
Why is Internet traffic self-similar? Allen B. Downey Wellesley - PowerPoint PPT Presentation
Why is Internet traffic self-similar? Allen B. Downey Wellesley College No Micro$oft products were used in the preparation of this talk. What is self-similarity? Real-world: visually similar over range of spatial scales. Fractals:
Why is Internet traffic self-similar? Allen B. Downey Wellesley College No Micro$oft products were used in the preparation of this talk.
What is self-similarity? Real-world: visually ● similar over range of spatial scales. Fractals: geometrically ● similar over all spatial scales. Time-series: ● statistically similar over range of time scales.
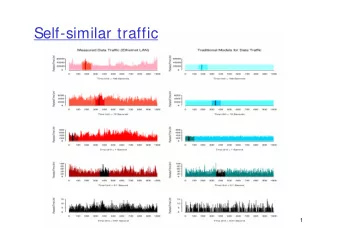
Network traffic Ethernet and WAN traffic ● 60000 60000 appear self-similar. 40000 28h 40000 20000 20000 0 0 [WillingerEtAl95] 0 200 400 600 800 1000 0 200 400 600 800 1000 6000 6000 4000 2.8h 4000 2000 2000 x = time in varying units 0 0 0 200 400 600 800 1000 0 200 400 600 800 1000 y = packets / unit time 800 800 600 600 17m 400 400 200 200 0 0 0 200 400 600 800 1000 0 200 400 600 800 1000 Visual self-similarity over ● 100 100 80 80 5 orders of magnitude! 100s 60 60 40 40 20 20 0 0 0 200 400 600 800 1000 0 200 400 600 800 1000 15 15 10 10 10s 5 5 0 0 0 200 400 600 800 1000 0 200 400 600 800 1000
Explanatory models derivation Model Model Behavior verification abstraction explanation System System Behavior Abstraction: is it realistic? ● Derivation: is it correct? ● Verification: is the behavior the same? ● Explanation: does this really explain? ●
Ideal gas law explained Abstraction: no interaction, elastic collision, etc. ● Derivation: you do the math (or simulation). ● Verification: most gas, most of the time. ●
Explanations of self-similarity fractional ON/OFF gaussian model noise M/G/infinity asymptotic model self similarity Internet empirical self−similarity Abstraction Verification ● ● Two aggregation models FGN is self-similar. ● ● Long-tailed distribution of ASY isn’t, but it can pass. ● ● file sizes
Distribution of file sizes Is it long-tailed? ● If so, why? ●
Cumulative distributions Normal cdf x = range of values 1.0 y = Prob {value < x} 0.8 Prob {file size < x} cdf maps values to 0.6 percentiles 0.4 0.2 normal 0.0 0 10000 20000 30000 40000 File size (bytes)
Skewed distributions normal distribution is ● Skewed cdfs symmetric. 1.0 skewed has many ● small values and some 0.8 large. Prob {file size < x} lognormal even more 0.6 ● skewed. pareto even more 0.4 ● skewed. normal skewed 0.2 lognormal pareto 0.0 0 20000 40000 60000 80000 100000 File size (bytes)
Logarithmic x axis Skewed cdfs Skewed cdfs, log x axis 1.0 1.0 normal 0.8 0.8 skewed Prob {file size < x} Prob {file size < x} lognormal pareto 0.6 0.6 0.4 0.4 normal skewed 0.2 0.2 lognormal pareto 0.0 0.0 0 20000 40000 60000 80000 100000 1 32 1KB 32KB 1MB File size (bytes) File size (bytes)
☎ ✄ ✁ � ✂ Log-log axes Skewed cdfs, log x axis 1.0 normal 0.8 Complementary cdf: skewed ● Prob {file size < x} lognormal Prob {value > x} pareto 0.6 Log y axis amplifies ● 0.4 tail behavior. 0.2 Pareto distribution ● 0.0 is a straight line. 1 32 1KB 32KB 1MB File size (bytes) Skewed cdfs, log-log axes 1 1/4 Prob {file size > x} 1/16 1/64 normal skewed 1/256 lognormal pareto 1/1024 1 32 1KB 32KB 1MB File size (bytes)
Evidence of long tails Process lifetimes Is long-tailedness an 1 ● empirical property? 0.1 Long-tailed dist ● converges to Pareto. Prob {lifetime > x} 0.01 How do we know it ● keeps going? 0.001 0.0001 Pareto model actual cdf 0.00001 0.001 0.01 0.1 1 10 100 1000 Duration (seconds)
✆ File sizes in the WWW File Sizes from Crovella dataset File Sizes from NASA dataset 1 1 1/4 1/4 1/16 1/16 Prob {file size > x} Prob {file size > x} 1/64 1/64 1/256 1/256 1/1024 1/1024 1/4096 1/4096 Pareto model Pareto model actual cdf 1/16384 1/16384 actual cdf 1 32 1KB 32KB 1MB 32MB 1 32 1KB 32KB 1MB 32MB File size (bytes) File size (bytes)
Where we are Some empirical evidence ● of long tailed distributions. Explanatory model for ● WWW files. [CarlsonDoyle99] No explanation for other ● file systems.
