Introduction to Machine Learning CART: Growing a Tree Learning - PowerPoint PPT Presentation
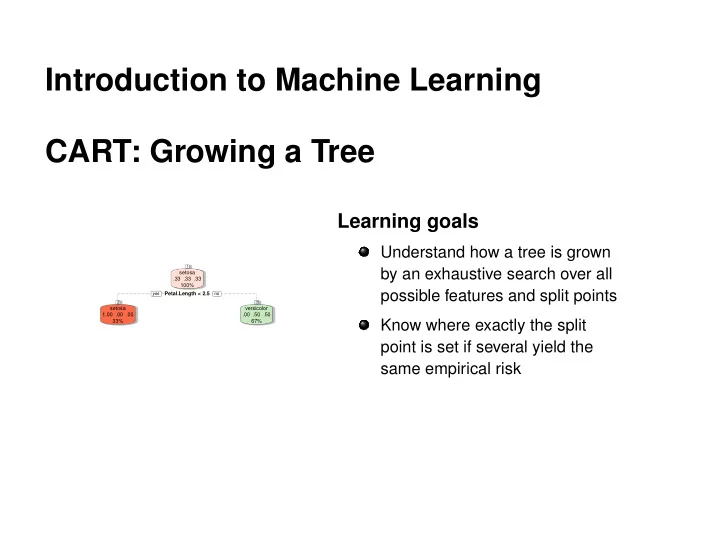
Introduction to Machine Learning CART: Growing a Tree Learning goals Understand how a tree is grown 1 1 by an exhaustive search over all setosa .33 .33 .33 100% possible features and split points Petal.Length < 2.5 Petal.Length <
Introduction to Machine Learning CART: Growing a Tree Learning goals Understand how a tree is grown 1 1 by an exhaustive search over all setosa .33 .33 .33 100% possible features and split points Petal.Length < 2.5 Petal.Length < 2.5 yes yes no no 2 2 3 3 setosa versicolor 1.00 .00 .00 .00 .50 .50 33% 67% Know where exactly the split point is set if several yield the same empirical risk
TREE GROWING We start with an empty tree, a root node that contains all the data. Trees are then grown by recursively applying greedy optimization to each node N . Greedy means we do an exhaustive search : All possible splits of N on all possible points t for all features x j are compared in terms of their empirical risk R ( N , j , t ) . The training data is then distributed to child nodes according to the optimal split and the procedure is repeated in the child nodes. � c Introduction to Machine Learning – 1 / 5
TREE GROWING Start with a root node of all data, then search for a feature and split point that minimizes the empirical risk in the child nodes. Iris Data 2.5 Response 2.0 Petal.Width setosa 1.5 versicolor 1.0 virginica 0.5 0.0 2 4 6 Petal.Length 1 1 setosa .33 .33 .33 100% Petal.Length < 2.5 Petal.Length < 2.5 yes yes no no 2 2 3 3 setosa versicolor 1.00 .00 .00 .00 .50 .50 33% 67% Nodes display their current label distribution here for illustration. � c Introduction to Machine Learning – 2 / 5
TREE GROWING We then proceed recursively for each child node: Iterate over all features, and for each feature over all possible split points. Select the best split and divide data in parent node into left and right child nodes: Iris Data 2.5 Response 2.0 Petal.Width setosa 1.5 versicolor 1.0 virginica 0.5 0.0 2 4 6 Petal.Length 1 1 setosa .33 .33 .33 3 3 100% versicolor Petal.Length < 2.5 Petal.Length < 2.5 yes yes no no .00 .50 .50 67% 2 2 6 6 7 7 setosa versicolor virginica Petal.Width < 1.8 Petal.Width < 1.8 1.00 .00 .00 .00 .91 .09 .00 .02 .98 33% 36% 31% � c Introduction to Machine Learning – 3 / 5
TREE GROWING We then proceed recursively for each child node: Iterate over all features, and for each feature over all possible split points. Select the best split and divide data in parent node into left and right child nodes: Iris Data 2.5 Response 2.0 Petal.Width setosa 1.5 versicolor 1.0 virginica 0.5 0.0 2 4 6 Petal.Length 1 1 setosa .33 .33 .33 3 3 100% versicolor Petal.Length < 2.5 Petal.Length < 2.5 yes yes no no .00 .50 .50 6 6 67% versicolor .00 .91 .09 Petal.Width < 1.8 Petal.Width < 1.8 36% 2 2 12 12 13 13 7 7 setosa versicolor virginica virginica Petal.Length < 5 Petal.Length < 5 1.00 .00 .00 .00 .98 .02 .00 .33 .67 .00 .02 .98 33% 32% 4% 31% � c Introduction to Machine Learning – 4 / 5
SPLIT PLACEMENT 3.5 3.0 Sepal.Width 2.5 2.0 5.0 5.5 6.0 6.5 7.0 Sepal.Length Splits are usually placed at the mid-point of the observations they split: the large margin to the next closest observations makes better generalization on new, unseen data more likely. � c Introduction to Machine Learning – 5 / 5
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.