
Bounded in inference non-iteratively; ; Min ini-bucket t el - PowerPoint PPT Presentation
Bounded in inference non-iteratively; ; Min ini-bucket t el eliminatio ion COMPSCI 276,Spring 2017 Set 8: Rina Dechter Reading: Class Notes (8), Darwiche chapters 14 Agenda Mini-bucket elimination Weighted Mini-bucket
Bounded in inference non-iteratively; ; Min ini-bucket t el eliminatio ion COMPSCI 276,Spring 2017 Set 8: Rina Dechter Reading: Class Notes (8), Darwiche chapters 14
Agenda • Mini-bucket elimination • Weighted Mini-bucket • Mini-clustering • Iterative Belief propagation • Iterative-join-graph propagation 2
Probabilistic Inference Tasks ▪ Belief updating: BEL(X ) P(X x | evidence) i i i ▪ Finding most probable explanation (MPE) x * arg max P( x , e) x ▪ Finding maximum a-posteriory hypothesis A X : * * (a ,..., a ) arg max P( x , e) 1 k hypothesis variables a X/A ▪ Finding maximum-expected-utility (MEU) decision D X : decision variables * * (d ,..., d ) arg max P( x , e) U( x ) U 1 k ( ) : x utility function d X/D 3
Queries • Probability of evidence (or partition function) n P e P x i pa Z i C ( ) ( | ) | ( ) i e i X e i var( ) 1 X i • Posterior marginal (beliefs): n P x pa ( | ) | j j e P x e ( , ) X e X j var( ) 1 P x e i ( | ) i i n P e ( ) P x pa ( | ) | j j e X e j var( ) 1 • Most Probable Explanation x * arg max P( x , e) x
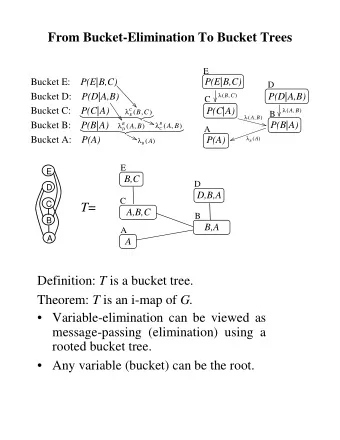
Bucket Elimination Query: Elimination Order: d,e,b,c A P a e P a e ( | 0 ) ( , 0 ) A P a e P a P b a P c a P d a b P e b c B ( , 0 ) ( ) ( | ) ( | ) ( | , ) ( | , ) B C C c b e d , , 0 , P a P c a P b a P e b c P d a b ( ) ( | ) ( | ) ( | , ) ( | , ) D E D E c b e d 0 Original Functions Messages Bucket Tree D E D,A,B E,B,C f a b P d a b P d a b ( , ) ( | , ) D: ( | , ) D f D a b f E b c ( , ) ( , ) d P e b c f E b c P e b c ( | , ) ( , ) ( 0 | , ) E: B B,A,C f a c P b a f a b f b c P b a ( , ) ( | ) ( , ) ( , ) ( | ) B: B D E f B a c ( , ) b P c a f a P c a f a c ( | ) ( ) ( | ) ( , ) C: C B C c C,A P a e p A f a ( , 0 ) ( ) ( ) P ( a A: ) C f C ( a ) A A Time and space exp(w*) 5
Finding MPE max P( x ) x Algorithm elim-mpe (Dechter 1996) : is replaced by max MPE P a P c a P b a P d a b P e b c max ( ) ( | ) ( | ) ( | , ) ( | , ) a e d c b , , , , max Elimination operator b bucket B: P(b|a) P(d|b,a) P(e|b,c) B bucket C: P(c|a) C bucket D: h C (a, d, e) D h D bucket E: e=0 (a, e) E W*=4 h E bucket A: P(a) (a) ”induced width” A (max clique size) MPE 6
