
Workshop 7: (Generalized) Linear models Murray Logan 19 Jul 2017 - PowerPoint PPT Presentation
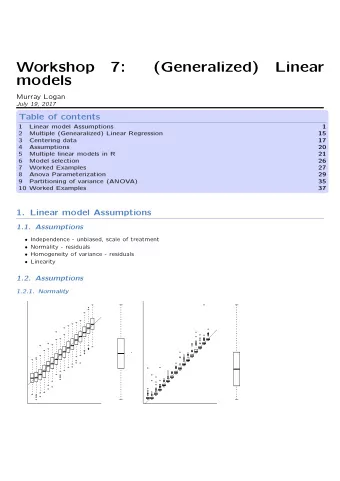
Workshop 7: (Generalized) Linear models Murray Logan 19 Jul 2017 Section 1 Linear model Assumptions Assumptions Independence - unbiased, scale of treatment Normality - residuals Homogeneity of variance - residuals Linearity
(Other) :13 :18.74 :0.0000 Bahiaan : 1 1st Qu.: 5.86 1st Qu.:0.0000 Bahiaas : 1 Median :15.17 Median :1.0000 Blanca : 1 Mean Mean : 0.21 :0.5263 Bota : 1 3rd Qu.:23.20 3rd Qu.:1.0000 Cabeza : 1 Max. :63.16 Max. :1.0000 Min. Min. > polis <- read.csv ('../data/polis.csv', strip.white=T) 1 ISLAND RATIO PA 1 Bota 15.41 1 2 Cabeza 5.63 1 3 Cerraja 25.92 4 Coronadito 15.17 Angeldlg: 1 0 5 Flecha 13.04 1 6 Gemelose 18.85 0 > summary (polis) ISLAND RATIO PA Worked Examples > head (polis)
:1402.0 Median : 338.0 : 462.2 Min. : 18.0 1st Qu.: 1773.7 1st Qu.: 148.0 Median : 4451.7 Mean INDIV : 7802.0 Mean : 446.9 3rd Qu.: 9287.7 3rd Qu.: 632.0 Max. :27144.0 Max. Min. AREA > peake <- read.csv ('../data/peakquinn.csv', strip.white=T) 3 AREA INDIV 1 516.00 18 2 469.06 60 462.25 > summary (peake) 57 4 938.60 100 5 1357.15 48 6 1773.66 118 Worked Examples > head (peake)
Worked Examples Question: is there a relationship between mussel clump area and number of individuals? Linear model: ε ∼ N (0 , σ 2 ) Indiv i = β 0 + β 1 Area i + ε i ε ∼ N (0 , σ 2 ) ln ( Indiv i ) = β 0 + β 1 ln ( Area i ) + ε i
Worked Examples Question: is there a relationship between mussel clump area and number of individuals? Linear model: Indiv i ∼ Pois ( λ i ) log ( λ ) = β 0 + β 1 ln ( Area i )
Section 2 Multiple (Genearalized) Linear Regression
Multiple Linear Regression l o d e e m i v d i t A d growth = intercept + temperature + nitrogen y i = β 0 + β 1 x i 1 + β 2 x i 2 + ... + β j x ij + ϵ i OR N ∑ y i = β 0 + β j x ji + ϵ i j =1: n
Multiple Linear Regression e l m o d v e i t i A d d growth = intercept + temperature + nitrogen y i = β 0 + β 1 x i 1 + β 2 x i 2 + ... + β j x ij + ϵ i - effect of one predictor holding the other(s) constant
Multiple Linear Regression l o d e e m t i v d d i A growth = intercept + temperature + nitrogen y i = β 0 + β 1 x i 1 + β 2 x i 2 + ... + β j x ij + ϵ i Y X1 X2 3 22.7 0.9 2.5 23.7 0.5 6 25.7 0.6 5.5 29.1 0.7 9 22 0.8 8.6 29 1.3 12 29.4 1
Multiple Linear Regression l d e m o i v e d i t A d 3 = β 0 + ( β 1 × 22 . 7) + ( β 2 × 0 . 9) + ε 1 2 . 5 = β 0 + ( β 1 × 23 . 7) + ( β 2 × 0 . 5) + ε 2 6 = β 0 + ( β 1 × 25 . 7) + ( β 2 × 0 . 6) + ε 3 5 . 5 = β 0 + ( β 1 × 29 . 1) + ( β 2 × 0 . 7) + ε 4 9 = β 0 + ( β 1 × 22) + ( β 2 × 0 . 8) + ε 5 8 . 6 = β 0 + ( β 1 × 29) + ( β 2 × 1 . 3) + ε 6 12 = β 0 + ( β 1 × 29 . 4) + ( β 2 × 1) + ε 7
Multiple Linear Regression d e l m o v e a t i l i c t i p M u l growth = intercept + temp + nitro + temp × nitro y i = β 0 + β 1 x i 1 + β 2 x i 2 + β 3 x i 1 x i 2 + ... + ϵ i
Multiple Linear Regression d e l m o i v e c a t p l i l t i M u + ( β 1 × 22 . 7) + ( β 2 × 0 . 9) + ( β 3 × 22 . 7 × 0 . 9) + ε 1 3 = β 0 + ( β 1 × 23 . 7) + ( β 2 × 0 . 5) + ( β 3 × 23 . 7 × 0 . 5) + ε 2 2 . 5 = β 0 6 = β 0 + ( β 1 × 25 . 7) + ( β 2 × 0 . 6) + ( β 3 × 25 . 7 × 0 . 6) + ε 3 5 . 5 = β 0 + ( β 1 × 29 . 1) + ( β 2 × 0 . 7) + ( β 3 × 29 . 1 × 0 . 7) + ε 4 9 = β 0 + ( β 1 × 22) + ( β 2 × 0 . 8) + ( β 3 × 22 × 0 . 8) + ε 5 8 . 6 = β 0 + ( β 1 × 29) + ( β 2 × 1 . 3) + ( β 3 × 29 × 1 . 3) + ε 6 12 = β 0 + ( β 1 × 29 . 4) + ( β 2 × 1) + ( β 3 × 29 . 4 × 1) + ε 7
Section 3 Centering data
Multiple Linear Regression g r i n n t e C e ● ● ● ● ● ● ● ● ● ● 20 ● ● ● ● ● ● ● ● ● ● 10 y 0 −10 −20 0 10 20 30 40 50 60 x
Multiple Linear Regression g r i n n t e C e ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 47 48 49 50 51 52 53 54
Multiple Linear Regression i n g t e r e n C ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 47 48 49 50 51 52 53 54
Multiple Linear Regression g r i n n t e C e ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 47 48 49 50 51 52 53 54 −3 −2 −1 0 1 2 3 4
Multiple Linear Regression n g e r i n t C e 24 ● ● ● ● 22 ● ● ● ● ● y 20 ● ● ● ● ● 18 ● ● ● ● 16 ● −4 −2 0 2 4 cx1
Section 4 Assumptions
Multiple Linear Regression o n s p t i s u m A s Normality, homog., linearity
Multiple Linear Regression o n s p t i s u m A s (multi)collinearity
Multiple Linear Regression o n a t i n f l e i a n c a r i V Strength of a relationship R 2 Strong when R 2 ≥ 0 . 8
Multiple Linear Regression n t i o f l a i n c e i a n V a r 1 var . inf = 1 − R 2 Collinear when var . inf > = 5 Some prefer > 3
1.743817 1.743817 > library (car) cx2 cx1 > vif ( lm (y ~ cx1 + cx2, data)) Multiple Linear Regression o n s t i u m p A s s (multi)collinearity > # additive model - scaled predictors
5.913254 16.949468 > vif ( lm (y ~ cx1 + cx2, data)) 7.259729 x1:x2 x2 x1 > vif ( lm (y ~ x1 * x2, data)) > # multiplicative model - raw predictors 1.743817 1.743817 cx2 cx1 > library (car) Multiple Linear Regression n s t i o u m p A s s (multi)collinearity > # additive model - scaled predictors
1.769411 1.771994 1.018694 > vif ( lm (y ~ x1 * x2, data)) cx1:cx2 cx2 cx1 > vif ( lm (y ~ cx1 * cx2, data)) > # multiplicative model - scaled predictors 5.913254 16.949468 7.259729 x1:x2 x2 x1 > # multiplicative model - raw predictors Multiple Linear Regression o n s p t i s u m A s
Section 5 Multiple linear models in R
> data.add.lm <- lm (y~cx1+cx2, data) Model fitting Additive model y i = β 0 + β 1 x i 1 + β 2 x i 2 + ϵ i
