
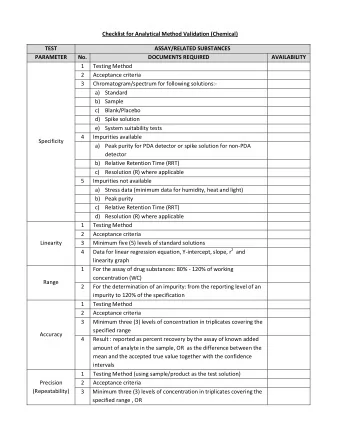
Linear Bandits: Rich decision sets Sham M. Kakade Machine Learning - PowerPoint PPT Presentation
Linear Bandits: Rich decision sets Sham M. Kakade Machine Learning for Big Data CSE547/STAT548 University of Washington S. M. Kakade (UW) Optimization for Big data 1 / 9 Bandits in practice: two major issues The decision space is very
Linear Bandits: Rich decision sets Sham M. Kakade Machine Learning for Big Data CSE547/STAT548 University of Washington S. M. Kakade (UW) Optimization for Big data 1 / 9
Bandits in practice: two major issues The decision space is very large. Drug cocktails Ad design We often have “side information” when making a decision history of a user S. M. Kakade (UW) Optimization for Big data 2 / 9
More real motivations... S. M. Kakade (UW) Optimization for Big data 2 / 9
Linear bandits An additive effects model. Suppose each round we take a decision x ∈ D ⊂ R d . x is paths on a graph. x is a feature vector of properties of an ad x is a which drugs are being taken Upon taking action x , we get reward r , with expectation: E [ r | x ] = µ ⊤ x only d unknown paramters (and “effectively” 2 d actions) W desire an algorithm A (mapping histories to deicsions), which has low regret. µ ⊤ x ∗ − E [ µ ⊤ x t |A ] ≤ ?? (where x ∗ is the best decision) S. M. Kakade (UW) Optimization for Big data 3 / 9
Example: Shortest paths... S. M. Kakade (UW) Optimization for Big data 3 / 9
Algorithm Idea again, let’s think of optimism in the face of uncertainty we observed some r 1 , . . . r t − 1 , and have taken x 1 , . . . x t − 1 . Questions: what is an estimate of the reward of E [ r | x ] and what is our uncertainty? what is an estimate of µ and what is our uncertainty? S. M. Kakade (UW) Optimization for Big data 4 / 9
Regression! Define: � � x τ x ⊤ A t := τ + λ I , b t := x τ r τ τ< t τ< t Our estimate of µ µ t = A − 1 ˆ b t t Confidence of our estimate: µ t � 2 � µ − ˆ A t ≤ O ( d log t ) S. M. Kakade (UW) Optimization for Big data 5 / 9
LinUCB Again, optimism in the face of uncertainty. Define: µ � 2 B t := { ν |� ν − ˆ A t ≤ O d log t } (Lin UCB) take action: ν ⊤ x x t = argmax x ∈D max ν then update A t , B t , b t , and ˆ µ t . Equivalently, take action: � µ ⊤ x + ( d log t ) xA − 1 x t = argmax x ∈D ˆ x t S. M. Kakade (UW) Optimization for Big data 6 / 9
LinUCB: Geometry S. M. Kakade (UW) Optimization for Big data 7 / 9
LinUCB: Confidence intervals S. M. Kakade (UW) Optimization for Big data 8 / 9
LinUCB Regret bound: √ µ ⊤ x ∗ − E [ µ ⊤ x t |A ] ≤ ∗ ( d T ) (this is the best possible, up to log factors). √ Compare to O ( KT ) Independent of number of actions. k -arm case is a special case. Thompson sampling: This is a good algorithm in practice. S. M. Kakade (UW) Optimization for Big data 9 / 9
Proof Idea... Stats: need to show that B t is a valid confidence region. Geometric lemma: The regret is upper bounded by the: log volume of posterior cov volume of prior cov Then just find the worst case log volume change. S. M. Kakade (UW) Optimization for Big data 9 / 9
Dealing with context... S. M. Kakade (UW) Optimization for Big data 9 / 9
Dealing with context... S. M. Kakade (UW) Optimization for Big data 9 / 9
Acknowledgements http://gdrro.lip6.fr/sites/default/files/ JourneeCOSdec2015-Kaufman.pdf https://sites.google.com/site/banditstutorial/ http://www.yisongyue.com/courses/cs159/lectures/ LinUCB.pdf S. M. Kakade (UW) Optimization for Big data 9 / 9
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.