
Generalized Pattern Matching Micro-Engine Yuanwei Fang*, Raihan - PowerPoint PPT Presentation
Generalized Pattern Matching Micro-Engine Yuanwei Fang*, Raihan Rasool , Dilip Vasudevan*, Andrew A. Chien* Argonne National Laboratory King Faisal University University of Chicago * Big Data Applications Deep Packet
Generalized Pattern Matching Micro-Engine Yuanwei Fang*, Raihan Rasool ‡ , Dilip Vasudevan*, Andrew A. Chien* † Argonne National Laboratory † King Faisal University ‡ University of Chicago *
Big Data Applications ◦ Deep Packet Inspection ◦ Bioinformatics (DNA Alignment) ◦ JSON/XML Parsing ◦ Signal Triggering 2 6/24/2014 UNIVERSITY OF CHICAGO
Deep Packet Inspection High speed network : 100Gb/s Growing number of patterns : 6000 Snort Rules Speed requirement : > 75 Tera DFAops/s Power budget : 200 W Energy efficiency requirement : > 375Gops/J 3 6/24/2014 UNIVERSITY OF CHICAGO
Bioinformatics (DNA Alignment) Genome size : Bioinformatics database: millions of species 130G base pairs Speed requirement : > 1 Tera DFAops/s Power budget : 200 W Energy efficiency requirement : > 5 Gops/J 4 6/24/2014 UNIVERSITY OF CHICAGO
Deterministic Finite Automata (DFA) 5 6/24/2014 UNIVERSITY OF CHICAGO
Programmable Approaches target Intel Xeon E5-2600: 17G DFAops/second with 130W, 0.13Gops/J ; 6 6/24/2014 UNIVERSITY OF CHICAGO
Approach ◦ Workload M input characters(M DFA transitions) N DFA rules perform on the M input characters ◦ Goal Compute N x M transitions efficiently ◦ Approach Parallelize DFA execution Fused Instruction 7 6/24/2014 UNIVERSITY OF CHICAGO
What Is Micro-Engine Generalized Pattern Matching Micro-Engine ( GenPM ) is one micro-engine of 10x10 approach Local Memory I-Cache I-Cache I-Cache I-Cache Basic Micro- Micro- Micro- RISC engine engine engine CPU 2 3 4 I-Cache I-Cache I-Cache I-Cache Micro- Micro- Micro- GenPM engine engine engine 7 8 6 Shared L1 Data Cache 8 6/24/2014 UNIVERSITY OF CHICAGO
GenPM Micro Architecture 9 6/24/2014 UNIVERSITY OF CHICAGO
Fused Instructions: Multi-Step String String a a b b c c 0 0 1 Acc_Vec Acc_Vec buffer buffer Current State Current State A A Q 1 Q 1 Accept Accept ALU ALU D D Q 4 Q 4 address address Local Mem Local Mem ENB ENB Next State Next State 10 6/24/2014 UNIVERSITY OF CHICAGO
Fused Instructions: Multi-Step String a b c 0 1 Acc_Vec buffer Current State A Q 1 Accept ALU D Q 4 address Local Mem ENB Next State 11 6/24/2014 UNIVERSITY OF CHICAGO
Fused Instructions: Multi-Step String String a a b b c c 0 0 1 1 0 Acc_Vec Acc_Vec buffer buffer Current State Current State A A Q 1 Q 1 Accept Accept ALU ALU D D Q 4 Q 4 address address Local Mem Local Mem ENB ENB Next State Next State 12 6/24/2014 UNIVERSITY OF CHICAGO
Fused Instructions: Multi-Step String String a a b b c c 0 0 1 1 0 Acc_Vec Acc_Vec buffer buffer Acc_Vec Current State Current State A A Q 1 Q 1 Accept Accept ALU ALU D D Q 4 Q 4 address address Local Mem Local Mem CHECK ENB ENB Next State Next State 13 6/24/2014 UNIVERSITY OF CHICAGO
Parallel DFA: Vector Instruction SSE ADD + + + + + + + 14 6/24/2014 UNIVERSITY OF CHICAGO
