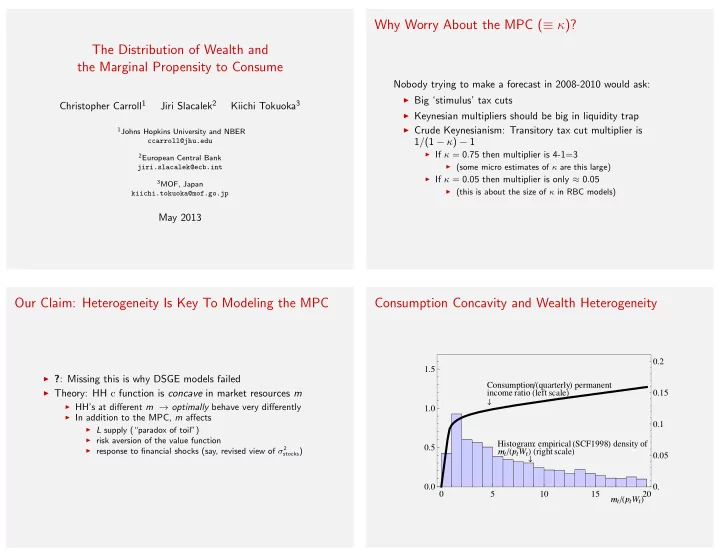
Why Worry About the MPC ( ≡ κ )? The Distribution of Wealth and the Marginal Propensity to Consume Nobody trying to make a forecast in 2008-2010 would ask: ◮ Big ‘stimulus’ tax cuts Christopher Carroll 1 Jiri Slacalek 2 Kiichi Tokuoka 3 ◮ Keynesian multipliers should be big in liquidity trap ◮ Crude Keynesianism: Transitory tax cut multiplier is 1 Johns Hopkins University and NBER 1 / (1 − κ ) − 1 ccarroll@jhu.edu ◮ If κ = 0 . 75 then multiplier is 4-1=3 2 European Central Bank ◮ (some micro estimates of κ are this large) jiri.slacalek@ecb.int ◮ If κ = 0 . 05 then multiplier is only ≈ 0 . 05 3 MOF, Japan ◮ (this is about the size of κ in RBC models) kiichi.tokuoka@mof.go.jp May 2013 Our Claim: Heterogeneity Is Key To Modeling the MPC Consumption Concavity and Wealth Heterogeneity 0.2 1.5 ◮ ? : Missing this is why DSGE models failed Consumption �� quarterly � permanent income ratio � left scale � 0.15 ◮ Theory: HH c function is concave in market resources m � ◮ HH’s at different m → optimally behave very differently 1.0 ◮ In addition to the MPC, m affects 0.1 ◮ L supply (“paradox of toil”) ◮ risk aversion of the value function Histogram: empirical � SCF1998 � density of 0.5 � � �� � � W � � � right scale � ◮ response to financial shocks (say, revised view of σ 2 stocks ) 0.05 � 0.0 0. 0 5 10 15 20 � � �� � � W � �
Microeconomics of Consumption Our Goal: “Serious” Microfoundations Since Friedman’s (1957) PIH: Requires three changes to well-known Krusell-Smith model: ◮ Sensible microeconomic income process ◮ c chosen optimally: Want to smooth c in light of y fluctuations ◮ Finite lifetimes ◮ Single most important thing to get right is income dynamics! ◮ Match wealth distribution ◮ With smooth c , income dynamics drive everything! ◮ Here, achieved by preference heterogeneity ◮ View it as a proxy for many kinds of heterogeneity ◮ Saving/dissaving: Depends on whether E [∆ y ] ↑ or E [∆ y ] ↓ ◮ Age ◮ Wealth distribution depends on integration of saving ◮ Growth ◮ Cardinal sin: Assume crazy income dynamics ◮ Risk Aversion ◮ No end can justify this means ◮ ... ◮ Throws out the defining core of the intellectual framework To-Do List Friedman (1957): Permanent Income Hypothesis 1. Calibrate realistic income process = P t + T t Y t 2. Match empirical wealth distribution C t = P t 3. Back out optimal C and MPC out of transitory income 4. Is MPC in line with empirical estimates? Progress since then ◮ Micro data: Friedman description of income shocks works well Our Question: ◮ Math: Friedman’s words well describe optimal solution to Does a model that matches micro facts about income dynamics and wealth distribution give different (and more plausible) answers dynamic stochastic optimization problem of impatient than KS to macroeconomic questions (say, about the response of consumers with geometric discounting under CRRA utility consumption to fiscal ‘stimulus’)? with uninsurable idiosyncratic risk calibrated using these micro income dynamics (!)
