
Machine Learning Nave Bayes Model Rui Xia T ext M ining Group N - PowerPoint PPT Presentation
Machine Learning Nave Bayes Model Rui Xia T ext M ining Group N anjing U niversity of S cience & T echnology rxia@njust.edu.cn Nave Bayes Models A Probabilistic Model A Generative Model Known as the Nave Assumption
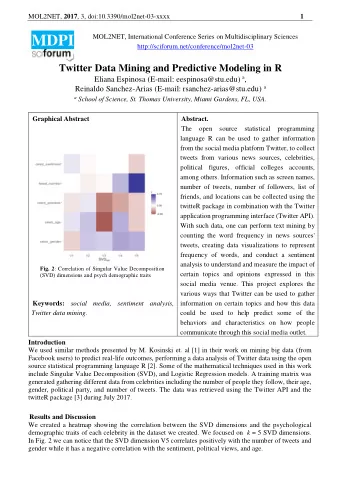
Machine Learning Naïve Bayes Model Rui Xia T ext M ining Group N anjing U niversity of S cience & T echnology rxia@njust.edu.cn
Naïve Bayes Models • A Probabilistic Model • A Generative Model • Known as the “Naïve” Assumption • Suitable for Discrete Distributions • Widely used in Text Classification, Natural Language Processing and Pattern Recognition Machine Learning Course, NJUST 2
Generative vs. Discriminative • Discriminative Model • Generative Model It models the posterior It models the joint probability probability of class label given of class label and observation observation p(y|x) p(x, y), and then use the Bayes rule (p(y|x)=p(x,y)/p(x) ) for prediction. Machine Learning Course, NJUST 3
Naïve Bayes Assumption • A Mixture Model Class prior probability 𝑞 𝑦, 𝑧 = 𝑑 𝑘 = 𝑞 𝑧 = 𝑑 𝑘 𝑞(𝑦|𝑑 𝑘 ) Class-conditional probability • Bag-of-words (BOW) representation 𝑦 = (𝜕 1 , 𝜕 2 , … , 𝜕 |𝑦| ) |𝑦| 𝑞 𝑦|𝑑 𝑘 = 𝑞 𝜕 1 , 𝜕 2 , … , 𝜕 𝑦 𝑑 𝑘 = ෑ 𝑞(𝜕 ℎ |𝑑 𝑘 ) ℎ=1 Having two event models Machine Learning Course, NJUST 4
Multinomial Event Model Machine Learning Course, NJUST 5