> data.mult.lm <- lm (y~cx1+cx2+cx1:cx2, data) > data.add.lm <- lm (y~cx1+cx2, data) > #OR > data.mult.lm <- lm (y~cx1*cx2, data) Model fitting Additive model y i = β 0 + β 1 x i 1 + β 2 x i 2 + ϵ i Multiplicative model y i = β 0 + β 1 x i 1 + β 2 x i 2 + β 3 x i 1 x i 2 + ϵ i
> plot (data.add.lm) Model evaluation Additive model Residuals vs Fitted Normal Q−Q 40 ● 40 ● ● 2 ● ● 2 ● ● ● ● ● ● ● ● ● Standardized residuals ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 1 ● ● ● ●● ● ● ● ● 1 ● ● ● ● ● ● ● Residuals ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 0 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 0 ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● −1 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● −1 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● −2 ● ● ● ● ● ● ● 74 ● −2 ● ● 30 ● 74 ● 30 −3 −2 −1 0 −2 −1 0 1 2 Fitted values Theoretical Quantiles Scale−Location Residuals vs Leverage 1.5 40 ● 30 ● ● 74 ● 40 ● ● ● ● ● ● 2 ● ● 19 ● ● ● ● ● ● ● Standardized residuals ● ● ● ● ● Standardized residuals ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 1.0 ● ● ● ● 1 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 0 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 0.5 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● −1 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 10 ● −2 ● ● ● ● ● ● ● ● ● Cook's distance 0.0 −3 −2 −1 0 0.00 0.02 0.04 0.06 Fitted values Leverage
> plot (data.mult.lm) Model evaluation Multiplicative model Residuals vs Fitted Normal Q−Q 2 ● 2 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● Standardized residuals ● ● ● ● ● ● ● ● ● 1 ● ● ● ● ● ● 1 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● Residuals ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 0 ● ● ● ● ● ● ● ● ● ● ● ● ● ● 0 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● −1 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● −1 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● −2 ● ● ● ● 59 74 ● ● −2 ● 30 7459 ● ● ● 30 −4 −3 −2 −1 0 1 2 −2 −1 0 1 2 Fitted values Theoretical Quantiles Scale−Location Residuals vs Leverage 1.5 30 ● ● ● 59 74 ● ● ● 2 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 19 ● ● 40 ● Standardized residuals ● ● ● Standardized residuals ● ● ● ● ● ● ● ● ● 1 ● ● ● ● ● ● ● ● ● 1.0 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 0 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 0.5 ● ● −1 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● −2 84 ● ● ● ● ● Cook's distance 0.0 −4 −3 −2 −1 0 1 2 0.00 0.05 0.10 0.15 0.20 Fitted values Leverage