Generating the MPE-tuple 5. b' arg max P(b | a' ) B: P(b|a) P(d|b,a) P(e|b,c) b P(d' | b, a' ) P(e' | b, c' ) h B (a, d, c, e) 4. c' arg max P(c | a' ) C: P(c|a) c B h (a' , d' , c, e' ) h C (a, d, e) D: C 3. d' arg max h (a' , d, e' ) d h D (a, e) E: e=0 2. e' 0 A: P(a) h E (a) E 1. a' arg max P(a) h (a) a Return (a' , b' , c' , d' , e' ) 7
Approximate Inference • Metrics of evaluation • Absolute error : given e>0 and a query p= P(x|e), an estimate r has absolute error e iff |p-r|<e • Relative error : the ratio r/p in [1-e,1+e]. • Dagum and Luby 1993: approximation up to a relative error is NP- hard. • Absolute error is also NP-hard if error is less than .5 8
Mini-Buckets: “Local Inference” • Computation in a bucket is time and space exponential in the number of variables involved • Therefore, partition functions in a bucket into “mini - buckets” on smaller number of variables 9
Mini-Bucket Approximation: MPE task Split a bucket into mini-buckets =>bound complexity X X h g r n r n O e O e E xp o ne ntia l c o m p le xity d e c re a s e : O (e ) ( ) ( ) 10
Mini-Bucket Elimination Mini-buckets max B Π max B Π bucket B: F(a,b) F(b,c) F(b,d) F(b,e) A h B (a,c) F(c,e) F(a,c) bucket C: B C F(a,d) h B (d,e) bucket D: E D h C (e,a) h D (e,a) e = 0 bucket E: h E (a) bucket A: We can generate a solution s going L = lower bound forward as before U= F(s) 12
Mini-Bucket Elimination mini-buckets min 𝐶′ 𝑔(∙) min 𝐶 𝑔(∙) 𝑔 𝑏, 𝑐′ 𝑔 𝑐′, 𝑑 𝑔 𝑐, 𝑒 𝑔 𝑐, 𝑓 bucket B: A A 𝜇 𝐶→𝐷 (𝑏, 𝑑) 𝑔 𝑑, 𝑓 bucket C: 𝑔 𝑑, 𝑏 𝑔 𝑏, 𝑒 𝜇 𝐶→𝐸 (𝑒, 𝑓) bucket D: B C B C B’ 𝜇 𝐷→𝐹 (𝑏, 𝑓) 𝜇 𝐸→𝐹 (𝑏, 𝑓) bucket E: D D E E 𝑔 𝑏 𝜇 𝐹→𝐵 (𝑏) bucket A: L = lower bound [Dechter and Rish, 1997; 2003]
Semantics of Mini-Bucket: Splitting a Node Variables in different buckets are renamed and duplicated (Kask et. al. , 2001), (Geffner et. al. , 2007), (Choi, Chavira, Darwiche , 2007) After Splitting: Before Splitting: Network N' Network N U U Û 14 14
Relaxed Network Example 15
MBE-MPE(i): Algorithm MBE-mpe • Input : I – max number of variables allowed in a mini-bucket • Output : [lower bound (P of suboptimal solution), upper bound] Example: MBE-mpe(3) versus BE-mpe max variables in a mini-bucket B: 𝑔 𝑏, 𝑐 𝑔 𝑐, 𝑑 𝑔 𝑐, 𝑒 𝑔 𝑐, 𝑓 B: 𝑔 𝑏, 𝑐 𝑔 𝑐, 𝑑 𝑔 𝑐, 𝑒 𝑔 𝑐, 𝑓 3: 𝜇 𝐶→𝐷 (𝑏, 𝑑) 𝑔 𝑑, 𝑏 𝑔 𝑑, 𝑓 𝜇 𝐶→𝐷 (𝑏, 𝑑, 𝑒, 𝑓) 𝑔 𝑑, 𝑓 C: C: 𝑔 𝑑, 𝑏 3: 𝑔 𝑏, 𝑒 𝜇 𝐶→𝐸 (𝑒, 𝑓) 𝑔 𝑏, 𝑒 𝜇 𝐷→𝐸 (𝑏, 𝑒, 𝑓) D: D: 3: 𝜇 𝐷→𝐹 (𝑏, 𝑓) 𝜇 𝐸→𝐹 (𝑏, 𝑓) 𝜇 𝐸→𝐹 (𝑏, 𝑓) E: E: 2: 𝑔 𝑏 𝑔 𝑏 𝜇 𝐹→𝐵 (𝑏) 𝜇 𝐹→𝐵 (𝑏) A: A: 1: 𝑥 ∗ = 4 𝑥 ∗ = 2 U = Upper bound OPT [Dechter and Rish, 1997]