Model Description • Hypothesis 𝑞 𝑧 = 𝑑 𝑘 = 𝜌 𝑘 |𝑦| 𝑞 𝑦|𝑑 𝑘 = 𝑞 𝜕 1 , 𝜕 2 , … , 𝜕 𝑦 𝑑 𝑘 = ෑ 𝑞(𝜕 ℎ |𝑑 𝑘 ) ℎ=1 𝑊 𝑊 𝑞(𝑢 𝑗 |𝑑 𝑘 ) 𝑂(𝑢 𝑗 ,𝑦) = ෑ 𝑂(𝑢 𝑗 ,𝑦) = ෑ 𝜄 𝑗|𝑘 𝑗=1 𝑗=1 • Joint Probability Model Parameters 𝑊 𝑂(𝑢 𝑗 ,𝑦) 𝑞 𝑦, 𝑧 = 𝑑 𝑘 = 𝑞 𝑑 𝑘 𝑞 𝑦|𝑑 𝑘 = 𝜌 𝑘 ෑ 𝜄 𝑗|𝑘 𝑗=1 Machine Learning Course, NJUST 6
Likelihood Function • (Joint) Likelihood 𝑂 𝑀 𝜌, 𝜄 = log ෑ 𝑞(𝑦 𝑙 , 𝑧 𝑙 ) 𝑙=1 𝑂 𝐷 = log ෑ 𝐽 𝑧 𝑙 = 𝑑 𝑘 𝑞 𝑧 𝑙 = 𝑑 𝑘 𝑞(𝑦 𝑙 |𝑧 𝑙 = 𝑑 𝑘 ) 𝑙=1 𝑘=1 𝑂 𝐷 = 𝐽 𝑧 𝑙 = 𝑑 𝑘 log 𝑞 𝑧 𝑙 = 𝑑 𝑘 𝑞(𝑦 𝑙 |𝑧 𝑙 = 𝑑 𝑘 ) 𝑙=1 𝑘=1 𝑂 𝐷 𝑊 𝑂(𝑢 𝑗 ,𝑦 𝑙 ) = 𝐽 𝑧 𝑙 = 𝑑 𝑘 log 𝜌 𝑘 ෑ 𝜄 𝑗|𝑘 𝑙=1 𝑘=1 𝑗=1 𝑂 𝐷 𝑊 = 𝐽 𝑧 𝑙 = 𝑑 log𝜌 𝑘 + 𝑂 𝑢 𝑗 , 𝑦 𝑙 log𝜄 𝑗|𝑘 𝑘 𝑙=1 𝑘=1 𝑗=1 Machine Learning Course, NJUST 7
Maximum Likelihood Estimation • MLE Formulation max 𝜌,𝜄 𝑀(𝜌, 𝜄) 𝐷 𝜌 𝑘 = 1 𝑘=1 𝑡. 𝑢. 𝑊 𝜄 𝑗|𝑘 = 1, 𝑘 = 1, … , 𝐷 𝑗=1 • Applying Lagrange multipliers 𝐷 𝐷 𝑊 𝐾 = 𝑀 𝜌, 𝜄 + 𝛽(1 − 𝜌 𝑘 ) + 𝛾 𝑘 (1 − 𝜄 𝑗|𝑘 ) 𝑘=1 𝑘=1 𝑗=1 𝑂 𝐷 𝑊 𝐷 𝐷 𝑊 = 𝐽 𝑧 𝑙 = 𝑑 𝑘 [log𝜌 𝑘 + 𝑂 𝑢 𝑗 , 𝑦 𝑙 log𝜄 𝑗|𝑘 ] + 𝛽 1 − 𝜌 𝑘 + 𝛾 𝑘 1 − 𝜄 𝑗|𝑘 𝑙=1 𝑘=1 𝑗=1 𝑘=1 𝑘=1 𝑗=1 Machine Learning Course, NJUST 8
Close-form MLE Solution • Gradient 𝑂 𝜖𝐾 1 = 𝐽 𝑧 𝑙 = 𝑑 − 𝛽 = 0 𝑘 𝜖𝜌 𝑘 𝜌 𝑘 𝑙=1 𝑂 𝜖𝐾 𝑂 𝑢 𝑗 , 𝑦 𝑙 = 𝐽 𝑧 𝑙 = 𝑑 − 𝛾 𝑘 = 0 𝑘 𝜖𝜄 𝑗|𝑘 𝜄 𝑗|𝑘 𝑙=1 • MLE Solution 𝑂 σ 𝑙=1 𝐽 𝑧 𝑙 = 𝑑 = 𝑂 𝑘 𝑘 𝜌 𝑘 = 𝐷 𝑂 𝑂 σ 𝑙=1 σ 𝑘 ′ =1 𝐽 𝑧 𝑙 = 𝑑 𝑘 𝑂 σ 𝑙=1 𝐽 𝑧 𝑙 = 𝑑 𝑘 𝑂 𝑢 𝑗 , 𝑦 𝑙 𝜄 𝑗|𝑘 = 𝑊 𝑂 σ 𝑙=1 𝑘 σ 𝑗 ′ =1 𝐽 𝑧 𝑙 = 𝑑 𝑂 𝑢 𝑗′ , 𝑦 𝑙 Machine Learning Course, NJUST 9
Laplace Smoothing • In order to prevent from zero probability 𝑊 𝑂(𝑢 𝑗 ,𝑦) 𝑞 𝑦, 𝑧 = 𝑑 𝑘 = 𝜌 𝑘 ෑ 𝜄 𝑗|𝑘 𝑗=1 • Laplace Smoothing 𝑂 σ 𝑙=1 𝐽 𝑧 𝑙 = 𝑑 𝑂 σ 𝑙=1 𝐽 𝑧 𝑙 = 𝑑 𝑘 𝑂 𝑢 𝑗 , 𝑦 𝑙 𝑘 𝜌 𝑘 = 𝜄 𝑗|𝑘 = 𝐷 𝑂 σ 𝑘 ′ =1 σ 𝑙=1 𝐽 𝑧 𝑙 = 𝑑 𝑊 𝑂 σ 𝑗 ′ =1 σ 𝑙=1 𝐽 𝑧 𝑙 = 𝑑 𝑘 𝑂 𝑢 𝑗′ , 𝑦 𝑙 𝑘 𝑂 𝑂 σ 𝑙=1 𝐽 𝑧 𝑙 = 𝑑 𝑘 + 1 σ 𝑙=1 𝐽 𝑧 𝑙 = 𝑑 𝑘 𝑂 𝑢 𝑗 , 𝑦 𝑙 + 1 𝜌 𝑘 = 𝜄 𝑗|𝑘 = 𝐷 𝑂 𝑊 𝑂 σ 𝑘 ′ =1 σ 𝑙=1 𝐽 𝑧 𝑙 = 𝑑 𝑘 + 𝐷 σ 𝑗 ′ =1 σ 𝑙=1 𝐽 𝑧 𝑙 = 𝑑 𝑘 𝑂 𝑢 𝑗′ , 𝑦 𝑙 + 𝑊 Machine Learning Course, NJUST 10