Parallel DFA: Vector Instruction GMVSNEXT DFAop DFAop DFAop DFAop DFAop DFAop DFAop 15 6/24/2014 UNIVERSITY OF CHICAGO
GenPM Code Example Data movement Multi-step parallel DFA execution Find precise matching position 16 6/24/2014 UNIVERSITY OF CHICAGO
Methodology • Design space: Parallelism and step length • Baseline • 32-bit 6-stage in-order RISC • 4GB DDR3 DRAM • 32KB L1 I-cache, 24KB L1 D-cache, 512KB L2 (modeled on Intel Silverthorne) • GenPM • 1MB Local memory (up to 64 banks) • Vector and Fused Instructions • Performance/Power Model • Core : 32nm synthesis by Synopsys Processor Designer • Memories : MARSSX86/CACTI 6 + DRAMSim2 • Workload • 64 Snort rules from 2.9.5.6 snapshot, 10KB random network dump 17 6/24/2014 UNIVERSITY OF CHICAGO
Performance Speedup 3000 GenPM_8way GenPM_64way 2498 speedup versus RISC 2500 1947 2000 1500 1000 289 300 500 243 36 0 1 8 16 step length 18 6/24/2014 UNIVERSITY OF CHICAGO
Energy Efficiency GenPM_8way GenPM_64way energy improvement versus RISC 1200 980 861 1000 800 600 400 213 174 151 200 31 0 1 8 16 step length 19 6/24/2014 UNIVERSITY OF CHICAGO
Throughput/watt (absolute) Throughput/watt 40 GenPM_8way GenPM_64way 35 Throughput per watt(Gops/J) 30 25 20 15 10 5 0 1 8 16 step length Scale to a 75W chip, GenPM delivers > 2.6 Tera DFAops/second 20 6/24/2014 UNIVERSITY OF CHICAGO
Energy Breakdown 100% 90% 80% 70% total energy 60% 50% 40% LM_max = 30% 83% 20% 10% 0% RISC GenPM_8B_1S GenPM_8B_8S GenPM_8B_16S GenPM_64B_1S GenPM_64B_8S GenPM_64B_16S LM L1_I L1_D L2 DRAM Core 21 6/24/2014 UNIVERSITY OF CHICAGO
General Comparison 22 6/24/2014 UNIVERSITY OF CHICAGO
Related Work ASIC: [Brodie, et.al. ISCA 2006], [Titanic System RXP], [ Cisco SCE ] FPGA: [Yang Xu, et.al. ANCS 2011], [ T Song, et.al. INFOCOM 2008], [I Sourdis et.al. VLSI 2008] CPU: [Mytkowicz et.al. ASPLOS 2014 ] , [ Intel HyperScan] GPU: [Vasiliadis G, et.al. CCS 2011], [ Lin CH, et.al. INFOCOM 2012] SoC: [C Johnson et.al. ISSCC 2010 ], [ Cavium Octeon ], [ IBM PowerEN ] 23 6/24/2014 UNIVERSITY OF CHICAGO
Summery • GenPM is a high performance and energy efficient accelerator for pattern matching workloads • ISA exploits parallelism and multi-step execution • Scale to a 75W chip, GenPM delivers > 2.6 Tera DFAops/second • GenPM approaches ASIC efficiency and integrates it into a programmable core 24 6/24/2014 UNIVERSITY OF CHICAGO
Future Work • DFA table compression • Scale up with multiple GenPM micro-engines • Explore more applications 25 6/24/2014 UNIVERSITY OF CHICAGO
Acknowledgements • Defense Advanced Research Projects Agency (DARPA) • Agilent Technologies (now Keysight Technologies) • Synopsys Academic program • Dr. Tung Hoang and members of the Large Scale Systems Group in the Department of Computer Science 26 6/24/2014 UNIVERSITY OF CHICAGO
Recommend













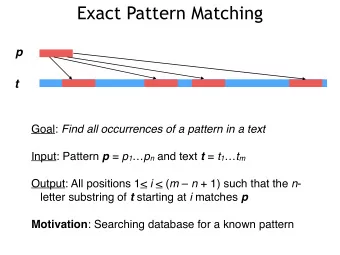

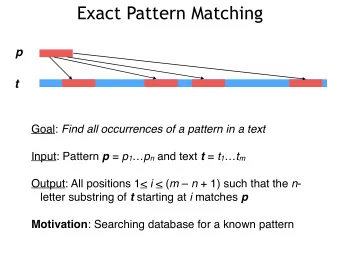





![Operational Practices Internet Security [1] VU Engin Kirda engin@infosys.tuwien.ac.at](https://c.sambuz.com/792737/operational-practices-s.webp)


More recommend
Explore More Topics
Stay informed with curated content and fresh updates.