
Lecture 4 Artificial Neural Networks Rui Xia T ext M ining Group N - PowerPoint PPT Presentation
Lecture 4 Artificial Neural Networks Rui Xia T ext M ining Group N anjing U niversity of S cience & T echnology rxia@njust.edu.cn Brief History Rosenblatt (1958) created the perceptron, an algorithm for pattern recognition. Neural
Lecture 4 Artificial Neural Networks Rui Xia T ext M ining Group N anjing U niversity of S cience & T echnology rxia@njust.edu.cn
Brief History • Rosenblatt (1958) created the perceptron, an algorithm for pattern recognition. • Neural network research stagnated after machine learning research by Minsky and Papert (1969), who discovered two key issues with the computational machines that processed neural networks. – Basic perceptrons were incapable of processing the exclusive-or circuit. – Computers didn't have enough processing power to effectively handle the work required by large neural networks. • A key trigger for the renewed interest in neural networks and learning was Paul Werbos's (1975) back-propagation algorithm. • Both shallow and deep learning (e.g., recurrent nets) of ANNs have been explored for many years. Machine Learning, NJUST, 2018 2
Brief History • In 2006, Hinton and Salakhutdinov showed how a many-layered feedforward neural network could be effectively pre-trained one layer at a time. • Advances in hardware enabled the renewed interest after 2009. • Industrial applications of deep learning to large-scale speech recognition started around 2010. • Significant additional impacts in image or object recognition were felt from 2011 – 2012. • Deep learning approaches have obtained very high performance across many different natural language processing tasks after 2013. • Till now, deep learning architectures such as CNN, RNN, LSTM, GAN have been applied to a lot of fields, where they produced results comparable to and in some cases superior to human experts. Machine Learning, NJUST, 2018 3
Inspired from Neural Networks Machine Learning, NJUST, 2018 4