Multi-variate Bernoulli Event Model Machine Learning Course, NJUST 11
Model Description • Hypothesis 𝑞 𝑧 = 𝑑 𝑘 = 𝜌 𝑘 𝑞 𝑦|𝑧 = 𝑑 𝑘 = 𝑞 𝑢 1 , 𝑢 2 , … , 𝑢 𝑊 𝑑 𝑘 𝑊 = ෑ [𝐽 𝑢 𝑗 𝜗𝑦 𝑞 𝑢 𝑗 𝑑 𝑘 + 𝐽( 𝑢 𝑗 ∉𝑦 )(1 − 𝑞 𝑢 𝑗 𝑑 𝑘 )] 𝑗=1 𝑊 = ෑ [𝐽 𝑢 𝑗 𝜗𝑦 𝜈 𝑗|𝑘 + 𝐽(𝑢 𝑗 ∉𝑦)(1 − 𝜈 𝑗|𝑘 )] 𝑗=1 • Joint Probability Model Parameters 𝑊 𝑞 𝑦, 𝑑 𝑘 = 𝜌 𝑘 ෑ [𝐽 𝑢 𝑗 𝜗𝑦 𝜈 𝑗|𝑘 + 𝐽(𝑢 𝑗 ∉𝑦)(1 − 𝜈 𝑗|𝑘 )] 𝑗=1 Machine Learning Course, NJUST 12
Likelihood Function • (Joint) Likelihood 𝑂 𝑀 𝜌, 𝜈 = log ෑ 𝑞(𝑦 𝑙 , 𝑧 𝑙 ) 𝑙=1 𝑂 𝐷 = log 𝐽 𝑧 𝑙 = 𝑑 𝑘 𝑞 𝑦 𝑙 , 𝑧 𝑙 𝑙=1 𝑘=1 𝑂 𝐷 𝑊 = 𝐽 𝑧 𝑙 = 𝑑 𝑘 log𝑞(𝑑 𝑘 ) ෑ 𝐽 𝑢 𝑗 𝜗𝑦 𝑞 𝑢 𝑗 𝑑 𝑘 + 𝐽(𝑢 𝑗 ∉𝑦)(1 − 𝑞 𝑢 𝑗 𝑑 𝑘 ) 𝑙=1 𝑘=1 𝑗=1 𝑂 𝐷 𝑊 = 𝐽 𝑧 𝑙 = 𝑑 log𝜌 𝑘 + 𝐽(𝑢 𝑗 𝜗𝑦 𝑙 ) log𝜈 𝑗|𝑘 + 𝐽 𝑢 𝑗 ∉𝑦 𝑙 log(1 − 𝜈 𝑗|𝑘 ) 𝑘 𝑙=1 𝑘=1 𝑗=1 Machine Learning Course, NJUST 13
Maximum Likelihood Estimation • MLE Formulation max 𝜌,𝜈 𝑀(𝜌, 𝜈) 𝐷 𝑡. 𝑢. 𝜌 𝑘 = 1 𝑘=1 • Applying Lagrange multipliers 𝐷 𝐾 = 𝑀 𝜌, 𝜈 + 𝛽 1 − 𝜌 𝑘 𝑘=1 𝑂 𝐷 𝑊 𝐷 = 𝐽 𝑧 𝑙 = 𝑑 𝑚𝑝𝜌 𝑘 + 𝐽(𝑢 𝑗 𝜗𝑦 𝑙 ) 𝑚𝑝𝜈 𝑗|𝑘 + 𝐽 𝑢 𝑗 ∉𝑦 log(1 − 𝜈 𝑗|𝑘 ) + 𝛽 1 − 𝜌 𝑘 𝑘 𝑙=1 𝑘=1 𝑗=1 𝑘=1 Machine Learning Course, NJUST 14
Close-form MLE Solution • Gradient 𝑂 𝜖𝐾 𝑘 ) 1 = 𝐽(𝑧 𝑙 = 𝑑 − 𝛽 = 0 𝜖𝜌 𝑘 𝜌 𝑘 𝑙=1 𝑂 𝜖𝐾 𝐽 𝑢 𝑗 𝜗𝑦 𝑙 − 𝐽 𝑢 𝑗 ∉𝑦 𝑙 = 𝐽 𝑧 𝑙 = 𝑑 = 0, ∀𝑘 = 1, … , 𝐷. 𝑘 𝜖𝜈 𝑗|𝑘 𝜈 𝑗|𝑘 1 − 𝜈 𝑗|𝑘 𝑙=1 • MLE Solution 𝑂 σ 𝑙=1 𝐽 𝑧 𝑙 = 𝑑 = 𝑂 𝑘 𝑘 𝜌 𝑘 = 𝑂 𝐷 𝑂 σ 𝑙=1 σ 𝑘 ′ =1 𝐽 𝑧 𝑙 = 𝑑 𝑘′ 𝑂 σ 𝑙=1 𝐽 𝑧 𝑙 = 𝑑 𝑘 𝐽 𝑢 𝑗 𝜗𝑦 𝑙 𝜈 𝑗|𝑘 = 𝑂 σ 𝑙=1 𝐽 𝑧 𝑙 = 𝑑 𝑘 Machine Learning Course, NJUST 15