p-value: < 2.2e-16 --- 0.4683 5.499 3.1e-07 *** cx2 -4.0475 0.3734 -10.839 < 2e-16 *** Signif. codes: cx1 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 1.055 on 97 degrees of freedom Multiple R-squared: 0.5567, Adjusted R-squared: 0.5476 F-statistic: 60.91 on 2 and 97 DF, 2.5749 < 2e-16 *** Max 0.1055 -14.364 lm(formula = y ~ cx1 + cx2, data = data) Residuals: Min 1Q Median 3Q -2.39418 -0.75888 -0.02463 > summary (data.add.lm) 0.73688 2.37938 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -1.5161 Call: Model summary Additive model
> confint (data.add.lm) 2.5 % 97.5 % (Intercept) -1.725529 -1.306576 cx1 1.645477 3.504300 cx2 -4.788628 -3.306308 Model summary Additive model
p-value: < 2.2e-16 2.697 5.957 4.22e-08 *** cx2 -4.1716 0.3648 -11.435 < 2e-16 *** cx1:cx2 2.5283 0.9373 0.00826 ** 2.7232 --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 1.023 on 96 degrees of freedom Multiple R-squared: 0.588, Adjusted R-squared: 0.5751 F-statistic: 45.66 on 3 and 96 DF, 0.4571 cx1 -2.23364 -0.62188 < 2e-16 *** lm(formula = y ~ cx1 * cx2, data = data) Residuals: Min 1Q Median 3Q Max 0.01763 > summary (data.mult.lm) 0.80912 1.98568 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -1.6995 0.1228 -13.836 Call: Model summary Multiplicative model
> library (effects) Graphical summaries Additive model > plot ( effect ("cx1",data.add.lm, partial.residuals=TRUE)) cx1 effect plot 3 2 ● ● ● 1 ● ● ● ● ● ● ● ● ● ● ● 0 ● ● ● ● ● ● ● ● ● ● ● ● ● ● y −1 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● −2 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● −3 ● ● ● ● ● ● ● ● −4 ● ● −0.4 −0.2 0.0 0.2 0.4 cx1
Error in fortify(data): object 'resids' not found Error in data.frame(resid = e$partial.residuals.raw, cx1 = e$data$cx1): arguments imply differing number of rows: 0, 100 geom_line ()+ theme_classic () + alpha=0.2)+ + geom_ribbon ( aes (ymin=lower, ymax=upper), fill='blue', + geom_point (data=resids, aes (y=resid, x=cx1))+ + > ggplot (newdata, aes (y=fit, x=cx1)) + cx1=e$data$cx1) + upper=e$upper) + cx1= seq (-0.4,0.4, len=10)), partial.residuals=TRUE) + > library (effects) Graphical summaries Additive model > library (ggplot2) > e <- effect ("cx1",data.add.lm, xlevels= list ( > newdata <- data.frame (fit=e$fit, cx1=e$x, lower=e$lower, > resids <- data.frame (resid=e$partial.residuals.raw,
> library (effects) Graphical summaries Additive model > plot ( allEffects (data.add.lm)) cx1 effect plot cx2 effect plot 0.0 1 −0.5 0 −1.0 −1 −1.5 y y −2 −2.0 −3 −2.5 −3.0 −4 −0.4 −0.2 0.0 0.2 0.4 −0.4 −0.2 0.0 0.2 0.4 cx1 cx2
> library (effects) Graphical summaries Multiplicative model > plot ( allEffects (data.mult.lm)) cx1*cx2 effect plot −0.4 −0.2 0.0 0.2 0.4 cx2 = −0.5 cx2 = 0 cx2 = 0.5 0 −2 y −4 −6 −0.4 −0.2 0.0 0.2 0.4 −0.4 −0.2 0.0 0.2 0.4 cx1
