Superscalar Design: An Introduction Virendra Singh Associate Professor C omputer A rchitecture and D ependable S ystems L ab Department of Electrical Engineering Indian Institute of Technology Bombay http://www.ee.iitb.ac.in/~viren/ E-mail: viren@ee.iitb.ac.in EE-739: Processor Design Lecture 23 (11 March 2013) CADSL
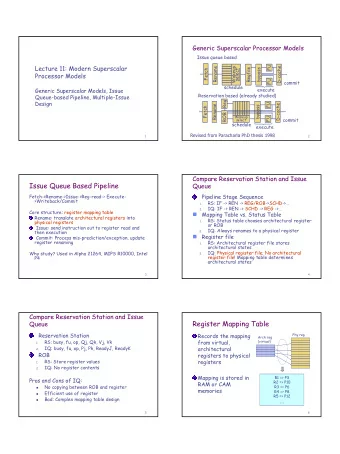
Superscalar Pipeline Stages Superscalar Pipeline Stages Fetch Instruction Buffer Decode In Program Order Dispatch Buffer Dispatch Issuing Buffer Out Execute of Order Completion Buffer Complete In Program Store Buffer Order Retire 11 Mar 2013 EE-739@IITB 2 CADSL
Superscalar Architecture Wide pipelines for enhanced throughput ILP is not necessarily exploited by widening the pipelines and adding more resources Processor policies towards fetching decoding, and executing instruction have significant effect on its ability to discover instructions which can be executed concurrently Instruction issue policy limits or enhances performance because it determines the processor’s look ahead capability 07 Mar 2013 EE-739@IITB 3 CADSL
Highway 11 Mar 2013 EE-739@IITB 4 CADSL
Bad Traffic 11 Mar 2013 EE-739@IITB 5 CADSL
Instruction Flow Instruction Flow Objective: Fetch multiple instructions per cycle • Challenges : PC Branches: control dependences Instruction Memory Branch target misalignment 3 instructions fetched Instruction cache misses 11 Mar 2013 EE-739@IITB 6 CADSL
Instruction Fetch Fetch s instructions from I-cache I-Cache must be wide enough that each row of the I-Cache array can store s instructions and that an entire row can be accessed Fetch width = Row width Assume access latency is 1 cycle 11 Mar 2013 EE-739@IITB 7 CADSL
I-Cache Organization I-Cache Organization Tag Tag D Tag E C Tag 1 cache line = 1 physical row 11 Mar 2013 EE-739@IITB 8 CADSL
I-Cache Organization I-Cache Organization Tag D E Tag C Tag 1 cache line = 2 physical rows 11 Mar 2013 EE-739@IITB 9 CADSL
Instruction Flow Instruction Flow Objective: Fetch multiple instructions per cycle • Challenges: – Branches: control dependences – Branch target misalignment – Instruction cache misses • Solutions – Code alignment (static vs. dynamic) – Prediction/speculation 11 Mar 2013 EE-739@IITB 10 CADSL
Fetch Alignment Fetch Alignment 11 Mar 2013 EE-739@IITB 11 CADSL
Instruction Fetch 2 – way set associative I-Cache with a line size of 16 instructions (64 bytes) Each row of the I-Cache stores 4 associative sets 9two per set) of instructions Each line of I-cache spans four physical rows Physical I-cache array is actually composed of 4 independent sub-arrays One instruction can be accessed form one array 11 Mar 2013 EE-739@IITB 12 CADSL
RIOS-I Fetch Hardware RIOS-I Fetch Hardware 11 Mar 2013 EE-739@IITB 13 CADSL
Issues in Decoding Issues in Decoding • Primary Tasks Identify individual instructions (!) Determine instruction types Determine dependences between instructions • Two important factors Instruction set architecture Pipeline width 11 Mar 2013 EE-739@IITB 14 CADSL
Pentium Pro Fetch/Decode Pentium Pro Fetch/Decode 11 Mar 2013 EE-739@IITB 15 CADSL
Thank You 11 Mar 2013 EE-739@IITB 16 CADSL
Recommend
More recommend
Unleash a World of Digital Possibilities—Browse, Share, and Explore Content Without Boundaries