Neural network applications ALVINN (Pomerleau, mid 1990s) - PowerPoint PPT Presentation
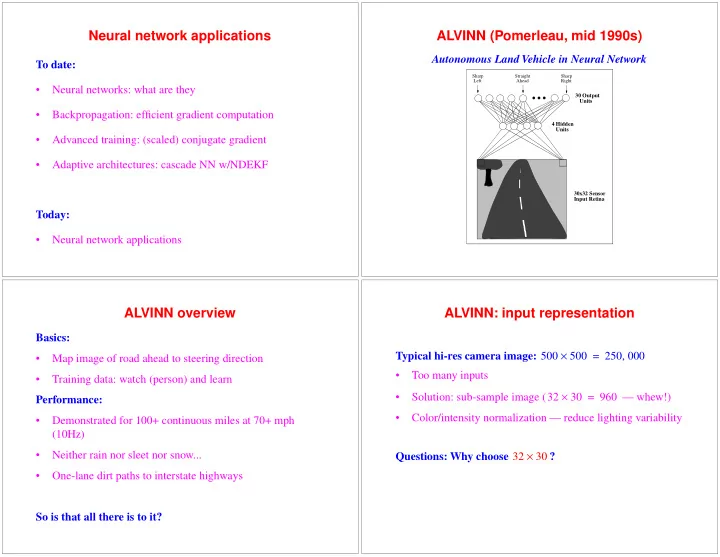
Neural network applications ALVINN (Pomerleau, mid 1990s) Autonomous Land Vehicle in Neural Network To date: Sharp Straight Sharp Left Ahead Right Neural networks: what are they 30 Output Units Backpropagation: efficient
Neural network applications ALVINN (Pomerleau, mid 1990s) Autonomous Land Vehicle in Neural Network To date: Sharp Straight Sharp Left Ahead Right • Neural networks: what are they 30 Output Units • Backpropagation: efficient gradient computation 4 Hidden Units • Advanced training: (scaled) conjugate gradient • Adaptive architectures: cascade NN w/NDEKF 30x32 Sensor Input Retina Today: • Neural network applications ALVINN overview ALVINN: input representation Basics: Typical hi-res camera image: 500 × 500 = 250 000 , • Map image of road ahead to steering direction • Too many inputs • Training data: watch (person) and learn • Solution: sub-sample image ( 32 × 30 = 960 — whew!) Performance: • Color/intensity normalization — reduce lighting variability • Demonstrated for 100+ continuous miles at 70+ mph (10Hz) • Neither rain nor sleet nor snow... × Questions: Why choose 32 30 ? • One-lane dirt paths to interstate highways So is that all there is to it?
ALVINN: input image example #1 ALVINN: input image example #2 ALVINN: output representation Gaussian output representation example 1 1 0.8 0.8 Output representation: two choices 0.6 0.6 • Single linear output 0.4 0.4 0.2 0.2 • Multiple outputs: Gaussian fit 0 0 -1 -0.5 0 0.5 1 -1 -0.5 0 0.5 1 Questions: 1 0.7 0.6 • Why choose particular output representation? 0.8 0.5 0.6 0.4 0.3 0.4 0.2 0.2 0.1 0 0 -1 -0.5 0 0.5 1 -1 -0.5 0 0.5 1
ALVINN: neural network architecture ALVINN: training data Problem: Person drives too well! Tried everything from one to 70 hidden units • Neural network does not learn error recovery Four to five hidden units worked best Solution: create synthetic data from real data Questions: • Why no direct input/output connections? • Why did larger networks not do better? ALVINN: synthetic images ALVINN: spurrious features Problem: What’s the correct steering direction? Examples of problem data: • Oil slicks, shadows • Pure pursuit model of how people driving • Other cars
Removing spurrious features ALVINN: other issues • Balance data (left/right/straight samples) (why?) Solution #1: Add Gaussian noise to image (problems?) • Training on-line ( vs. batch) Solution #2: Model spurrious features (problems?) • Hidden unit weights: a closer look Hidden Hidden Hidden Hidden Hidden Unit 1 Unit 2 Unit 3 Unit 4 Unit 5 Solution #3: Use neural network’s internal model • “Structured noise” • Learns to ignore peripheral features Epoch 50 ALVINN: conclusions RALPH: learning from ALVINN • ALVINN represented a huge step forward in Rapid Lateral Position Handler: autonomous driving (mid 1990s) • Probably most well-known NN application • Understanding ALVINN let to RALPH • Extensively tested at high speeds in real traffic • Took several years of analysis • Easy to understand technique • Next step: learning from ALVINN Question: • Which is better approach?
RALPH: basic algorithm Trapezoidal subsampling Key insight: don’t look at whole image For a given image: • Trapezoidal subsampling of image • Hypothesize a road curvature • Horizontally shift pixels to correspond to curvature hypothesis • Vertically add pixel intensities • Compute measure of curvature hypothesis correctness • Function of speed • Camera orientation w/respect to road (perspective) • No spurrious feature problem Trapezoidal subsampling: example #1 Trapezoidal subsampling: example #2 Why do trapezoidal subsampling? Note how key features line up to indicate curvature...