Our (Micro) Income Process Further Details of Income Process Idiosyncratic (household) income process is logarithmic Friedman: Modifications from Carroll (1992): Trans income ξ t incorporates unemployment insurance: y y y t +1 = p t +1 ξ t +1 W = p t ψ t +1 p t +1 ξ t = µ with probability u (1 − τ )¯ = ℓθ t with probability 1 − u p t = permanent income ξ t = transitory income µ is UI when unemployed ψ t +1 = permanent shock τ is the rate of tax collected for the unemployment benefits W = aggregate wage rate Model Without Aggr Uncertainty: Decision Problem What Happens After Death? � � ψ 1 − ρ u ( c t ) + β � v ( m t ) = max D E t t +1 v ( m t +1 ) { c t } ◮ You are replaced by a new agent whose permanent income is s.t. equal to the population mean a t = m t − c t ◮ Prevents the population distribution of permanent income 0 a t ≥ from spreading out a t / ( � k t +1 = D ψ t +1 ) m t +1 = ( � + r ) k t +1 + ξ t +1 K / ¯ L ) α − 1 = α a ( K ℓ L r K L Variables normalized by p t W
Ergodic Distribution of Permanent Income Parameter Values Exists, if death eliminates permanent shocks: ◮ β , ρ , α , δ , ¯ ℓ , µ , and u taken from JEDC special volume D E [ ψ 2 ] < 1 . � ◮ Key new parameter values: Holds. Description Param Value Source Population mean of p 2 : Prob of Death per Quarter D 0 . 005 Life span of 50 years σ 2 Carroll (1992) ; SCF Variance of Log ψ t 0 . 016 / 4 ψ � D � σ 2 Carroll (1992) Variance of Log θ t 0 . 010 × 4 M [ p 2 ] θ = 1 − � D E [ ψ 2 ] Annual Income, Earnings, or Wage Variances Typology of Our Models Three Dimensions σ 2 σ 2 1. Discount Factor β ψ ξ Our parameters 0 . 016 0 . 010 ◮ ‘ β -Point’ model: Single discount factor Carroll (1992) 0 . 016 0 . 010 ◮ ‘ β -Dist’ model: Uniformly distributed discount factor Storesletten, Telmer, and Yaron (2004) 0 . 008–0 . 026 0 . 316 Meghir and Pistaferri (2004) ⋆ 0 . 031 0 . 032 Low, Meghir, and Pistaferri (2010) 0 . 011 − 2. Aggregate Shocks Blundell, Pistaferri, and Preston (2008a) ⋆ 0 . 010–0 . 030 0 . 029–0 . 055 ◮ (No) Implied by KS-JEDC 0 . 000 0 . 038 ◮ Krusell–Smith Implied by Castaneda et al. (2003) 0 . 028 0 . 004 ◮ Friedman/Buffer Stock ⋆ Meghir and Pistaferri (2004) and Blundell, Pistaferri, and Preston (2008a) assume that the transitory component 3. Empirical Wealth Variable to Match is serially correlated (an MA process), and report the variance of a subelement of the transitory component. σ 2 ξ for ◮ Net Worth these articles are calculated using their MA estimates. ◮ Liquid Financial Assets
Dimension 1: Estimation of β -Point and β -Dist Results: Wealth Distribution ‘ β -Point’ model Micro Income Process ◮ ‘Estimate’ single ` β by matching the capital–output ratio KS-Orig ⋄ Friedman/Buffer Stock KS-JEDC Point Uniformly Our solution Hetero ‘ β -Dist’ model—Heterogenous Impatience Discount Distributed Factor ‡ Discount Factors ⋆ U.S. ◮ Assume uniformly distributed β across households Data ∗ β -Point β -Dist ◮ Estimate the band [` β − ∇ , ` β + ∇ ] by minimizing distance between Top 1% 10. 26.4 3. 3.0 24.0 29.6 model ( w ) and data ( ω ) net worth held by the top 20, 40, 60, 80% Top 20% 55.1 83.1 39.7 35.0 88.0 79.5 Top 40% 76.9 93.7 65.4 92.9 � ( w i − ω i ) 2 , min Top 60% 90.1 97.4 83.5 98.7 { ` β, ∇} i =20 , 40 , 60 , 80 Top 80% 97.5 99.3 95.1 100.4 s.t. aggregate net worth–output ratio matches the steady-state Notes: ‡ : ` β = 0 . 9899. ⋆ : ( ` β, ∇ ) = (0 . 9876 , 0 . 0060). ⋄ : The results are from Krusell and Smith (1998) who value from the perfect foresight model solved the models with aggregate shocks. ∗ : U.S. data is the SCF reported in Castaneda, Diaz-Gimenez, and Rios-Rull (2003). Bold points are targeted. K K K t / Y Y Y t =10.3. Results: Wealth Distribution Dimension 2.a: Adding KS Aggregate Shocks Model with KS Aggregate Shocks: Assumptions � 1 ◮ Only two aggregate states (good or bad) ◮ Aggregate productivity a t = 1 ± △ a 0.75 ◮ Unemployment rate u depends on the state ( u g or u b ) KS � JEDC � Parameter values for aggregate shocks from Krusell and Smith (1998) 0.5 Parameter Value � Β� Point Β� Dist △ a 0.25 0.01 u g 0.04 u b 0.10 � US data � SCF, solid line � 0 Agg transition probability 0.125 0 25 50 75 100 Percentile
Recommend
More recommend
Unleash a World of Digital Possibilities—Browse, Share, and Explore Content Without Boundaries























