
LINEAR CLASSIFIER V aclav Hlav a c Czech Technical University, - PowerPoint PPT Presentation
1/44 LINEAR CLASSIFIER V aclav Hlav a c Czech Technical University, Faculty of Electrical Engineering Department of Cybernetics, Center for Machine Perception 121 35 Praha 2, Karlovo n am. 13, Czech Republic http://cmp.felk.cvut.cz
1/44 LINEAR CLASSIFIER V´ aclav Hlav´ aˇ c Czech Technical University, Faculty of Electrical Engineering Department of Cybernetics, Center for Machine Perception 121 35 Praha 2, Karlovo n´ am. 13, Czech Republic http://cmp.felk.cvut.cz hlavac@fel.cvut.cz, LECTURE PLAN � Rehearsal: linear classifiers and its importance. � Learning linear classifiers. Three formulations. � Generalized Anderson task. First part. � Perceptron and Kozinec algorithm. � Generalized Anderson task. Second part.
CLASSIFIER 2/44 Analyzed object is represented by X – space of observations K – set of hidden states Aim of the classification is to determine a relation between X and K , i.e. to find a function f : X → K . Classifier q : X → J maps observations X n → set of class indices J , J = 1 , . . . , | K | . Mutual exclusion of classes X = X 1 ∪ X 2 ∪ . . . ∪ X | K | , X 1 ∩ X 2 ∩ . . . ∩ X | K | = ∅ .
CLASSIFIER, ILLUSTRATION 3/44 � A classifier partitions observation space X into class-labelled regions. � Classification determines to which region an observation vector x belongs. � Borders between regions are called decision boundaries.
RECOGNITION (DECISION) STRATEGY 4/44 f i ( x ) > f j ( x ) for x ∈ class i , i � = j. f (x) 1 X K f (x) 2 max f (x) |K| Strategy j = argmax f j ( x ) j
WHY ARE LINEAR CLASSIFIERS IMPORTANT? (1) 5/44 Theoretical importance – Bayesian decision rule decomposes the space of probabilities into convex cones. p (x) p (x) X|3 X|3 p (x) p (x) X|2 X|2 p (x) p (x) X|1 X|1
WHY ARE LINEAR CLASSIFIERS IMPORTANT? (2) 6/44 � For some statistical models, the Bayesian or non-Bayesian strategy is implemented by a linear discriminant function. � Capacity (VC dimension) of linear strategies in an n -dimensional space is n + 2 . Thus, the learning task is correct, i.e., strategy tuned on a finite training multiset does not differ much from correct strategy found for a statistical model. � There are efficient learning algorithms for linear classifiers. � Some non-linear discriminant functions can be implemented as linear after straightening the feature space.
LINEAR DISCRIMINANT FUNCTION q ( x ) 7/44 � f j ( x ) = � w j , x � + b j , where � � denotes a scalar product. � A strategy j = argmax f j ( x ) divides X into | K | convex j regions. k=6 k=5 k=1 k=2 k=4 k=3
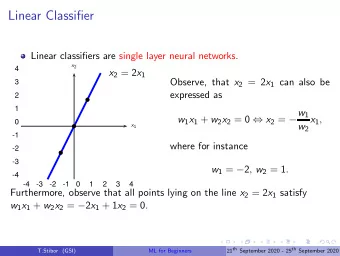
DICHOTOMY, TWO CLASSES ONLY 8/44 | K | = 2 , i.e. two hidden states (typically also classes) k = 1 , if � w, x � + b ≥ 0 , q ( x ) = � w, x � + b < 0 . k = 2 , if x 1 x 2
LEARNING LINEAR CLASSIFIERS 9/44 The aim of learning is to estimate classifier parameters w i , b i for ∀ i . The learning algorithms differ by � The character of training set 1. Finite set consisting of individual observations and hidden states, i.e., { ( x 1 , y 1 ) . . . ( x L , y L ) } . 2. Infinite sets described by Gaussian distributions. � Three learning task formulations.
