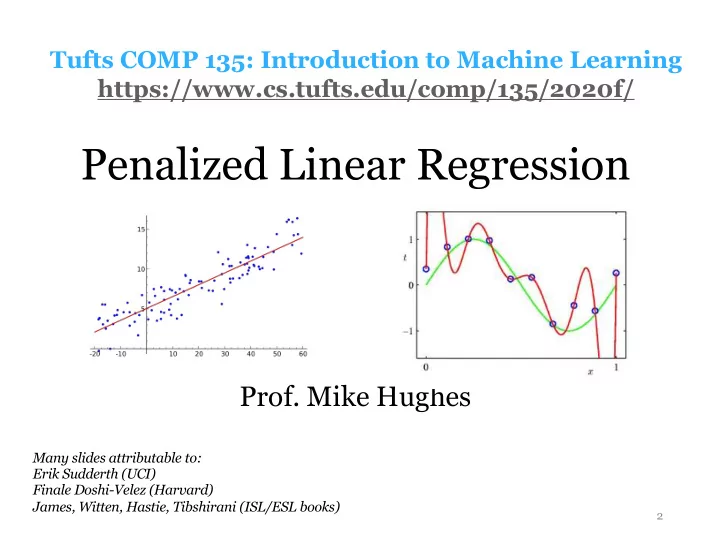
Task: Regression y is a numeric variable Supervised e.g. sales in $$ Learning regression y Unsupervised Learning Reinforcement Learning x Mike Hughes - Tufts COMP 135 - Fall 2020 5
<latexit sha1_base64="CpPYWC8yCiRfefbVRXgbwSkx/R4=">ACMnicbVBNa9tAEF2lzZfy5abHXpaQk5GcgLJRDS3IpKcROwCvMajWyl6xWYncUEMK/qZf+kAOzSEh5Nof0bWtQ+L0wTKP92Z2d15cKGkxCP54Sx8+Lq+srq37G5tb2zutT7t9m5dGQE/kKjfXMbegpIYeSlRwXRjgWazgKr75PvWvbsFYmetLrAqIMj7SMpWCo5OGrfOKHlOmIMUBi2Ekdc2N4dWkFhO/GoaUMVe608JukxztXPjhM9BJ08qMHI0xGrbaQSeYgb4nYUPapMHFsHXHklyUGWgUils7CIMCI3cpSqFg4rPSQsHFDR/BwFHNM7BRPVt5Qr85JaFpbtzRSGfq64maZ9ZWew6M45ju+hNxf95gxLTo6iWuigRtJg/lJaKYk6n+dFEGhCoKke4MNL9lYoxN1ygS9l3IYSLK78n/W4n3O90fx60T06bONbIF/KV7JGQHJITckYuSI8I8ovck0fy5P32Hrxn72XeuQ1M5/JG3h/wFvpKm0</latexit> <latexit sha1_base64="5FDy/8MPeWNsORWABemLQ8+v/ak=">ACSHicbVBNaxRBEO1ZP5KsH1n16KVwETaoy8xG0IsQDIgnieImge3doae3Z6dJd8/QXSMOzeTfeckxt/yGXDwo4s2Z3T1o4oOCx3tV3VUvKZR0GIYXQefGzVu3Nza3unfu3ru/3Xvw8NDlpeVizHOV2+OEOaGkEWOUqMRxYQXTiRJHycl+6x9EdbJ3HzGqhBTzRZGpIzbKS4F1MtTewpZgIZUGmAaoZkvhP9cy/exbVNZyeAnWljr15E9WzD0CVSHEAVWzgBdCMoa/qwdfYPIfVMztArVxkuDMbdeNePxyGS8B1Eq1Jn6xEPfO6TznpRYGuWLOTaKwKlnFiVXou7S0omC8RO2EJOGqaFm/plEDU8bZQ5pLltyiAs1b8nPNPOVTpOtsr3VWvFf/nTUpMX0+9NEWJwvDVR2mpAHNoU4W5tIKjqhrCuJXNrsAzZhnHJvs2hOjqydfJ4WgY7Q5H1/296u49gkj8kTMiAReUX2yHtyQMaEk2/kvwgP4Oz4HvwK/i9au0E65lH5B90On8AqaSw9w=</latexit> Review: Linear Regression Optimization problem: “Least Squares” N y ( x n , θ )) 2 X min ( y n − ˆ θ ∈ R F +1 n =1 Exact formula for estimating optimal parameter vector values: T = ( ˜ X T ˜ X ) − 1 ˜ X T y θ = [ x 11 . . . x 1 F 1 y 1 x 21 . . . x 2 F 1 y 2 ˜ X = y = . . . . . . x N 1 . . . x NF 1 y N Can use formula when you observe at least F+1 examples that are linearly independent Otherwise, many theta values yield lowest possible training error (many linear functions make perfect predictions on the training set) Mike Hughes - Tufts COMP 135 - Fall 2020 6
Review: Linear Regression with Transformed Features φ ( x i ) = [1 φ 1 ( x i ) φ 2 ( x i ) . . . φ G − 1 ( x i )] y ( x i ) = θ T φ ( x i ) ˆ Optimization problem: “Least Squares” n =1 ( y n − θ T φ ( x i )) 2 P N min θ Exact solution: 1 φ 1 ( x 1 ) φ G − 1 ( x 1 ) . . . 1 φ 1 ( x 2 ) φ G − 1 ( x 2 ) . . . θ ∗ = ( Φ T Φ ) − 1 Φ T y Φ = . ... . . 1 φ 1 ( x N ) φ G − 1 ( x N ) . . . G x 1 N x G matrix vector Mike Hughes - Tufts COMP 135 - Fall 2020 7
