COMP9032: Microprocessors and Interfacing Processor organisation - PowerPoint PPT Presentation
Overview COMP9032: Microprocessors and Interfacing Processor organisation Instruction execution cycles Instruction Execution and Pipelining Pipelining http://www.cse.unsw.edu.au/~cs9032 Lecturer: Hui Wu Session 2, 2008 2
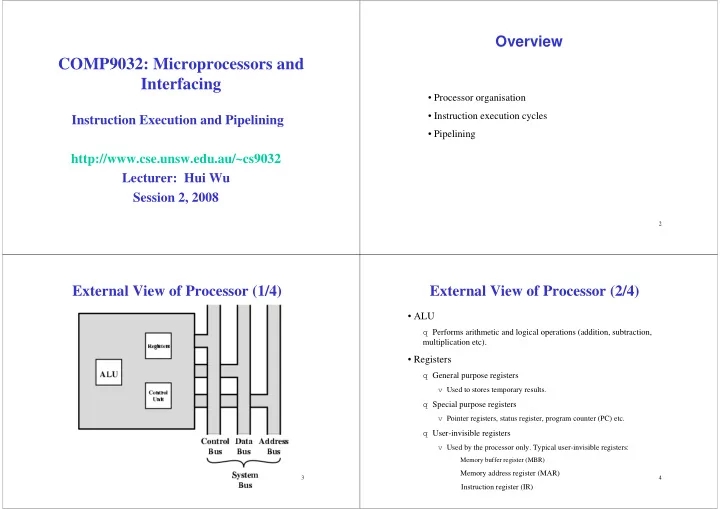
Overview COMP9032: Microprocessors and Interfacing • Processor organisation • Instruction execution cycles Instruction Execution and Pipelining • Pipelining http://www.cse.unsw.edu.au/~cs9032 Lecturer: Hui Wu Session 2, 2008 2 External View of Processor (1/4) External View of Processor (2/4) • ALU q Performs arithmetic and logical operations (addition, subtraction, multiplication etc). • Registers q General purpose registers v Used to stores temporary results. q Special purpose registers v Pointer registers, status register, program counter (PC) etc. q User-invisible registers v Used by the processor only. Typical user-invisible registers: � Memory buffer register (MBR) � Memory address register (MAR) 3 4 � Instruction register (IR)
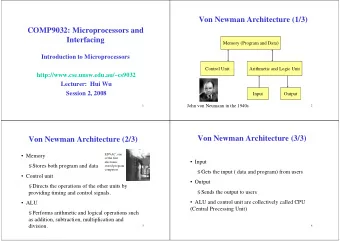
External View of Processor (3/4) External View of Processor (4/4) • Control unit • Buses q Controls the flow of information through the processor, and q Data bus coordinates the activities of other units within it. v Transfers data between the processor and other components (memory, I/O devices). q Its functions vary with its internal architecture. q Address bus v On a regular processor that executes x86 instructions natively, the control unit performs the tasks of fetching, decoding, v Transfers the address from the processor to other components managing execution and then storing results. (memory, I/O devices). v On a processor with a RISC core the control unit has q Control bus significantly more work to do. v Transfers the control signals between the processor and other components (memory, I/O devices). q Details will be covered later. 5 6 Internal View of Processor (1/2) Internal View of Processor (2/2) • Status flags q Indicate the intermediate or final state or outcome of arithmetic and logical operations. q Example flags include V (2’s complement oVerflow), S (Sign), Z (Zero) and C (Carry). • Shifter q Performs shift operation. • Complementer q Computes 2’s complement. 7 8
Register Organization User Visible Registers May be referenced by means of the machine instructions. • space (temporary storage) for Processor • General Purpose • User-visible registers • Data • User-invisible registers • Address • Control and status registers • Condition Codes • Number and function vary between processor designs • One of the major design decisions • Top level of memory hierarchy 9 10 General Purpose Registers Address Registers • May be true general purpose (any general-purpose register can contain the operand for any opcode) • May be general purpose, or dedicated to a particular addressing mode. • May be restricted (registers for floating-point and stack operations) • Segment pointers • May be used for data or addressing q CS and DS in Pentium processors. q Data • Index registers v Also called accumulator q X, Y and Z in AVR. v r1~r31 in AVR. • Stack pointer q Addressing q SP in AVR. v Segment registers 11 12
Program Status Registers General Purpose vs. Specialized • A set of bits storing key flags of the current program execution • Make them general purpose • May be stored in one register or set of registers q Increase flexibility and programmer options q Increase instruction size & complexity • Typical flags • Make them specialized q Sign q Smaller (faster) instructions q Zero q Less flexibility q Carry q Equal q Overflow q Interrupt enable/disable q Operating modes 13 14 Operating Modes Example Register Organizations � Varies with processors. � Typical operating modes: q Supervisor mode v Allows privileged instructions to execute v Used by operating system v Not available to user programs q User mode v Privileged instructions cannot be executed v Used by user program 15 16
Processor Cycle Instruction Cycle • The instruction execution cycle is triggered by the clock • All modern processors are synchronous machines. cycle, but has several stages: • Their timing is controlled by an external “clock” signal. q Each stage is triggered by successive clock pulses q This is just a square electric pulse that is supplied to the processor q The exact timing depends on the details of a particular (and memory etc) by an external source time. processor q A processor running at 1GHz receives 10 9 clock pulses per second. • A complete instruction cycle usually takes several clock cycles to execute. v One pulse lasts 0.0000000001 second. • The instruction cycle is divided into several stages. q The number of stages vary with processors. Time • The processor operations are therefore broken up in cycles. 17 18 Instruction Cycle with Indirect Indirect Cycle • May require memory access to fetch operands. • Indirect addressing requires more memory accesses. • Can be thought of as additional instruction subcycle. 19 20
