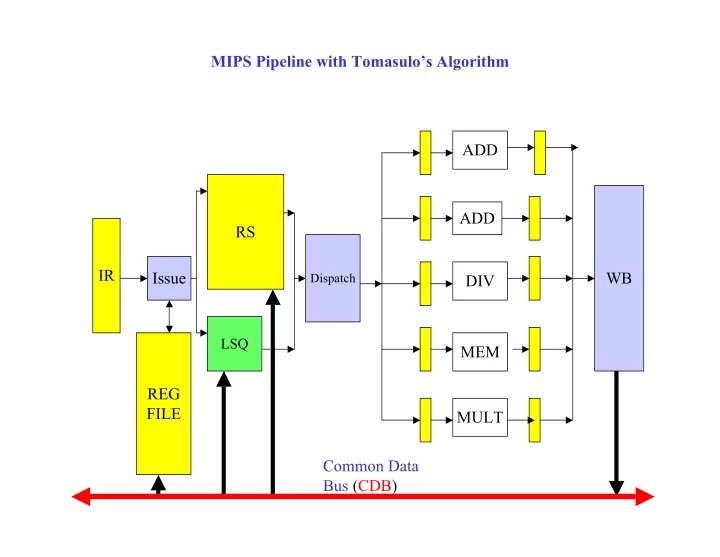
MIPS Pipeline with Tomasulos Algorithm ADD ADD RS IR Issue WB - PowerPoint PPT Presentation
MIPS Pipeline with Tomasulos Algorithm ADD ADD RS IR Issue WB Dispatch DIV LSQ MEM REG FILE MULT Common Data Bus (CDB) Example LOOP: A LD F0, 0(R1) | temp = x[i] B MUL F4, F0, F2 | temp = temp * a C SD F4, 0(R1) |
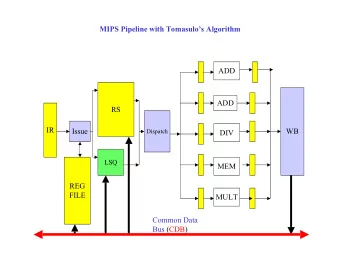
MIPS Pipeline with Tomasulo’s Algorithm ADD ADD RS IR Issue WB Dispatch DIV LSQ MEM REG FILE MULT Common Data Bus (CDB)
Example LOOP: A LD F0, 0(R1) | temp = x[i] B MUL F4, F0, F2 | temp = temp * a C SD F4, 0(R1) | x[i] = temp D ADDI R1, R1, #8 | i++ E BNE R1, R2, LOOP | branch if R1.ne.R2 Within an iteration RAW between (A, B) and (C, D) [focusing on FP registers only] • Across iterations WAR and WAW dependencies become apparent • A1 LD F0 , 0(R1) | temp = x[i] B1 MUL F4 , F0 , F2 | temp = temp * a C1 SD F4 , 0(R1) | x[i] = temp D1 ADDI R1, R1, #8 | i++ E1 BNE R1, R2, LOOP | branch if R1.ne.R2 A2 LD F0, 0(R1) | temp = x[i] B2 MUL F4, F0, F2 | temp = temp * a C2 SD F4, 0(R1) | x[i] = temp D2 ADDI R1, R1, #8 | i++ E2 BNE R1, R2, LOOP | branch if R1.ne.R2 2
Example LOOP: A LD F0, 0(R1) | temp = x[i] B MUL F4, F0, F2 | temp = temp * a C SD F4, 0(R1) | x[i] = temp D ADDI R1, R1, #8 | i++ E BNE R1, R2, LOOP | branch if R1.ne.R2 Within an iteration RAW between (A, B) and (C, D) [focusing on FP registers only] • Across iterations WAR and WAW dependencies become apparent • A1 A2 A3 A1 A2 A3 B1 B2 B3 B1 B2 B3 C1 C2 C3 C1 C2 C3 Renaming removes WAR and WAW dependencies 3
In-Order Scheduling of MEM Operations 5 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 A1 IF I D M W B1 IF I D D * * * * W C1 IF I D D D D D D M D1 IF I E W E1 IF I E W A2 IF I D D D M W B2 IF I D D D D * * * * W C2 IF I D D D D D D D D M D2 IF I E W E2 IF I E W IF I D D D D D D M W 7
Load Store Queue (LSQ) ISSUE MEM DISPATCH WRITE A1 C1 LOAD/STORE Q CDB • Since MEM access is in general a multi-cycle operation: buffer several LOAD/STORE instructions. • Snapshot at Cycle 4 8
Load Store Queue (LSQ) ISSUE MEM DISPATCH WRITE C2 A2 C1 LOAD/STORE Q CDB • Since MEM access is in general a multi-cycle operation: buffer several LOAD/STORE instructions. • Snapshot at end of Cycle 10 • Can I promote A2 ahead of C1 and let it use MEM during cycle 10? 8
Load Store Queue (LSQ) ISSUE MEM DISPATCH WRITE A2 C2 C1 LOAD/STORE Q CDB • Since MEM access is in general a multi-cycle operation: buffer several LOAD/STORE instructions. • Snapshot at end of Cycle 10 • Can I promote A2 ahead of C1 and let it use MEM during cycle 10? 8
Schedule 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 LD IF I D M W MUL IF I D D * * * * W SD IF I D D D D D D M ADD IF I E W BEQ IF I E W LD IF I D M W MUL IF I D D * * * * W SD IF I D D D D D D M ADD IF I E W BEQ IF I E W IF I D M W 4 T = 6(n-1) + 11 = 6n + 5 cycles for n iterations
LSQ Features Assume memory address of the Load/Store (ea) is calculated during Issue and stored as • part of the Load or Store buffer in the LSQ The register source of a Store either copies the current register value or waits for an • earlier instruction to broadcast its result on the CDB (same as other instructions). ILP affected by size of the LSQ • FIFO buffer provides simple implementation for FCFS scheduling • Greater concurrency by out-of-order scheduling • In example: • C1 (Store of iteration 1) does memory write at cycle 11 • A2 (Load of iteration 2) does memory read at cycle 10 • • C1 was stalled on an RAW waiting for data • We promoted the later load (L2) ahead of the earlier store (C1) • Is this OK? • Under what conditions? 9
Example LOOP: A LD F0, 0(R1) | temp = x[i] B MUL F4, F0, F2 | temp = temp * a C SD F4, 0(R1) | x[i] = temp D ADDI R1, R1, #8 | i++ E BNE R1, R2, LOOP | branch if R1.ne.R2 How about dependencies between memory operations? Need to ensure these dependencies A1 A2 A3 a) do not exist or RAW? b) do not result in memory data hazards. B1 B2 B3 W A R C1 C2 C3 WAW ? 5
Load Store Queue (LSQ) ISSUE MEM DISPATCH WRITE C B LOAD/STORE Q CDB • Since MEM access is in general a multi-cycle operation: buffer several LOAD/STORE instructions. • Question: • Is the order of serving memory requests important? 8
Load Store Queue (LSQ) ISSUE MEM DISPATCH WRITE C B LOAD/STORE Q CDB • Since MEM access is in general a multi-cycle operation: buffer several LOAD/STORE instructions • An instruction that is ready to execute can be dispatched to MEM while others wait for operand • Example 2: Can we promote C (Store) over an earlier waiting store (B)? A: MULD F0, F2, F4 B: SD F0, 0(R2) C: SD F2, 100(R4) 11