Multi-layer Neural Networks Machine Learning, NJUST, 2018 5
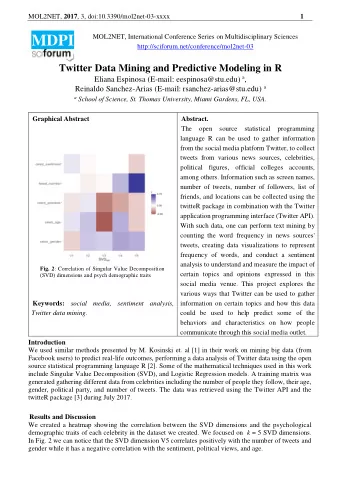
3-layer Forward Neural Networks • ANN Structure • Hypothesis 𝑧 𝑘 = 𝜀(𝛾 𝑘 + 𝜄 ො 𝑘 ) 𝑟 𝛾 𝑘 = 𝑥 ℎ𝑘 𝑐 ℎ ℎ=1 𝑐 ℎ = 𝜀(𝛽 ℎ + 𝛿 ℎ ) 𝑒 𝛽 ℎ = 𝑤 𝑗ℎ 𝑦 𝑗 𝑗=1 Machine Learning, NJUST, 2018 6
Learning algorithm • Training Set 𝑦 1 , 𝑧 1 , 𝑦 2 , 𝑧 2 , … , 𝑦 𝑛 , 𝑧 𝑛 , 𝑦 𝑗 𝜗𝑆 𝑒 , 𝑧 𝑗 𝜗𝑆 𝑚 𝐸 = • Cost function 𝑚 𝐹 𝑙 = 1 (𝑙) 2 (𝑙) − 𝑧 𝑘 2 𝑧 𝑘 ො 𝑘=1 • Parameters 𝑤 𝜗 𝑆 𝑒∗𝑟 , 𝛿 𝜗 𝑆 𝑟 , 𝜕 𝜗 𝑆 𝑟∗𝑚 , 𝜄 𝜗 𝑆 𝑚 • Gradients to calculate 𝜖𝐹 (𝑙) , 𝜖𝐹 (𝑙) , 𝜖𝐹 (𝑙) , 𝜖𝐹 (𝑙) 𝜖𝑤 𝑗ℎ 𝜖𝛿 ℎ 𝜖𝜕 ℎ𝑘 𝜖𝜄 𝑘 Machine Learning, NJUST, 2018 7
Gradient Calculation • Firstly, gradient with respect to 𝜕 ℎ𝑘 : (𝑙) 𝜖𝐹 (𝑙) = 𝜖𝐹 (𝑙) 𝜖 ො 𝑧 𝑘 𝑘 ) ∙ 𝜖(𝛾 𝑘 + 𝜄 𝑘 ) (𝑙) ∙ 𝜖𝜕 ℎ𝑘 𝜖(𝛾 𝑘 + 𝜄 𝜖𝜕 ℎ𝑘 𝜖 ො 𝑧 𝑘 𝜖𝐹 (𝑙) (𝑙) − 𝑧 𝑘 (𝑙) where, (𝑙) = 𝑧 𝑘 ො 𝜖 ො 𝑧 𝑘 (𝑙) 𝜖 ො 𝑧 𝑘 (𝑙) ∙ 1 − ො 𝑘 ) = 𝜀 ′ 𝛾 𝑘 + 𝜄 (𝑙) 𝑘 = 𝜀 𝛾 𝑘 + 𝜄 𝑘 ∙ 1 − 𝜀 𝛾 𝑘 + 𝜄 = ො 𝑧 𝑘 𝑧 𝑘 𝑘 𝜖(𝛾 𝑘 + 𝜄 𝜖(𝛾 𝑘 + 𝜄 𝑘 ) = 𝑐 ℎ 𝜖𝜕 ℎ𝑘 Machine Learning, NJUST, 2018 8
Gradient Calculation (𝑙) 𝜖𝐹 (𝑙) 𝑘 ) = 𝜖𝐹 (𝑙) 𝜖 ො 𝑧 𝑘 𝑃𝑣𝑢𝑞𝑣𝑢𝑀𝑏𝑧𝑓𝑠 = Define: 𝑓𝑠𝑠𝑝𝑠 (𝑙) ∙ 𝑘 𝜖(𝛾 𝑘 + 𝜄 𝜖(𝛾 𝑘 + 𝜄 𝑘 ) 𝜖 ො 𝑧 𝑘 (𝑙) − 𝑧 𝑘 (𝑙) ∙ ො (𝑙) ∙ 1 − ො (𝑙) = 𝑧 𝑘 ො 𝑧 𝑘 𝑧 𝑘 𝜖𝐹 (𝑙) 𝑃𝑣𝑢𝑞𝑣𝑢𝑀𝑏𝑧𝑓𝑠 ∙ 𝑐 ℎ Then: = 𝑓𝑠𝑠𝑝𝑠 𝑘 𝜖𝜕 ℎ𝑘 • Secondly, gradient with respect to 𝜄 𝑘 : (𝑙) 𝜖𝐹 (𝑙) = 𝜖𝐹 (𝑙) 𝜖 ො 𝑧 𝑘 𝑘 ) ∙ 𝜖(𝛾 𝑘 + 𝜄 𝑘 ) (𝑙) ∙ 𝜖𝜄 𝜖(𝛾 𝑘 + 𝜄 𝜖𝜄 𝜖 ො 𝑧 𝑘 𝑘 𝑘 𝑃𝑣𝑢𝑞𝑣𝑢𝑀𝑏𝑧𝑓𝑠 ∙ 1 = 𝑓𝑠𝑠𝑝𝑠 𝑘 Machine Learning, NJUST, 2018 9
Gradient Calculation • Thirdly, gradient with respect to 𝑤 𝑗ℎ : 𝑚 𝜖𝐹 (𝑙) 𝜖𝐹 (𝑙) 𝑘 ) ∙ 𝜖(𝛾 𝑘 + 𝜄 𝑘 ) 𝜖(𝛽 ℎ + 𝛿 ℎ ) ∙ 𝜖(𝛽 ℎ + 𝛿 ℎ ) 𝜖𝑐 ℎ = ∙ 𝜖𝑤 𝑗ℎ 𝜖(𝛾 𝑘 + 𝜄 𝜖𝑐 ℎ 𝜖𝑤 𝑗ℎ 𝑘=1 𝜖𝐹 (𝑙) 𝑃𝑣𝑢𝑞𝑣𝑢𝑀𝑏𝑧𝑓𝑠 where, 𝑘 ) = 𝑓𝑠𝑠𝑝𝑠 𝑘 𝜖(𝛾 𝑘 + 𝜄 𝜖(𝛾 𝑘 + 𝜄 𝑘 ) = 𝜕 ℎ𝑘 𝜖𝑐 ℎ 𝜖𝑐 ℎ 𝜖(𝛽 ℎ + 𝛿 ℎ ) = 𝜀 ′ 𝛽 ℎ + 𝛿 ℎ = δ 𝛽 ℎ + 𝛿 ℎ ∙ 1 − δ 𝛽 ℎ + 𝛿 ℎ = 𝑐 ℎ ∙ 1 − 𝑐 ℎ 𝜖(𝛽 ℎ + 𝛿 ℎ ) (𝑙) = 𝑦 𝑗 𝜖𝑤 𝑗ℎ Machine Learning, NJUST, 2018 10
Gradient Calculation 𝜖𝐹 (𝑙) 𝐼𝑗𝑒𝑒𝑓𝑜𝑀𝑏𝑧𝑓𝑠 = 𝑓𝑠𝑠𝑝𝑠 define: ℎ 𝜖(𝛽 ℎ + 𝛿 ℎ ) 𝑚 𝜖𝐹 (𝑙) 𝑘 ) ∙ 𝜖(𝛾 𝑘 + 𝜄 𝑘 ) 𝜖𝑐 ℎ = ∙ 𝜖(𝛾 𝑘 + 𝜄 𝜖𝑐 ℎ 𝜖(𝛽 ℎ + 𝛿 ℎ ) 𝑘=1 𝑚 𝑃𝑣𝑢𝑞𝑣𝑢𝑀𝑏𝑧𝑓𝑠 ∙ 𝜕 ℎ𝑘 ∙ 𝜀 ′ 𝛽 ℎ + 𝛿 ℎ = 𝑓𝑠𝑠𝑝𝑠 𝑘 𝑘=1 𝑚 𝑃𝑣𝑢𝑞𝑣𝑢𝑀𝑏𝑧𝑓𝑠 ∙ 𝜕 ℎ𝑘 ∙ 𝑐 ℎ ∙ 1 − 𝑐 ℎ = 𝑓𝑠𝑠𝑝𝑠 𝑘 𝑘=1 𝜖𝐹 (𝑙) 𝐼𝑗𝑒𝑒𝑓𝑜𝑀𝑏𝑧𝑓𝑠 ∙ 𝑦 𝑗 (𝑙) then: = 𝑓𝑠𝑠𝑝𝑠 ℎ 𝜖𝑤 𝑗ℎ Machine Learning, NJUST, 2018 11