> library (effects) Graphical summaries Multiplicative model > plot ( Effect (focal.predictors= c ("cx1","cx2"),data.mult.lm)) cx1*cx2 effect plot −0.4 −0.2 0.0 0.2 0.4 cx2 = −0.5 cx2 = 0 cx2 = 0.5 0 −2 y −4 −6 −0.4 −0.2 0.0 0.2 0.4 −0.4 −0.2 0.0 0.2 0.4 cx1
Section 6 Model selection
How good is a model? All models are wrong, but some are useful George E. P. Box r i a i t e C r • R 2 - no • Information criteria ◦ AIC, AICc ◦ penalize for complexity
5 294.8666 data.add.lm data.mult.lm 4 299.9551 data.add.lm AICc df > library (MuMIn) 5 294.2283 data.mult.lm 4 299.5340 AIC df > AIC (data.add.lm, data.mult.lm) Model selection t e s i d a a n d C > AICc (data.add.lm, data.mult.lm)
Models ranked by AICc(x) 0.073 2.7230 -4.172 2.528 5 -142.114 294.9 0.00 0.927 4 -1.516 2.5750 -4.047 4 -145.767 300.0 5.09 3 -1.516 AICc delta weight -2.706 3 -159.333 324.9 30.05 0.000 1 -1.516 2 -186.446 377.0 82.15 0.000 2 -1.516 -0.7399 3 -185.441 377.1 82.27 0.000 8 -1.699 logLik 0 : lm(formula = y ~ 1, data = data, na.action = na.fail) > library (MuMIn) cx1 (Int) Model selection table --- Global model call: lm(formula = y ~ cx1 * cx2, data = data, na.action = na.fail) 7 : lm(formula = y ~ cx1 + cx2 + cx1:cx2 + 1, data = data, na.action = na.fail) 3 : lm(formula = y ~ cx1 + cx2 + 1, data = data, na.action = na.fail) 2 : lm(formula = y ~ cx2 + 1, data = data, na.action = na.fail) 1 : lm(formula = y ~ cx1 + 1, data = data, na.action = na.fail) cx2 cx1:cx2 df Model selection g g i n r e d D > data.mult.lm <- lm (y~cx1*cx2, data, na.action=na.fail) > dredge (data.mult.lm, rank="AICc", trace=TRUE)
-1.686125 2.712397 -4.162525 2.528328 > data.dredge<- dredge (data.mult.lm, rank="AICc") subset -1.686125 2.712397 -4.162525 2.344227 full cx1:cx2 cx2 cx1 (Intercept) Coefficients: '123' '12' Component models: model.avg(object = data.dredge, subset = delta < 20) Call: > library (MuMIn) Multiple Linear Regression n g a g i v e r l a o d e M > model.avg (data.dredge, subset=delta<20)
Multiple Linear Regression i o n c t e l e l s o d e M Or more preferable: • identify 10-15 candidate models • compare these via AIC (etc)
Section 7 Worked Examples
3 130 1.0 4 17.1 1.0 1966 66 66 3 160 5 13.8 1918 311 246 246 5 140 6 14.1 1.0 1965 234 285 5 140 104 > loyn <- read.csv ('../data/loyn.csv', strip.white=T) 2 ABUND AREA YR.ISOL DIST LDIST GRAZE ALT 1 5.3 0.1 1968 39 39 2 160 2.0 1900 0.5 1920 234 234 5 60 3 1.5 0.5 Worked examples > head (loyn)
Error in arrangeGrob(...): object 'loyn.area.plot' not found Error in data.frame(ABUND = loyn.eff[[1]]$partial.residuals.raw, AREA = loyn.eff[[1]]$x.all$AREA): arguments imply differing number of rows: 0, 56 Error in fortify(data): object 'resid.yr.isol' not found Error in data.frame(ABUND = loyn.eff[[3]]$partial.residuals.raw, YR.ISOL = loyn.eff[[3]]$x.all$YR.ISOL): arguments imply differing number of rows: 0, 56 Error