
Recall: A Linear Classifier A Line (generally hyperplane) that - PowerPoint PPT Presentation
Support Vector Machine Debapriyo Majumdar Data Mining Fall 2014 Indian Statistical Institute Kolkata November 3, 2014 Recall: A Linear Classifier A Line (generally hyperplane) that separates the two classes of
Support ¡Vector ¡Machine ¡ Debapriyo Majumdar Data Mining – Fall 2014 Indian Statistical Institute Kolkata November 3, 2014
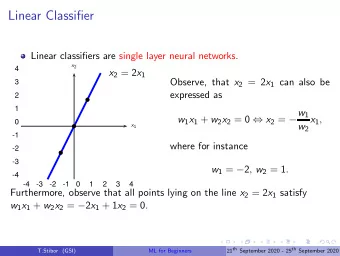
Recall: ¡A ¡Linear ¡Classifier ¡ A Line (generally hyperplane) that separates the two classes of points Choose a “good” line § Optimize some objective function § LDA: objective function depending on mean and scatter § Depends on all the points There can be many such lines , many parameters to optimize 2 ¡
Recall: ¡A ¡Linear ¡Classifier ¡ § What do we really want? § Primarily – least number of misclassifications § Consider a separation line § When will we worry about misclassification? § Answer: when the test point is near the margin § So – why consider scatter, mean etc (those depend on all points), rather just concentrate on the “border” 3 ¡
Support ¡Vector ¡Machine: ¡intui:on ¡ support vectors § Recall: A projection line w support vectors for the points lets us define a separation line L § How? [not mean and scatter] § Identify support vectors , the training data points that act as “support” § Separation line L between support vectors w L 2 L 1 L § Maximize the margin : the distance between lines L 1 and L 2 (hyperplanes) defined by the support vectors 4 ¡
Basics ¡ Distance of L from origin w 1 x 1 + w 2 x 2 = a a 2 = a 2 + w 2 w w 1 L : w • x = a a w w 5 ¡
Support ¡Vector ¡Machine: ¡formula:on ¡ L 1 : w • x + b = − 1 § Scale w and b such that we L 2 : w • x + b = 1 have the lines are defined by these equations § Then we have: d ( 0 , L 1 ) = − 1 − b , d ( 0 , L 2 ) = 1 − b w w § The margin (separation of the two classes) d ( L 1 , L 2 ) = 2 w w L : w • x + b = 0 min w , min w , Consider the classes as w T x + b ≤ − 1, ∀ x ∈ class 1 another dimension y i =- 1, +1 y i ( w T x ) ≥ 1, ∀ i w T x + b ≥ 1, ∀ x ∈ class 2 6 ¡
Langrangian ¡for ¡Op:miza:on ¡ § An optimization problem minimize f ( x ) subject to g ( x ) = 0 § The Langrangian: L ( x, λ ) = f ( x ) – λ g ( x ) where ∇ ( x , λ ) = 0 § In general (many constrains, with indices i ) ∑ L ( x , λ ) = f ( x ) + λ i g i ( x ) i 7 ¡
The ¡SVM ¡Quadra:c ¡Op:miza:on ¡ § The Langrangian of the SVM optimization: 2 − ∑ ∑ L P = w α i y i ( w • x i + b ) + α i i i α i ≥ 0 ∀ i § The Dual Problem α i − 1 ∑ ∑ max L = x i • x j α i α j 2 i i , j where The input vectors appear only ∑ w = y i x i α i in the form of dot products i ∑ y i = 0 α i i 8 ¡
Case: ¡not ¡linearly ¡separable ¡ x ! ( x 2 , x ) § Data may not be linearly separable § Map the data into a higher dimensional space § Data can become separable (by a hyperplane) in the higher dimensional space § Kernel trick § Possible only for certain functions when have a kernel function K such that K ( x i , x j ) = φ ( x i ) • φ ( x j ) 9 ¡
Non ¡– ¡linear ¡SVM ¡kernels ¡ 10 ¡
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.