<latexit sha1_base64="Vqjm5xzGTMUb4IQbGI/zga5haw=">AB+nicbVDLSsNAFL2pr1pfqS7dDBahbkpSBd0IRTcuK9gHpCFMpN26OTBzEQtsZ/ixoUibv0Sd/6N0zYLbT1w4XDOvdx7j59wJpVlfRuFldW19Y3iZmlre2d3zyzvt2WcCkJbJOax6PpYUs4i2lJMcdpNBMWhz2nH1P/c49FZLF0Z0aJ9QN8SBiASNYackzy71kyKqPHjtBl8hBNnI9s2LVrBnQMrFzUoEcTc/86vVjkoY0UoRjKR3bSpSbYaEY4XRS6qWSJpiM8IA6mkY4pNLNZqdP0LFW+iIha5IoZn6eyLDoZTj0NedIVZDuehNxf8J1XBhZuxKEkVjch8UZBypGI0zQH1maBE8bEmAimb0VkiAUmSqdV0iHYiy8vk3a9Zp/W6rdnlcZVHkcRDuEIqmDOTgBprQAgIP8Ayv8GY8GS/Gu/Exby0Y+cwB/IHx+QN2+JIt</latexit> 0 th degree polynomial features φ ( x i ) = [1] # parameters: G = 1 --- true function o training data -- predictions from LR using polynomial features Credit: Slides from course by Prof. Erik Sudderth (UCI) Mike Hughes - Tufts COMP 135 - Fall 2020 8
<latexit sha1_base64="ROx53TGV+mlmSc9CBFRvpTRYj1g=">ACA3icbVDLSgNBEOyNrxhfq970MhiEeAm7UdCLEPTiMYJ5QLIs5PZMjsg5lZSVgiXvwVLx4U8epPePNvnCR70MSChqKqm+4uL+ZMKsv6NnJLyura/n1wsbm1vaOubvXkFEiCK2TiEei5WFJOQtpXTHFaSsWFAcep01vcD3xm/dUSBaFd2oUyfAvZD5jGClJdc86MR9Vhq67ARdojay0QMauimzx8hxzaJVtqZAi8TOSBEy1Fzq9ONSBLQUBGOpWzbVqycFAvFCKfjQieRNMZkgHu0rWmIAyqdPrDGB1rpYv8SOgKFZqvydSHEg5CjzdGWDVl/PeRPzPayfKv3BSFsaJoiGZLfITjlSEJoGgLhOUKD7SBPB9K2I9LHAROnYCjoEe/7lRdKolO3TcuX2rFi9yuLIwyEcQlsOIcq3EAN6kDgEZ7hFd6MJ+PFeDc+Zq05I5vZhz8wPn8AxciVrg=</latexit> 1 st degree polynomial features φ ( x i ) = [1 x i 1 ] # parameters: G = 2 --- true function o training data -- predictions from LR using polynomial features Credit: Slides from course by Prof. Erik Sudderth (UCI) Mike Hughes - Tufts COMP 135 - Fall 2020 9
<latexit sha1_base64="35/9F4e7tWNCJ7bwpwB5G5u+rUw=">ACHicbZDLSsNAFIYn9VbrLerSzWAR6qYkraAboejGZQV7gTSGyXTSDp1MwsxEWkL7Hm58FTcuFHjQvBtnF7A2vrDwMd/zuHM+f2YUaks69vIrKyurW9kN3Nb2zu7e+b+QV1GicCkhiMWiaPJGUk5qipFmLAgKfUYafu96XG8ECFpxO/UICZuiDqcBhQjpS3PLfiLi30PXoKL6EDbTgawb6XUnv4S/elOS5D1zPzVtGaC6DPYM8mKnqmZ+tdoSTkHCFGZLSsa1YuSkSimJGhrlWIkmMcA91iKORo5BIN50cN4Qn2mnDIBL6cQUn7vxEikIpB6GvO0OkunKxNjb/qzmJCi7clPI4UYTj6aIgYVBFcJwUbFNBsGIDQgLqv8KcRcJhJXOM6dDsBdPXoZ6qWiXi6Xbs3zlahZHFhyBY1ANjgHFXADqAGMHgEz+AVvBlPxovxbnxMWzPGbOYQ/JHx9QMnR5+R</latexit> 3 rd degree polynomial features φ ( x i ) = [1 x i 1 x 2 i 1 x 3 i 1 ] # parameters: G = 4 --- true function o training data -- predictions from LR using polynomial features Credit: Slides from course by Prof. Erik Sudderth (UCI) Mike Hughes - Tufts COMP 135 - Fall 2020 10