in fortify(data): object 'resid.graze' not found Error in data.frame(ABUND = loyn.eff[[2]]$partial.residuals.raw, GRAZE = loyn.eff[[2]]$x.all$GRAZE): arguments imply differing number of rows: 0, 56 Error in fortify(data): object 'resid.area' not found Worked Examples Question: what effects do fragmentation variables have on the abundance of forest birds Linear model: N ∑ ε ∼ N (0 , σ 2 ) Abund i = β 0 + β j X ji + ε i j =1: n
0.11 0.24 0.40 99.38 623 12.0 6 0.03 38.87 0.14 0.40 4.8 5 0.33 46.90 102.82 484 0.15 0.35 8.2 4 0.75 43.95 101.87 476 0.20 7.2 > paruelo <- read.csv ('../data/paruelo.csv', strip.white=T) 3 0.76 45.78 110.78 536 0.29 0.24 7.5 2 0.65 47.32 114.27 469 0.45 0.12 1 0.65 46.40 119.55 199 12.4 MAT JJAMAP DJFMAP LONG MAP LAT C3 Worked Examples > head (paruelo)
Error in (function (..., row.names = NULL, check.rows = FALSE, check.names = TRUE, : arguments imply differing number of rows: 0, 365 Error in `$<-.data.frame`(`*tmp*`, "LONG", value = numeric(0)): replacement has 0 rows, data has 100 Error in (function (..., row.names = NULL, check.rows = FALSE, check.names = TRUE, : arguments imply differing number of rows: 0, 365 Error in summary(paruelo.lmM2): object 'paruelo.lmM2' not found Error in eval(expr, envir, enclos): object 'LONG' not found Error in eval(expr, envir, enclos): object 'LONG' not found Error in `$<-.data.frame`(`*tmp*`, "LONG", value = numeric(0)): replacement has 0 rows, data has 100 Error in `$<-.data.frame`(`*tmp*`, "LAT", value = numeric(0)): replacement has 0 rows, data has 100 Error in Analyze.model(focal.predictors, mod, xlevels, default.levels, : the following predictors are not in the model: cLAT, cLONG Error in eval(expr, envir, enclos): object 'LONG' not found Error in eval(expr, envir, enclos): object 'LONG' not found Error in `$<-.data.frame`(`*tmp*`, "LAT", value = numeric(0)): replacement has 0 rows, data has 100 Error in Analyze.model(focal.predictors, mod, xlevels, default.levels, : the following predictors are not in the model: cLAT, cLONG Worked Examples Question: what effects do fragmentation geographical variables have on the abundance of C3 grasses Linear model: N ∑ ε ∼ N (0 , σ 2 ) C 3 i = β 0 + β j X ji + ε i j =1: n
Section 8 Anova Param- eterization
Simple ANOVA Three treatments (One factor - 3 levels), three replicates
Simple ANOVA Two treatments, three replicates
0 G3 G2 0 1 0 8 G2 0 1 0 10 0 Y 0 1 11 G3 0 0 1 12 G3 0 7 1 1 3 A dummy1 dummy2 dummy3 --- --- -------- -------- -------- 2 G1 1 0 0 G1 0 1 0 0 4 G1 1 0 0 6 G2 0 Categorical predictor y ij = µ + β 1 ( dummy 1 ) ij + β 2 ( dummy 2 ) ij + β 3 ( dummy 3 ) ij + ε ij
