
> b x 2 w 3 x 3 Neuroscience 101 CMPSCI 689 Subhransu Maji - PowerPoint PPT Presentation
So far in the class Decision trees ! Inductive bias: use a combination of small number of features ! Nearest neighbor classifier ! Perceptron Inductive bias: all features are equally good Perceptrons Today ! Subhransu Maji
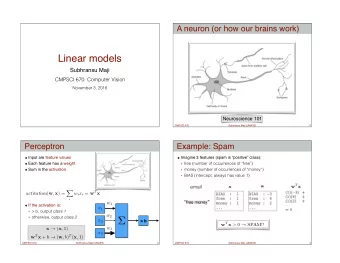
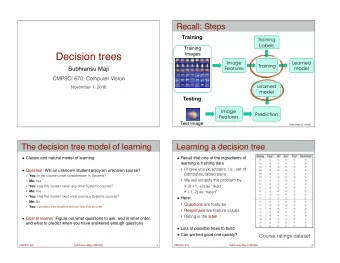
So far in the class Decision trees ! ‣ Inductive bias: use a combination of small number of features ! Nearest neighbor classifier ! Perceptron ‣ Inductive bias: all features are equally good Perceptrons Today ! Subhransu Maji ‣ Inductive bias: use all features, but some more than others CMPSCI 689: Machine Learning 3 February 2015 5 February 2015 CMPSCI 689 Subhransu Maji (UMASS) 2 /19 A neuron (or how our brains work) Perceptron Input are feature values ! Each feature has a weight ! Sum in the activation ! ! ! ! X w i x i = w T x activation( w , x ) = ! ! i w 1 If the activation is: ! x 1 ‣ > b, output class 1 w 2 ‣ otherwise, output class 2 Σ > b x 2 w 3 x 3 Neuroscience 101 CMPSCI 689 Subhransu Maji (UMASS) 3 /19 CMPSCI 689 Subhransu Maji (UMASS) 4 /19
Perceptron Example: Spam Input are feature values ! Imagine 3 features (spam is “positive” class): ! ‣ free (number of occurrences of “free”) Each feature has a weight ! Sum in the activation ! ‣ money (number of occurrences of “money”) ‣ BIAS (intercept, always has value 1) ! ! w T x email w x ! X w i x i = w T x activation( w , x ) = ! ! i w 1 If the activation is: ! x 1 ‣ > b, output class 1 w 2 ‣ otherwise, output class 2 Σ > b x 2 w T x > 0 → SPAM!! x → ( x , 1) w 3 x 3 w T x + b → ( w , b ) T ( x , 1) CMPSCI 689 Subhransu Maji (UMASS) 4 /19 CMPSCI 689 Subhransu Maji (UMASS) 5 /19 Geometry of the perceptron Learning a perceptron Input: training data ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) In the space of feature vectors ! ‣ examples are points (in D dimensions) Perceptron training algorithm [Rosenblatt 57] ‣ an weight vector is a hyperplane (a D-1 dimensional object) w ← [0 , . . . , 0] Initialize ! ‣ One side corresponds to y=+1 for iter = 1,…,T ! y i x ‣ Other side corresponds to y=-1 w ‣ for i = 1,..,n ! x i Perceptrons are also called as linear classifiers • predict according to the current model ! ⇢ +1 ! if w T x i > 0 y i = ˆ ! if w T x i ≤ 0 w − 1 ! • if , no change ! y i = ˆ y i y i = − 1 • else, w ← w + y i x i w T x = 0 CMPSCI 689 Subhransu Maji (UMASS) 6 /19 CMPSCI 689 Subhransu Maji (UMASS) 7 /19
Learning a perceptron Properties of perceptrons Input: training data ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) Separability: some parameters will classify the training data perfectly ! Perceptron training algorithm [Rosenblatt 57] ! w ← [0 , . . . , 0] Initialize ! Convergence: if the training data is separable for iter = 1,…,T ! y i x then the perceptron training will eventually w ‣ for i = 1,..,n ! converge [Block 62, Novikoff 62] ! x i • predict according to the current model ! ! ⇢ +1 ! Mistake bound: the maximum number of if w T x i > 0 mistakes is related to the margin y i = ˆ ! if w T x i ≤ 0 − 1 ! assuming, || x i || ≤ 1 • if , no change ! y i = ˆ y i y i = − 1 1 • else, #mistakes < w ← w + y i x i δ 2 ⇥ y i w T x i ⇤ δ = max w min ( x i ,y i ) error driven, online, activations increase for +, randomize such that, || w || = 1 CMPSCI 689 Subhransu Maji (UMASS) 7 /19 CMPSCI 689 Subhransu Maji (UMASS) 8 /19 Review geometry Proof of convergence Let, ˆ w be the separating hyperplane with margin δ CMPSCI 689 Subhransu Maji (UMASS) 9 /19 CMPSCI 689 Subhransu Maji (UMASS) 10 /19
Proof of convergence Proof of convergence Let, ˆ w be the separating hyperplane with margin δ Let, ˆ w be the separating hyperplane with margin δ w is getting closer w is getting closer w T ⇣ ⌘ w T ⇣ ⌘ w T w ( k ) = ˆ w ( k − 1) + y i x i w T w ( k ) = ˆ w ( k − 1) + y i x i update rule update rule ˆ ˆ w T y i x i w T y i x i w T w ( k − 1) + ˆ w T w ( k − 1) + ˆ algebra algebra = ˆ = ˆ w T w ( k − 1) + δ w T w ( k − 1) + δ definition of margin definition of margin ≥ ˆ ≥ ˆ || w ( k ) || ≥ k δ || w ( k ) || ≥ k δ ≥ k δ ≥ k δ || w ( k ) || 2 = || w ( k − 1) + y i x i || 2 bound the norm update rule ≤ || w ( k − 1) || 2 + || y i x i || 2 triangle inequality ≤ || w ( k − 1) || 2 + 1 norm √ || w ( k ) || ≤ k ≤ k CMPSCI 689 Subhransu Maji (UMASS) 10 /19 CMPSCI 689 Subhransu Maji (UMASS) 10 /19 Proof of convergence Limitations of perceptrons Let, ˆ w be the separating hyperplane with margin δ Convergence: if the data isn’t separable, w is getting closer w T ⇣ ⌘ the training algorithm may not terminate ! w T w ( k ) = ˆ w ( k − 1) + y i x i update rule ˆ ‣ noise can cause this w T y i x i w T w ( k − 1) + ˆ algebra ‣ some simple functions are not = ˆ separable (xor) w T w ( k − 1) + δ definition of margin ≥ ˆ ! || w ( k ) || ≥ k δ ≥ k δ Mediocre generation: the algorithm finds a solution that “barely” separates || w ( k ) || 2 = || w ( k − 1) + y i x i || 2 bound the norm the data ! update rule ! ≤ || w ( k − 1) || 2 + || y i x i || 2 triangle inequality Overtraining: test/validation accuracy ≤ || w ( k − 1) || 2 + 1 norm rises and then falls ! √ ‣ Overtraining is a kind of overfitting || w ( k ) || ≤ k ≤ k √ → k ≤ 1 k δ ≤ || w ( k ) || ≤ k − δ 2 CMPSCI 689 Subhransu Maji (UMASS) 10 /19 CMPSCI 689 Subhransu Maji (UMASS) 11 /19
A problem with perceptron training Voted perceptron Problem: updates on later examples can take over ! Key idea: remember how long each weight vector survives ‣ 10000 training examples w (1) , w (2) , . . . , w ( K ) Let, , be the sequence of weights obtained by ‣ The algorithm learns weight vector on the first 100 examples the perceptron learning algorithm. ! ‣ Gets the next 9899 points correct c (1) , c (2) , . . . , c ( K ) ‣ Gets the 10000 th point wrong, updates on the the weight vector Let, , be the survival times for each of these. ! ‣ This completely ruins the weight vector (get 50% error) ‣ a weight that gets updated immediately gets c = 1 w (9999) ! ‣ a weight that survives another round gets c = 2, etc. w (10000) ! Then, ! x 10000 K ⌘! ⇣ ! X c ( k ) sign w ( k ) T x y = sign ˆ ! k =1 ! ! Voted and averaged perceptron (Freund and Schapire, 