
Lecture 5: Measures of Information for Continuous Random Variables - PowerPoint PPT Presentation
Entropy and Mutual Information Differential Entropy Lecture 5: Measures of Information for Continuous Random Variables I-Hsiang Wang Department of Electrical Engineering National Taiwan University ihwang@ntu.edu.tw October 26, 2015 1 / 24
Entropy and Mutual Information Differential Entropy Lecture 5: Measures of Information for Continuous Random Variables I-Hsiang Wang Department of Electrical Engineering National Taiwan University ihwang@ntu.edu.tw October 26, 2015 1 / 24 I-Hsiang Wang IT Lecture 5
Entropy and Mutual Information Differential Entropy From Discrete to Continuous So far we have focused on the discrete (& finite-alphabet) r.v’s: Entropy and mutual information for discrete r.v’s. Lossless source coding for discrete stationary sources. Channel coding over discrete memoryless channels. In this lecture and the next two lectures, we extend the basic principles In particular: Mutual information for continuous r.v.’s. (this lecture) Lossy source coding for continuous stationary sources. (Lecture 7) Gaussian channel capacity. (Lecture 6) 2 / 24 I-Hsiang Wang IT Lecture 5 and fundamental theorems to continuous random sources and channels.
Entropy and Mutual Information Differential Entropy Outline 1 First we investigate basic information measures – entropy, mutual information, and KL divergence – when the r.v.’s are continuous. We will see that both mutual information and KL divergence are well defined, while entropy of continuous r.v. is not. 2 Then, we introduce differential entropy as a continuous r.v.’s counterpart of Shannon entropy, and discuss the related properties. 3 / 24 I-Hsiang Wang IT Lecture 5
Entropy and Mutual Information Differential Entropy 1 Entropy and Mutual Information 2 Differential Entropy 4 / 24 I-Hsiang Wang IT Lecture 5
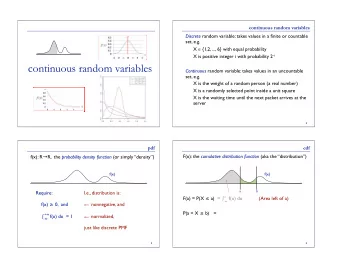
Entropy and Mutual Information Differential Entropy I-Hsiang Wang 5 / 24 IT Lecture 5 What is the entropy of a continuous real-valued random variable X ? Question : Entropy of a Continuous Random Variable Suppose X has the probability density function (p.d.f.) f ( x ) . Let us discretize X to answer this question, as follows: Partition R into length- ∆ intervals: ∞ ∪ R = [ k ∆ , ( k + 1)∆) . k = −∞ Suppose that f ( x ) is continuous, then by the mean-value theorem, ∫ ( k +1)∆ ∀ k ∈ Z , ∃ x k ∈ [ k ∆ , ( k + 1)∆) such that f ( x k ) = 1 f ( x ) dx . ∆ k ∆ Set [ X ] ∆ ≜ x k if X ∈ [ k ∆ , ( k + 1)∆) , with p.m.f. p ( x k ) = f ( x k ) ∆ .