1 1 G2 1 0 1 0 8 G2 1 0 1 0 10 G3 0 0 0 1 11 G3 1 0 0 1 12 G3 1 0 0 7 1 G1 0 Intercept dummy1 dummy2 dummy3 --- --- ----------- -------- -------- -------- 2 G1 1 1 0 0 3 1 Y 1 0 0 4 G1 1 1 0 0 6 G2 1 A Overparameterized y ij = µ + β 1 ( dummy 1 ) ij + β 2 ( dummy 2 ) ij + β 3 ( dummy 3 ) ij + ε ij
Overparameterized y ij = µ + β 1 ( dummy 1 ) ij + β 2 ( dummy 2 ) ij + β 3 ( dummy 3 ) ij + ε ij • three treatment groups • four parameters to estimate • need to re-parameterize
Categorical predictor y i = µ + β 1 ( dummy 1 ) i + β 2 ( dummy 2 ) + β 3 ( dummy 3 ) i + ε i i o n z a t r i e t e r a m p a a n s M e y i = β 1 ( dummy 1 ) i + β 2 ( dummy 2 ) i + β 3 ( dummy 3 ) i + ε ij y ij = α i + ε ij i = p
1 1 0 1 0 G2 7 0 0 G2 G2 6 0 0 1 G1 8 0 0 0 0 0 G3 12 1 0 G3 1 11 1 0 0 G3 10 0 4 0 2 Y G1 3 0 0 1 G1 1 --- --- -------- -------- -------- dummy3 dummy2 dummy1 A Categorical predictor n t i o i z a t e r a m e p a r n s M e a y i = β 1 ( dummy 1 ) i + β 2 ( dummy 2 ) i + β 3 ( dummy 3 ) i + ε i
Categorical predictorDD n t i o i z a t e r a m e p a r n s M e a y i = α 1 D 1 i + α 2 D 2 i + α 3 D 3 i + ε i y i = α p + ε i , Y A where p = number of levels of the factor and D = 1 2.00 G1 dummy variables 2 3.00 G1 3 4.00 G1 2 1 0 0 ε 1 3 1 0 0 4 6.00 G2 ε 2 4 1 0 0 ε 3 5 7.00 G2 6 0 1 0 α 1 ε 4 6 8.00 G2 + 7 = 0 1 0 × α 2 ε 5 7 10.00 G3 8 0 1 0 α 3 ε 6 8 11.00 G3 10 0 0 1 ε 7 9 12.00 G3 11 0 0 1 ε 8 12 0 0 1 ε 9
AG1 3 Pr(>|t|) t value Estimate Std. Error > summary ( lm (Y~-1+A))$coef 0.5773503 5.196152 2.022368e-03 AG2 7 0.5773503 12.124356 1.913030e-05 AG3 11 0.5773503 19.052559 1.351732e-06 Categorical predictor n t i o i z a t e r a m e p a r n s M e a Parameter Estimates Null Hypothesis α ∗ H 0 : α 1 = α 1 = 0 mean of group 1 1 α ∗ H 0 : α 2 = α 2 = 0 mean of group 2 2 α ∗ mean of group 3 H 0 : α 3 = α 3 = 0 3 but typically interested exploring effects
Categorical predictor y i = µ + β 1 ( dummy 1 ) i + β 2 ( dummy 2 ) i + β 3 ( dummy 3 ) i + ε i n t i o z a e r i m e t a r a s p e c t E f f y ij = µ + β 2 ( dummy 2 ) ij + β 3 ( dummy 3 ) ij + ε ij y ij = µ + α i + ε ij i = p − 1
1 1 0 1 1 G2 7 0 1 G2 G2 6 0 0 1 G1 4 8 1 0 1 0 1 G3 12 1 0 G3 1 11 1 0 1 G3 10 0 0 1 G1 --- --- ------- -------- -------- Y A alpha dummy3 dummy2 2 G1 1 0 0 3 Categorical predictor n t i o i z a t e r a m e p a r t s e c E f f y i = α + β 2 ( dummy 2 ) i + β 3 ( dummy 3 ) i + ε i
Categorical predictor n t i o i z a t e r a m e p a r s e c t E f f y i = α + β 2 D 2 i + β 3 D 3 i + ε i y i = α p + ε i , Y A where p = number of levels of the factor minus 1 and 1 2.00 G1 D = dummy variables 2 3.00 G1 2 1 0 0 ε 1 3 4.00 G1 3 1 0 0 ε 2 4 6.00 G2 4 1 0 0 ε 3 5 7.00 G2 6 1 1 0 µ ε 4 6 8.00 G2 + 7 = 1 1 0 × α 2 ε 5 7 10.00 G3 8 1 1 0 α 3 ε 6 10 1 0 1 ε 7 8 11.00 G3 11 1 0 1 ε 8 9 12.00 G3 12 1 0 1 ε 9