Load Store Queue (LSQ) ISSUE MEM DISPATCH WRITE D C B LOAD/STORE Q CDB • Example: A: MULD F0, F2, F4 B: SD F0, 0(R2) C: SD F2, 100(R4) D: LD F6, 200(R6) • Can one promote the LD (instruction) D in front of B and C? • Memory Disambiguation: Need to avoid RAW, WAR, WAW hazards through memory 12
Memory Disambiguation A: MULD F0, F2, F4 B: SD F0, 0(R2) C: SD F2, 100(R4) D: LD F6, 200(R6) E: SD F8, 100(R2) Instructions may have data dependencies through memory if they read or write the same memory location • Since the memory address is only known after the LOAD/STORE is issued run-time checks required • Memory disambiguation logic in the LSQ is required to see if memory instructions can be executed out of order • • RAW Newly issued LOAD must be compared for possible RAW hazards against all currently • pending STORE instructions When D is issued: • Compare effective address of D (LD) against the addresses of pending stores: B and C • If no addresses match: safe to promote D and load from memory before the two stores • Load Forwarding: Optimization possible for LOAD • If there is a pending STORE with address matching that of the the issuing LOAD • LOAD can obtain its value directly from the Store Buffer without accessing memory • Need to choose the closest STORE if several matching pending STOREs in the queue • 13
Memory Disambiguation A: MULD F0, F2, F4 B: SD F0, 0(R2) C: SD F2, 100(R4) D: LD F6, 200(R6) E: SD F8, 100(R2) Instructions may have data dependencies through memory if they read or write the same memory location • Since the memory address is only known after the LOAD/STORE is issued run-time checks required • • WAR STORE must not overtake a LOAD with matching address • • WAW If an issuing STORE has the same address as a pending STORE • If LOAD FORWARDING is being employed: • All LOADS from that memory address have already received their value • Only purpose of the pending STORE is to update the memory location • Cancel (remove from queue) pending STORE • 14
Load Store Queue (LSQ) LOAD Q MEM ISSUE MEM DISPATCH WRITE MEM STORE Q CDB • Useful to give LOADs priority over STOREs • Use LOAD FORWARDING to bypass memory • WAR to memory (earlier LD completing after later SD) will not occur • Use WRITE MERGING to collapse several writes to the same location 15
Implementation Issues with Tomasulo’s Algorithm Instructions tagged with id of Reservation Station they are issued to • Unique RS for each issued instruction • TAG serves to identify the instruction uniquely • Tag the destination register with TAG • Tag all source fields of later instructions that match this destination with TAG • TAG carried with the instruction to the WB stage so that the completing instruction is identified • in the CDB broadcast Results of completing instructions are broadcast on a bus known as Common Data Bus (CDB) • REGISTER FILE, RESERVATION STATIONS, LOAD/STORE BUFFERS monitor CDB • TAG of completing instruction broadcast along with value • Broadcasts on bus must be serialized • Distributed Control • Registers and RS and LSQ entries self-identify whether or not they are the target of the • broadcast by comparing their tag with broadcast TAG Associative Search hardware • Centralized Controller • Maintains bit vector of destinations for each possible outstanding tag value • Routes data broadcast on CDB to units waiting on TAG • 16
Summary of Pipelined Architectures •Pipeline Issue Execute Write • Simple 5-stage In-order In-order In-order • Multi-cycle 5-stage In-order In-order Out-of-order • Scoreboard In-order Out-of-order Out-of-order • Tomasulo In-order Out-of-order Out-of-order • Maintaining precise interrupts : • Complicated when instructions can complete (write) out of order. • Earlier instruction may raise interrupt long after later instructions have completed. • Solutions : 1. Allow imprecise interrupts Not permitted by IEEE Standard 2. Stall pipeline as needed to ensure in-order writes Reduces potential parallelism 3. Trap handlers restore machine to consistent state using saved information Ad-hoc (machine dependent solution) 4. Reorder Buffer: • Buffer the results of completing instructions reorder them and writethem in order • Idea of reorder buffer can be used to implement aggressive branch speculation 17
Recommend




















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.