Entropy and Mutual Information Differential Entropy 6 / 24 I-Hsiang Wang IT Lecture 5 f ( x ) f ( x ) � dF X ( x ) F X ( x ) � P { X ≤ x } dx x
Entropy and Mutual Information Differential Entropy 7 / 24 I-Hsiang Wang IT Lecture 5 f ( x ) ∆ x
Entropy and Mutual Information Differential Entropy 8 / 24 I-Hsiang Wang IT Lecture 5 f ( x ) ∆ x x 1 x 3 x 5
Entropy and Mutual Information Differential Entropy I-Hsiang Wang 9 / 24 be arbitrarily large, because it can take infinitely many possible values. It is quite intuitive that the entropy of a continuous random variable can exists. log IT Lecture 5 Observation : lim ∆ → 0 H ([ X ] ∆ ) = H ( X ) (intuitively), while ∞ ∑ H ([ X ] ∆ ) = − ( f ( x k ) ∆) log ( f ( x k ) ∆) k = −∞ ∞ ∑ = − ∆ f ( x k ) log f ( x k ) − log ∆ k = −∞ ∫ ∞ → − f ( x ) log f ( x ) dx + ∞ ∞ = ∞ as ∆ → 0 [ ] ∫ ∞ 1 Hence, H ( X ) = ∞ if − ∞ f ( x ) log f ( x ) dx = E f ( X )
Entropy and Mutual Information Differential Entropy I-Hsiang Wang 10 / 24 such that j IT Lecture 5 Again, we use discretization: Mutual Information between Continuous Random Variables How about mutual information between two continuous r.v.’s X and Y , with joint p.d.f. f X , Y ( x , y ) and marginal p.d.f.’s f X ( x ) and f Y ( y ) ? Partition R 2 plane into ∆ × ∆ squares: R 2 = ∪ ∞ k , j = −∞ I ∆ k × I ∆ j , where I ∆ k ≜ [ k ∆ , ( k + 1)∆) . Suppose that f X , Y ( x , y ) is continuous, then by the mean-value theorem (MVT), ∀ k , j ∈ Z , ∃ ( x k , y j ) ∈ I ∆ k × I ∆ ∫ 1 f X , Y ( x k , y j ) = j f X , Y ( x , y ) dx dy . ∆ 2 I ∆ k ×I ∆ Set ([ X ] ∆ , [ Y ] ∆ ) ≜ ( x k , y j ) if ( X , Y ) ∈ I ∆ k × I ∆ j , with p.m.f. p ( x k , y j ) = f X , Y ( x k , y j ) ∆ 2 .
Entropy and Mutual Information I I-Hsiang Wang 11 / 24 if the improper integral exists. log Differential Entropy IT Lecture 5 such that j x k ∈ I ∆ y j ∈ I ∆ By MVT, ∀ k , j ∈ Z , ∃ � k and � ∫ ∫ p ( x k ) = k f X ( x ) dx = ∆ f X ( � x k ) , p ( y j ) = j f Y ( y ) dy = ∆ f Y ( � y j ) . I ∆ I ∆ Observation : lim ∆ → 0 I ([ X ] ∆ ; [ Y ] ∆ ) = I ( X ; Y ) (intuitively), while ∑ ∞ ( ) p ( x k , y j ) [ X ] ∆ ; [ Y ] ∆ = p ( x k , y j ) log p ( x k ) p ( y j ) k , j = −∞ ✚ ∑ log f X , Y ( x k , y j ) ✚ ∞ ( f X , Y ( x k , y j ) ∆ 2 ) ∆ 2 = ✚ y j ) ✚ ∆ 2 f X ( � x k ) f Y ( � k , j = −∞ ∑ ∞ f X , Y ( x k , y j ) log f X , Y ( x k , y j ) = ∆ 2 f X ( � x k ) f Y ( � y j ) k , j = −∞ ∫ ∞ ∫ ∞ f X , Y ( x , y ) log f X , Y ( x , y ) f X ( x ) f Y ( y ) dx dy as ∆ → 0 → −∞ −∞ [ ] f ( X , Y ) Hence, I ( X ; Y ) = E f ( X ) f ( Y )
Entropy and Mutual Information Differential Entropy I-Hsiang Wang 12 / 24 information measures. is nice, these definitions do not provide explicit ways to compute these Remark : Although defining information measures in such a general way are discrete, continuous, etc. between two probability measures, no matter the probability distributions Similar to mutual information, KL divergence can also be defined , where the supremum is taken IT Lecture 5 The mutual information between two random variables X and Y is I Definition 1 (Mutual information) random variables (no necessarily continuous or discrete) as follows. Unlike entropy that is only well-defined for discrete random variables, in Mutual Information general we can define the mutual information between two real-valued ( ) defined as I ( X ; Y ) = sup [ X ] P ; [ Y ] Q P , Q over all pairs of partitions P and Q of R .