Laplace Smoothing • In order to prevent from zero probability 𝑊 𝑞(𝑦, 𝑑 𝑘 ) = 𝜌 𝑘 ෑ [𝐽 𝑢 𝑗 𝜗𝑦 𝜈 𝑗|𝑘 + 𝐽(𝑢 𝑗 ∉𝑦)(1 − 𝜈 𝑗|𝑘 )] 𝑗=1 • Laplace Smoothing 𝑂 σ 𝑙=1 𝐽 𝑧 𝑙 = 𝑑 𝑂 σ 𝑙=1 𝐽 𝑧 𝑙 = 𝑑 𝑘 𝐽 𝑢 𝑗 𝜗𝑦 𝑙 𝑘 𝜌 𝑘 = 𝜈 𝑗|𝑘 = 𝐷 𝑂 σ 𝑘 ′ =1 σ 𝑙=1 𝐽 𝑧 𝑙 = 𝑑 𝑂 σ 𝑙=1 𝐽 𝑧 𝑙 = 𝑑 𝑘 𝑘 𝑂 𝑂 σ 𝑙=1 σ 𝑙=1 𝐽 𝑧 𝑙 = 𝑑 𝑘 + 1 𝐽 𝑧 𝑙 = 𝑑 𝑘 𝐽 𝑢 𝑗 𝜗𝑦 𝑙 + 1 𝜌 𝑘 = 𝜈 𝑗|𝑘 = 𝐷 𝑂 𝑂 σ 𝑘 ′ =1 σ 𝑙=1 σ 𝑙=1 𝐽 𝑧 𝑙 = 𝑑 𝑘 + 𝐷 𝐽 𝑧 𝑙 = 𝑑 𝑘 + 2 Machine Learning Course, NJUST 16
Text Classification as An Example 17 Machine Learning Course, NJUST
Data sets • Training data • Class labels • Feature vector • Test data Machine Learning Course, NJUST 18
Multinomial Naïve Bayes • Training • Prediction Machine Learning Course, NJUST 19
Multi-variate Bernoulli Naïve Bayes • Training • Prediction Machine Learning Course, NJUST 20
Xia-NB Software • Functions – Written in C++ – Support multinomial and multi-variate Bernoulli event model – Laplace smoothing – Uniform data format like SVM-light/LibSVM – Fast running with sparse representation • Download https://github.com/NUSTM/XIA-NB Machine Learning Course, NJUST 21
Project • Implement naïve Bayes algorithm with – Multinomial event model – Multi-variate Bernoulli model • Running the algorithm based on the training & testing data given in Page 18. • Compare the naïve Bayes algorithm with logistic regression (by using Bag-of-words to represent the data). Machine Learning Course, NJUST 22
Questions? Machine Learning Course, NJUST
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.