RALPH: basic algorithm RALPH: curvature hypothesis • Curvature hypothesis For a given image: • Horizontally shift pixels to correspond to curvature • Trapezoidal subsampling of image hypothesis • Curvature hypothesis • Horizontally shift pixels to correspond to curvature hypothesis • Vertically add pixel intensities • Compute measure of curvature hypothesis correctness RALPH: basic algorithm RALPH: curvature hypothesis evaluation • Vertically add pixel intensities For a given image: • Compute measure of curvature hypothesis correctness • Trapezoidal subsampling of image • Hypothesize a road curvature • Horizontally shift pixels to correspond to curvature hypothesis • Vertically add pixel intensities • Compute measure of curvature hypothesis correctness
RALPH performance ALVINN RALPH vs. “No Hands across America” • Washington, D.C. to San Diego (2,850 miles) • 98.1% autonomous (2,796 miles) Which is better? • 70 mph top speed (officially) • 110 mph top speed (unofficially) Lines are useful, but RALPH doesn’t need them... Failure modes... Neural network applications Face detection (Kanade, late 1990s) Road following Basics: • ALVINN: Road following × ± • Map 20 20 image to 1 (face/non-face) • RALPH: learning from neural networks Face detection Performance: Robot control • Face detection results: 85%-90%, few false detects × • 1.5Hz - 3.5Hz on PII/450 ( 320 240 )
Face detection Image preprocessing Outline: Oval mask for ignoring background pixels: • Which part of image to look at? Original window: • Image pre-processing • Specialized neural network architecture Best fi t linear function: • Training data Lighting corrected window: (linear function subtracted) • Overlap detection Histogram equalized window: • Committee of experts: multiple neural networks • Results Face detection Specialized neural network architecture Histogram equalize Receptive fields Hidden units Outline: • Which part of image to look at? Network • Image pre-processing Output Input • Specialized neural network architecture 20 by 20 pixels • Training data • Overlap detection • Committee of experts: multiple neural networks • Results Neural network
Face detection NN training data: face examples Outline: • Which part of image to look at? • Image pre-processing • Specialized neural network architecture • Training data • Overlap detection • Committee of experts: multiple neural networks • Results Generating non-face examples NN training data: nonface examples
✠ ✟ ✏ ✎ ✎ ✍ ✌ ☞ ☛ ✡ ✠ ✟ ✞ ✒ ✝ ✝ ✆ ✆ ☎ ✄ ✄ ✂ ✂ ✁ ✁ ✑ ✒ � ✜ ✥ ✥ ✥ ✥ ✥ ✥ ✥ ✥ ✤ ✣ ✢ ✛ ✓ ✛ ✚ ✙ ✘ ✗ ✗ ✖ ✕ ✕ ✔ ✓ � Basic NN detection results Face detection Outline: • Which part of image to look at? Missed Detect False • Image pre-processing Type System faces rate detects Single 1) Network 1 (2 copies of hidden units (52 total), 45 91.1% 945 network, 2905 connections) • Specialized neural network architecture 2) Network 2 (3 copies of hidden units (78 total), 38 92.5% 862 no 4357 connections) heuristics 3) Network 3 (2 copies of hidden units (52 total), 46 90.9% 738 • Training data 2905 connections) 4) Network 4 (3 copies of hidden units (78 total), 40 92.1% 819 4357 connections) Single 5) Network 1 threshold(2,1) overlap elimination 48 90.5% 570 • Overlap detection • Committee of experts: multiple neural networks • Results Overlap detection NN results w/overlap detection Missed Detect False Input image pyramid, "Output" pyramid: Spreading out detections Collapse clusters to Potential face locations Final result after removing detections overlaid centers of detections in x and y, not in scale centroid of detections extended across scale overlapping detection Type System faces rate detects Single 1) Network 1 (2 copies of hidden units (52 total), 45 91.1% 945 network, 2905 connections) 2) Network 2 (3 copies of hidden units (78 total), 38 92.5% 862 no 4357 connections) heuristics Final detection result 3) Network 3 (2 copies of hidden units (52 total), 46 90.9% 738 2905 connections) 4) Network 4 (3 copies of hidden units (78 total), 40 92.1% 819 4357 connections) Single 5) Network 1 threshold(2,1) overlap elimination 48 90.5% 570 False detect network, 6) Network 2 threshold(2,1) overlap elimination 42 91.7% 506 with heuristics 7) Network 3 threshold(2,1) overlap elimination 49 90.3% 440 Face locations and scales Centroids (in position and scale) Overlapping detections represented by centroids A B C D E 8) Network 4 threshold(2,1) overlap elimination 42 91.7% 484 Input image pyramid Computations on output pyramid Final result
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.