Entropy and Mutual Information Differential Entropy 1 Entropy and Mutual Information 2 Differential Entropy 13 / 24 I-Hsiang Wang IT Lecture 5
Entropy and Mutual Information if the (improper) integral exists. I-Hsiang Wang 14 / 24 log Theorem 1 (Mutual information between two continuous r.v.’s) We have the following theorem immediately from the previous discussion: if the (improper) integral exists. log Differential Entropy The conditional differential entropy of a continuous r.v. X given Y , IT Lecture 5 Definition 2 (Differential entropy and conditional differential entropy) Differential Entropy For continuous r.v.’s, it turns out to be useful to define the counterparts of entropy and conditional entropy, as follows: log The differential entropy of a continuous r.v. X with p.d.f. f ( x ) is defined [ ] as h ( X ) ≜ E 1 f ( X ) where ( X , Y ) has joint p.d.f. f ( x , y ) and conditional p.d.f. f ( x | y ) , is [ ] 1 defined as h ( X | Y ) ≜ E f ( X | Y ) [ ] f ( X , Y ) = h ( X ) − h ( X | Y ) . I ( X ; Y ) = E f ( X ) f ( Y )
Entropy and Mutual Information if the I-Hsiang Wang 15 / 24 some points with zero probability). Proposition 1 (Non-negativity of KL divergence) of KL divergence remains. By Jensen’s inequality, it is straightforward to see that the non-negativity Differential Entropy IT Lecture 5 The Kullback-Leibler divergence between two probability density Definition 3 (KL divergence between densities) Kullback-Leibler Divergence [ ] log f ( X ) functions f ( x ) and g ( x ) is defined as D ( f ∥ g ) ≜ E g ( X ) (improper) integral exists. The expectation is taken over r.v. X ∼ f ( x ) . D ( f ∥ g ) ≥ 0 , with equality iff f = g almost everywhere (i.e., except for Note : D ( f ∥ g ) is finite only if the support of f ( x ) is contained in the support of g ( x ) .
Entropy and Mutual Information h I-Hsiang Wang 16 / 24 Proposition 4 (Non-negativity of mutual information) Proposition 3 (Conditioning reduces differential entropy) Differential Entropy X i IT Lecture 5 Proposition 2 (Chain rule) n Properties that Extend to Continuous R.V.’s ∑ ( � X i − 1 ) � h ( X n ) = h ( X , Y ) = h ( X ) + h ( Y | X ) , . i =1 h ( X | Y ) ≤ h ( X ) , h ( X | Y , Z ) ≤ h ( X | Z ) . I ( X ; Y ) ≥ 0 , I ( X ; Y | Z ) ≥ 0 .
Entropy and Mutual Information Differential Entropy I-Hsiang Wang 17 / 24 IT Lecture 5 Examples Example 1 (Differential entropy of a uniform r.v.) 1 For a r.v. X ∼ Unif [ a , b ] , that is, its p.d.f. f X ( x ) = b − a 1 { a ≤ x ≤ b } , its differential entropy h ( X ) = log ( b − a ) . Example 2 (Differential entropy of N (0 , 1) ) 2 π e − x 2 1 For a r.v. X ∼ N (0 , 1) , that is, its p.d.f. f X ( x ) = √ 2 , its differential entropy h ( X ) = 1 2 log (2 π e ) .
Entropy and Mutual Information Differential Entropy New Properties of Differential Entropy Differential entropy can be negative . negative. Hence, the non-negative property of entropy cannot be extended to differential entropy. Scaling will change the differential entropy . an invertible function. 18 / 24 I-Hsiang Wang IT Lecture 5 Since b − a can be made arbitrarily small, h ( X ) = log ( b − a ) can be Consider X ∼ Unif [0 , 1] . Then, 2 X ∼ Unif [0 , 2] . Hence, h ( X ) = log 1 = 0 , h (2 X ) = log 2 = 1 = ⇒ h ( X ) ̸ = h (2 X ) . This is in sharp contrast to entropy: H ( X ) = H ( g ( X ) ) as long as g ( · ) is
Recommend






















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.