0.8164966 9.797959 6.506149e-05 Pr(>|t|) G1 0 0 G2 1 0 G3 0 1 > summary ( lm (Y~A))$coef Estimate Std. Error t value (Intercept) > contrasts (A) <-contr.treatment 3 0.5773503 5.196152 2.022368e-03 A2 4 0.8164966 4.898979 2.713682e-03 A3 8 2 3 Categorical predictor s a s t n t r c o e n t a t m T r e Parameter Estimates Null Hypothesis H 0 : µ = µ 1 = 0 Intercept mean of control group H 0 : α 2 = α 2 = 0 α ∗ mean of group 2 2 minus mean of control group α ∗ H 0 : α 3 = α 3 = 0 mean of group 3 3 minus mean of control group > contrasts (A)
0.8164966 9.797959 6.506149e-05 > summary ( lm (Y~A))$coef 8 A3 0.8164966 4.898979 2.713682e-03 4 A2 0.5773503 5.196152 2.022368e-03 3 (Intercept) Pr(>|t|) t value Estimate Std. Error Categorical predictor s a s t n t r c o e n t a t m T r e Parameter Estimates Null Hypothesis H 0 : µ = µ 1 = 0 Intercept mean of control group H 0 : α 2 = α 2 = 0 α ∗ mean of group 2 2 minus mean of control group α ∗ H 0 : α 3 = α 3 = 0 mean of group 3 3 minus mean of control group
-1 -0.5 > contrasts (A) <- cbind ( c (0,1,-1), c (1, -0.5, -0.5)) G3 1 -0.5 G2 1.0 0 G1 [,1] [,2] Categorical predictor s a s t n t r c o n e d e f i d s e r U User defined contrasts Grp2 vs Grp3 Grp1 vs (Grp2 & Grp3) Grp1 Grp2 Grp3 α ∗ 0 1 -1 2 α ∗ 1 -0.5 -0.5 3 > contrasts (A)
Categorical predictor s t s r a o n t d c i n e d e f e r U s • p − 1 comparisons (contrasts) • all contrasts must be orthogonal
Categorical predictor t y a l i g o n t h o O r Four groups (A, B, C, D) p − 1 = 3 comparisons 1. A vs B :: A > B 2. B vs C :: B > C 3. A vs C ::
> contrasts (A) <- cbind ( c (0,1,-1), c (1, -0.5, -0.5)) [,1] [,2] -1 -0.5 G3 1 -0.5 G2 1.0 0 G1 Categorical predictor s a s t n t r c o e d f i n d e s e r U > contrasts (A) 0 × 1 . 0 = 0 1 × − 0 . 5 − 0 . 5 = − 1 × − 0 . 5 = 0 . 5 = 0 sum
0.4714045 -8.485281 1.465426e-04 > summary ( lm (Y~A))$coef G3 -1 -0.5 > crossprod ( contrasts (A)) [,1] [,2] [1,] 2 0.0 [2,] 0 1.5 Estimate Std. Error G2 t value Pr(>|t|) (Intercept) 7 0.3333333 21.000000 7.595904e-07 A1 -2 0.4082483 -4.898979 2.713682e-03 A2 -4 1 -0.5 1.0 0 G1 [,1] [,2] > contrasts (A) <- cbind ( c (0,1,-1), c (1, -0.5, -0.5)) Categorical predictor s a s t n t r c o n e d e f i d s e r U > contrasts (A)
2.0 0 G1 1.0 1 G2 -0.5 -1 G3 -0.5 > crossprod ( contrasts (A)) > contrasts (A) <- cbind ( c (1, -0.5, -0.5), c (1,-1,0)) [,1] [,2] [1,] 1.5 1.5 [2,] 1.5 [,1] [,2] Categorical predictor t s r a s o n t d c i n e d e f r U s e > contrasts (A)
Section 9 Partitioning of variance (ANOVA)
Recommend




















![Introduction to Data Science: Neural [ 1 , 2 , , p ] g x w h m g h g f w old M](https://c.sambuz.com/1003023/introduction-to-data-science-neural-s.webp)


More recommend
Explore More Topics
Stay informed with curated content and fresh updates.