Explanatory model Goal: Model of user behavior that produces ● long-tailed distributions. Hypothesis: Most new files are copies of old files. ● Many new files are translations of old files. ● New size is a small multiple of the old size. ●
User Model Model: Choose an existing file at random. ● Choose a small multiplier at random. ● new file size = old file size * multiplier ● Repeat. ● Two parameters: Initial file size. ● Variability of multipliers. ●
Simulation of user model Distribution of File Sizes 1.0 89,000 files on ● rocky.wellesley.edu cdf from simulation actual cdf 0.8 Choose parameters ● Prob {file size < x} to fit the distribution. 0.6 Fits pretty good! ● Analytic form? ● 0.4 0.2 0.0 1 32 1KB 32KB 1MB 32MB File size (bytes)
Continuous model Replace discrete file ● sizes with continuous. Simulation computes ● numerical solution of diffusion equation. Solution of PDE ● yields analytic model of the distribution.
Solve that PDE! Simulation evolution Distribution of file ● 1.0 sizes is normal on a 10 files log-x axis: 1000 files 0.8 LOGNORMAL. 100000 files Prob {file size < x} 0.6 0.4 0.2 0.0 1 32 1KB 32KB 1MB 32MB File size (bytes)
Estimate those parameters! Irlam collected file ● File Sizes, Irlam dataset sizes from 500+ 1.0 systems. lognormal model actual cdf Using the analytic 0.8 ● Prob {file size < x} model we can estimate parameters. 0.6 Goodness of fit: ● Kolmogorov-Smirnov 0.4 statistic. Range: 1.4 to 40 0.2 ● Median: 8.0 ● 0.0 1 32 1KB 32KB 1MB 32MB File size (bytes)
Oh, no! Skewed cdfs, log-log axes The lognormal 1 ● distribution is not long-tailed. 1/4 Prob {file size > x} Under either ● aggregation model, 1/16 lognormal file sizes yield self-similarity 1/64 over a range of time normal scales, but not true skewed 1/256 self-similarity. lognormal pareto 1/1024 1 32 1KB 32KB 1MB File size (bytes)
✞ ✝ ✝ Tail behavior? File Sizes from Crovella dataset File Sizes from NASA dataset 1 1 1/4 1/4 1/16 1/16 Prob {file size > x} Prob {file size > x} 1/64 1/64 1/256 1/256 1/1024 1/1024 1/4096 Pareto model 1/4096 Pareto model lognormal model lognormal model 1/16384 1/16384 actual cdf actual cdf 1 32 1KB 32KB 1MB 32MB 1 32 1KB 32KB 1MB 32MB File size (bytes) File size (bytes) To explain self-similarity, we only need a Pareto tail. ● Log-log ccdf amplifies tail. ● Which model is better? ●
Theory choice Accuracy ● Scope ● Consistency ● Kuhn’s criteria Simplicity ● Fruitfulness ● Explanatory model one more criterion ●
Lognormal vs. Pareto Accuracy and Scope ● Diffusion model fits the bulk of the distribution. ● Pareto model sometimes fits the tail better. ● Consistency ● Diffusion model undermines self-sim explanation. ● Simplicity ● Pick ’em. ● Fruitfulness ● Long-tailed distributions are a nightmare for modelers. ● Explanatory model ● Carlson and Doyle only explain Web files. ● I think the diffusion model is more realistic. ●
Trade simplicity for accuracy File Sizes from Crovella98 What if the ● 1 primordial soup 1/4 contained two files? 1/16 Multimodal Prob {file size > x} ● (5-parameter) 1/64 lognormal model. 1/256 Accuracy and ● 1/1024 complexity comparable to 1/4096 Crovella’s hybrid lognormal model 1/16384 model. actual cdf 1 32 1KB 32KB 1MB 32MB File size (bytes)
Is Internet traffic really self-similar? What seems to be an empirical question depends on ● theory choice. Theory choice is not determined (entirely) by evidence. ● Pareto tail lognormal other Pareto fractional fractional ON/OFF gaussian gaussian model pseudo noise noise self similarity asymptotic M/G/infinity self similarity model
Where does that leave us? Realist: ● There is a real world and we are capable of knowing about it. ● Rational theory choice is capable of selecting the right theory. ● The Internet either is or is not really self-similar. ● Instrumentalist: ● Agnostic about the real world. ● Our theories are tools that either work or not. ● If it’s useful to model the Internet as self-similar, go ahead. ● Other flavors of anti-realist. ●
Long-tailed marmot?
Recommend
















![1 Web Traffic Characterization Zipf Web Traffic Characterization Zipf [Breslau/Cao99] and](https://c.sambuz.com/987174/1-s.webp)






More recommend
Explore More Topics
Stay informed with curated content and fresh updates.