Ƹ Ƹ Mini-Bucket Decoding mini-buckets min 𝐶 𝑔(∙) min 𝐶 𝑔(∙) 𝑐 = arg min 𝑐 𝑔 ො 𝑏, 𝑐 + 𝑔 𝑐, Ƹ 𝑑 bucket B: 𝑔 𝑏, 𝑐 𝑔 𝑐, 𝑑 𝑔 𝑐, 𝑒 𝑔 𝑐, 𝑓 +𝑔 𝑐, መ 𝑒 + 𝑔(𝑐, Ƹ 𝑓) bucket C: 𝜇 𝐶→𝐷 (𝑏, 𝑑) 𝑔 𝑑, 𝑏 𝑔 𝑑, 𝑓 𝑑 = arg min 𝜇 𝐶→𝐷 ො 𝑏, 𝑑 + 𝑔 𝑑, ො 𝑏 + 𝑔(𝑑, Ƹ 𝑓) 𝑑 𝑔 𝑏, 𝑒 𝜇 𝐶→𝐸 (𝑒, 𝑓) bucket D: መ 𝑒 = arg min 𝑒 𝑔 ො 𝑏, 𝑒 + 𝜇 𝐶→𝐸 (𝑒, Ƹ 𝑓) 𝜇 𝐷→𝐹 (𝑏, 𝑓) 𝜇 𝐸→𝐹 (𝑏, 𝑓) bucket E: 𝑓 = arg min 𝜇 𝐷→𝐹 (ො 𝑏, 𝑓) + 𝜇 𝐸→𝐹 (ො 𝑏, 𝑓) 𝑓 𝑔 𝑏 𝑏 = arg min ො 𝑏 𝑔 𝑏 + 𝜇 𝐹→𝐵 (𝑏) bucket A: 𝜇 𝐹→𝐵 (𝑏) Greedy configuration = upper bound L = lower bound [Dechter and Rish, 2003] ECAI 2016
(i,m)-Patitionings 18
MBE(i,m), MBE(i) • Input: Belief network ( ) P ,..., P n 1 • Output: upper and lower bounds • Initialize: put functions in buckets along ordering • Process each bucket from p=n to 1 • Create (i,m)-partitions • Process each mini-bucket • (For mpe): assign values in ordering d • Return: mpe-configuration, upper and lower bounds 19
Partitioning, Refinements 21
Properties of MBE-mpe(i) • Complexity: O(r exp(i)) time and O(r exp(i)) space. • Accuracy: determined by upper/lower (U/L) bound. • As i increases, both accuracy and complexity increase. • Possible use of mini-bucket approximations: • As anytime algorithms • As heuristics in best-first search 22
Anytime Approximation 23
MBE for Belief Updating and for Probability of Evidence or Partition Function • Idea mini-bucket is the same: • • f x g x f x g x ( ) ( ) ( ) ( ) X X X • • f x g x f x g X ( ) ( ) ( ) max ( ) X X X • So we can apply a sum in each mini-bucket, or better, one sum and the rest max, or min (for lower-bound) • MBE-bel-max(i,m), MBE-bel-min(i,m) generating upper and lower-bound on beliefs approximates BE-bel • MBE-map(i,m): max buckets will be maximized, sum buckets will be sum-max. Approximates BE- map. 24
Normalization • MBE-bel computes upper/lower bound on the joint marginal distributions. We sometime use normalization of the approximation, but then no guarantee. The problem is that we have to approximate also P(e). 26
Empirical Evaluation (Dechter and Rish, 1997; Rish thesis, 1999) • Randomly generated networks • Uniform random probabilities • Random noisy-OR • CPCS networks • Probabilistic decoding Comparing MBE-mpe and anytime-mpe versus BE-mpe 27
Methodology for Empirical Evaluation (for mpe) • U/L – accuracy • Better (U/mpe) or mpe/L • Benchmarks: Random networks • Given n,e,v generate a random DAG • For xi and parents generate table from uniform [0,1], or noisy-or • Create k instances. For each, generate random evidence, likely evidence • Measure averages 28
Recommend









![procedure SERIAL MIN ( A , n ) 1. 2. begin 3. min = A [ 0 ] ; 4. for i := 1 to n 1 do 5.](https://c.sambuz.com/901885/procedure-serial-min-a-n-1-2-begin-3-min-a-0-4-for-i-1-to-s.webp)












More recommend
Explore More Topics
Stay informed with curated content and fresh updates.