Gradient Calculation • Finally, gradient with respect to 𝛿 ℎ : 𝑚 𝜖𝐹 (𝑙) 𝜖𝐹 (𝑙) 𝑘 ) ∙ 𝜖(𝛾 𝑘 + 𝜄 𝑘 ) 𝜖𝑐 ℎ ∙ 𝜖 𝛽 ℎ + 𝛿 ℎ = ∙ 𝜖𝛿 ℎ 𝜖(𝛾 𝑘 + 𝜄 𝜖𝑐 ℎ 𝜖 𝛽 ℎ + 𝛿 ℎ 𝜖𝛿 ℎ 𝑘=1 𝐼𝑗𝑒𝑒𝑓𝑜𝑀𝑏𝑧𝑓𝑠 ∙ 1 = 𝑓𝑠𝑠𝑝𝑠 ℎ Machine Learning, NJUST, 2018 12
Back propagation algorithm algorithm flowchart weight updating 𝑛 Input: training set: = (𝑦 𝑙 , 𝑧 𝑙 ) 𝑙=1 𝜕 ℎ𝑘 ≔ 𝜕 ℎ𝑘 − η ∙ 𝜖𝐹 𝑙 learning rate 𝜃 Steps : 𝜖𝜕 ℎ𝑘 1: initialize all parameters within (0,1) 𝑘 − η ∙ 𝜖𝐹 (𝑙) 2: repeat: 𝜄 𝑘 ≔ 𝜄 𝜖𝜄 3: for all 𝑦 𝑙 , 𝑧 𝑙 𝑘 ∈ do: 𝑤 𝑗ℎ ≔ 𝑤 𝑗ℎ − η ∙ 𝜖𝐹 (𝑙) 4: calculate 𝑧 𝑙 𝜖𝑤 𝑗ℎ 5: calculate 𝑓𝑠𝑠𝑝𝑠 𝑃𝑣𝑢𝑞𝑣𝑢𝑀𝑏𝑧𝑓𝑠 : 𝛿 ℎ ≔ 𝛿 ℎ − η ∙ 𝜖𝐹 (𝑙) 6: calculate 𝑓𝑠𝑠𝑝𝑠 𝐼𝑗𝑒𝑒𝑓𝑜𝑀𝑏𝑧𝑓𝑠 : 𝜖𝛿 ℎ 7: update 𝑤 , 𝜄 , 𝑤 and 𝛿 8: end for where η is the learning rate 9: until reach stop condition Output: trained ANN Machine Learning, NJUST, 2018 13
Practice: 3-layer Forward NN with BP • Given the following training data: http://openclassroom.stanford.edu/MainFolder/DocumentPage.php?course=DeepLearning&doc=exercises/ex4/ex4.html • Implement 3-layer Forward Neural Network with Back-Propagation and report the 5-fold cross validation performance ( code by yourself, don’t use Tensorflow); • Compare it with logistic regression and softmax regression. Machine Learning, NJUST, 2018 14
Practice #2: 3-layer Forward NN with BP • Given the following training data: http://openclassroom.stanford.edu/MainFolder/DocumentPage.php?course=DeepLearning&doc=exercises/ex4/ex4.html • Implement multi-layer Forward Neural Network with Back-Propagation and report the 5-fold cross validation performance (code by yourself); • Do that again (by using Tensorflow) • Tune the model by using different numbers of hidden layers and hidden nodes, different activation functions, different cost functions, different learning rates. Machine Learning, NJUST, 2018 15
Questions? Machine Learning, NJUST, 2018 16
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.