<latexit sha1_base64="0ZuKXclmIgbBxiMXMrMg1yHQ2Eg=">ACaXicbZHLTgIxFIY74w0RFTQao5tGYoIbMgMouDAhunGJiVwSGCedUqChc0nbMZAJxGd05wu48SUsl8QRPEmT7/9PT9r+dQJGhTSMT03f2Nza3knsJvdS+weH6cxRQ/ghx6SOfebzloMEYdQjdUklI62AE+Q6jDSd4eOs3wjXFDfe5HjgFgu6nu0RzGSyrLT751gQHMjm17De9iGJpxO4ciOqDn5pdCjIsxLsGYuImL27gox0UlLu6gZaezRt6YF1wHcwlZsKyanf7odH0cusSTmCEh2qYRSCtCXFLMyCTZCQUJEB6iPmkr9JBLhBXNk5rAK+V0Yc/nankSzt34RIRcIcauo3a6SA7Eam9m/tdrh7JXsSLqBaEkHl4c1AsZlD6cxQ67lBMs2VgBwpyqu0I8QBxhqT4nqUIwV5+8Do1C3izmC8+lbPVhGUcCXIBLkAMmKIMqeAI1UAcYfGkp7UQ71b71jH6mny+26tpy5hj8KT37A/GctZM=</latexit> 9 th degree polynomial features φ ( x i ) = [1 x i 1 x 2 i 1 x 3 i 1 x 4 i 1 x 5 i 1 x 6 i 1 x 7 i 1 x 8 i 1 x 9 i 1 ] # parameters: G = 10 --- true function o training data -- predictions from LR using polynomial features Credit: Slides from course by Prof. Erik Sudderth (UCI) Mike Hughes - Tufts COMP 135 - Fall 2020 11
Error vs Complexity mean squared error polynomial degree Mike Hughes - Tufts COMP 135 - Fall 2020 12
Weight Values vs Complexity Polynomial degree 9 3 0 1 Estimated Regression Coefficients WOW! These values are very large. Credit: Slides from course by Prof. Erik Sudderth (UCI) Mike Hughes - Tufts COMP 135 - Fall 2020 13
<latexit sha1_base64="EthG14PEeaE+gWAxSNz8sNc9IQo=">ACQXicbVDPSxtBGJ21tdpoa9oevXw0FBKkYTcK9iJIPSgeioLRQDZvp1MsoOzs8vMt2JY8q/14n/Qm3cvHiql17cTfbQah8MPN4PZuaFqZKWXPfWXrxcvnVyur2tr6m7cb9Xfvz2SGS6PFGJ6YVohZJadEmSEr3UCIxDJS7Cy4PSv7gSxspEn9E0FYMYJ1qOJUcqpKDeO276FAnCFuyBb7M4yPWeNxt+g+Y0PAZFu7wDPw0ks3rQLdaw7AFvio0girzqTsHFbhYDLs1IJ6w27c8Bz4lWkwSqcBPUf/ijhWSw0cYXW9j03pUGOhiRXYlbzMytS5Jc4Ef2CaoyFHeTzBWbwqVBGME5McTBXP27kWNs7TQOi2SMFNmnXin+z+tnNP4yKVOMxKaLy4aZwogXJOGEkjOKlpQZAbWbwVeIQGORWjlyN4T7/8nJx32t52u3O609j/Ws2xyjbZR9ZkHtl+yInbAu4+w7u2M/2YNz49w7v5zfi+iSU3U+sH/g/HkE1sKs5Q=</latexit> Idea: Add Penalty Term to Loss Goal: Avoid finding weights with large magnitude Result: Ridge regression , a method with objective: N G ( y n − θ T φ ( x n )) 2 + α X X θ 2 J ( θ ) = g n =1 g =1 Penalty term: Sum of squares of entries of theta = Square of the “L2 norm” of theta vector Thus, also called “L2-penalized” linear regression α ≥ 0 Hyperparameter : Penalty strength “alpha” Alpha = 0 recovers original unpenalized Linear Regression Larger alpha means we prefer smaller magnitude weights Mike Hughes - Tufts COMP 135 - Fall 2020 14
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.