1999) CMPSCI 689 Subhransu Maji (UMASS) 12 /19 CMPSCI 689 Subhransu Maji (UMASS) 13 /19 Voted perceptron training algorithm Voted perceptron training algorithm ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) Input: training data Input: training data Output: list of pairs ( w (1) , c (1) ) , ( w (2) , c (2) ) , . . . , ( w ( K ) , c ( K ) ) Output: list of pairs ( w (1) , c (1) ) , ( w (2) , c (2) ) , . . . , ( w ( K ) , c ( K ) ) k = 0 , c (1) = 0 , w (1) ← [0 , . . . , 0] k = 0 , c (1) = 0 , w (1) ← [0 , . . . , 0] Initialize: ! Initialize: ! for iter = 1,…,T ! for iter = 1,…,T ! ‣ for i = 1,..,n ! ‣ for i = 1,..,n ! • predict according to the current model ! • predict according to the current model ! Better ⇢ +1 ⇢ +1 generalization, ! ! if w ( k ) T x i > 0 if w ( k ) T x i > 0 but not very y i = ˆ y i = ˆ ! ! if w ( k ) T x i ≤ 0 if w ( k ) T x i ≤ 0 − 1 − 1 practical ! ! c ( k ) = c ( k ) + 1 c ( k ) = c ( k ) + 1 • if , ! y i = ˆ • if , ! y i = ˆ y i y i w ( k +1) = w ( k ) + y i x i w ( k +1) = w ( k ) + y i x i • else, • else, c ( k +1) = 1 c ( k +1) = 1 k = k + 1 k = k + 1 CMPSCI 689 Subhransu Maji (UMASS) 14 /19 CMPSCI 689 Subhransu Maji (UMASS) 14 /19
Averaged perceptron Averaged perceptron training algorithm ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) Input: training data Key idea: remember how long each weight vector survives Output: w ¯ w (1) , w (2) , . . . , w ( K ) Let, , be the sequence of weights obtained by c = 0 , w = [0 , . . . , 0] , ¯ w = [0 , . . . , 0] Initialize: ! the perceptron learning algorithm. ! for iter = 1,…,T ! c (1) , c (2) , . . . , c ( K ) ‣ for i = 1,..,n ! Let, , be the survival times for each of these. ! • predict according to the current model ! ‣ a weight that gets updated immediately gets c = 1 ⇢ +1 ! ‣ a weight that survives another round gets c = 2, etc. if w T x i > 0 y i = ˆ ! if w T x i ≤ 0 − 1 Then, ! K ⌘! � ¯ • if , ! c ( k ) ⇣ y i = ˆ c = c + 1 X w ( k ) T x y i w T x � y = sign ˆ = sign • else, ! update average w ← ¯ ¯ w + c w k =1 w ← w + y i x i ! c = 1 ! performs similarly, but much more practical Return ← ¯ w + c w CMPSCI 689 Subhransu Maji (UMASS) 15 /19 CMPSCI 689 Subhransu Maji (UMASS) 16 /19 Comparison of perceptron variants Improving perceptrons Multilayer perceptrons: to learn non-linear MNIST dataset (Figure from Freund and Schapire 1999) functions of the input (neural networks) ! ! Separators with good margins: improves generalization ability of the classifier (support vector machines) ! Feature-mapping: to learn non-linear functions of the input using a perceptron ! ‣ we will learn do this efficiently using kernels √ φ : ( x 1 , x 2 ) → ( x 2 2 x 1 x 2 , x 2 2 ) 1 , x 2 a 2 + x 2 b 2 = 1 → z 1 a 2 + z 3 b 2 = 1 1 2 CMPSCI 689 Subhransu Maji (UMASS) 17 /19 CMPSCI 689 Subhransu Maji (UMASS) 18 /19
Slides credit Some slides adapted from Dan Klein at UC Berkeley and CIML book by Hal Daume ! Figure comparing various perceptrons are from Freund and Schapire CMPSCI 689 Subhransu Maji (UMASS) 19 /19
Recommend





















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.