Data Flow (Instruction Fetch) Instruction Cycle State Diagram • Depends on CPU design • In general, Fetch: q PC contains address of next instruction q Address moved to MAR q Address placed on address bus q Control unit requests memory read q Result placed on data bus, copied to MBR, then to IR q Meanwhile PC incremented by 1 21 22 Data Flow (Data Fetch) Data Flow (Fetch Diagram) • IR is examined. • If indirect addressing, indirect cycle is performed. q Memory address is transferred to MAR. q Control unit requests memory read. q Result (address of operand) moved to MBR. 23 24
Data Flow (Indirect) Data Flow (Execute) • May take many forms • Depends on instruction being executed • May include q Memory read/write q Input/Output q Register transfers q ALU operations 25 26 Data Flow (Interrupt) Data Flow (Interrupt) • Current PC saved to allow resumption after interrupt • Contents of PC copied to MBR • Special memory location (e.g. stack pointer) loaded to MAR • MBR written to memory • PC loaded with address of interrupt handling routine • Next instruction (first of interrupt handler) can be fetched 27 28
Instruction Pipelining Instruction Prefetch • Break the instruction cycle into stages • Fetch accesses main memory • Execution usually does not access main memory • Simultaneously work on each stage • Can fetch next instruction during execution of current instruction q This is called instruction prefetch. 29 30 Two Stage Instruction Pipeline Two Stage Instruction Pipeline Break instruction cycle into two stages: • But not doubled: • FI: Fetch instruction q Fetch usually shorter than execution • EI: Execute instruction q If execution involves memory accessing, the fetch stage has to wait q Any jump or branch means that prefetched instructions are Clock cycle → 1 2 3 4 5 6 7 not the required instructions Instruction i FI EI • Add more stages to improve performance Instruction i+1 FI EI Instruction i+2 FI EI Instruction i+3 FI EI Instruction i+4 FI EI 31 32
Six Stage Pipelining Timing for Six Stage Pipeline • Fetch instruction (FI) • Decode instruction (DI) • Calculate operands (CO) • Fetch operands (FO) • Execute instructions (EI) • Write operand (WO) 33 34 Theoretical Performance of Pipeline The More Stages, the Better? � An ideal pipeline divides an instruction cycle into k stages. � The overhead in moving information between pipeline stages and synchronization between pipeline stages increases with the q Each stage requires 1 time unit number of pipeline stages. q The instruction cycle requires k time units � For n instructions, the execution times: � Pipeline hazards make it difficult to keep a large pipeline at the maximum rate. q With no pipelining: nk time units q With pipelining: k + (n-1) time units � Speedup of a k-stage pipeline is q S = nk / [k+(n-1)] ≈ k (for large n) 35 36
Pipeline Hazards Structural Hazards � A structural hazard occurs when multiple instructions need a � Pipeline hazards are situations that prevent the next instruction resource ( e.g. memory) at the same time. in the instruction stream from executing during its designated clock cycles. Instruction cycle → 1 2 3 4 5 6 7 8 9 10 11 12 q The instruction is said to be stalled. q If an instruction is stalled, all the following instructions are also LD R10, X installed. Instruction i+1 � Types of pipeline hazards: Instruction i+2 Structural hazards Instruction i+3 q Data hazards Instruction i+4 q Control hazards q Instruction i+5 Instruction i+3 is stalled by one clock cycle 37 38 Data Hazards Control Hazards � A data hazard occurs when one instruction needs the result of � Control hazards are caused by branch instructions. Consider another instruction, but the result is not available yet. the following example: SUB R10, R9 MULT R2, R3 R1:R0 ← R2*R3 ADD R4, R0 R4 ← R4+R0 BRGE CS2121 SUB R12, R11 Instruction cycle → 1 2 3 4 5 6 7 8 9 10 11 ••• MULT R2, R3 CS2121: ADD R2, R1 ADD R4, R0 Instruction i+2 ADD R4, R0 is stalled by two clock cycles 39 40
Recommend






















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.