3 LEARNING TASK FORMULATIONS 10/44 � Minimization of the empirical risk. � Minimization of a real risk margin. � Generalized Anderson task.
MINIMIZATION OF THE EMPIRICAL RISK 11/44 True risk is approximated by L � R emp ( q ( x, Θ)) = 1 W ( q ( x i , Θ) , y i ) , L i =1 where W is a penalty function. Learning is based on the empirical minimization principle Θ ∗ = argmin R emp ( q ( x, Θ)) Θ Examples of learning algorithms: Perceptron, Back-propagation, etc.
OVERFITTING AND UNDERFITTING 12/44 � How rich class of classifications q ( x, Θ) has to be used? � Problem of generalization: a small emprical risk R emp does not imply a small true expected risk R . underfit fit overfit
MINIMIZATION OF A REAL RISK MARGIN (1) 13/44 Risk � R ( f ) = W ( q ( x i , Θ) , k ) p ( x, k ) dx dk , x,k where � W ( q ( x i , Θ) is a loss function, � p ( x, k ) is not known.
STRUCTURAL RISK MINIMIZATION PRINCIPLE 14/44 � R ( f ) = W ( q ( x i , Θ) , k ) p ( x, k ) dx dk , x,k where p ( x, k ) is not known. Margin according to Vapnik, Chervonenkis is � � h, 1 R ( f ) ≤ R emp ( f ) + R str , L where h is VC dimension (capacity) of the class of strategies q .
MINIMIZATION OF A REAL RISK MARGIN (2) 15/44 � For linear discriminant functions R VC dimension (capacity) m h ≤ R 2 m 2 + 1 � Examples of learning algorithms: SVM or ε -Kozinec. � � � w, x � + b � w, x � + b ( w ∗ , b ∗ ) = argmax min min , min . | w | | w | x ∈ X 1 x ∈ X 2 w,b
TOWARDS GENERALIZED ANDERSON TASK 16/44 � X is an observation space (a multidimensional linear space). � x ∈ X is a single observation. � k ∈ K = { 1 , 2 } is a hidden state. � It is assumed that p X | K ( x | k ) is a multi-dimensional Gaussian distribution. � The mathematical expectation µ k and the covariance matrix σ k , k = 1 , 2 , of these probability distributions are not known.
TOWARDS GAnderssonT (2) 17/44 � It is known that the parameters ( µ 1 , σ 1 ) belong to a certain finite set of parameters { ( µ j , σ j ) | j ∈ J 1 } . � Similarly ( µ 2 , σ 2 ) are also unknown parameters belonging to the finite set { ( µ j , σ j ) | j ∈ J 2 } . � Superscript and subscript indices are used. � µ 1 and σ 1 mean real, but unknown, parameters of an object that is in the first state. Parameters ( µ j , σ j ) for some of the superscripts j are one � of the possible value pairs which the parameter can assume.
GAndersonT ILLUSTRATED IN 2D SPACE 18/44 Illustration of the statistical model, i.e., mixture of Gaussians. q k=1 � � � � � � � � � � k=2 Unknown are weights of the Gaussian components.
GAndersonT, FORMULATION (1) 19/44 � If there is a non-random hidden parameter then Bayesian approach cannot be used. p ( x | k, z ) is influenced by a non-random intervention z . � Divide and conquer approach. For X ( k ) , k ∈ K X ( k ) = X 1 ( k ) ∪ . . . ∪ X | K | ( k ) . � Probability of the wrong classification for given k and z � p ( x | k, z ) . ε ( k, z ) = x/ ∈ X ( k )
GAndersonT, FORMULATION (2) 20/44 � Learning algorithm ( x ∗ ( k ) , k ∈ K ) = argmin p ( x | k, z ) . x ( k ) ,k ∈ K ′ max max z k � Particularly for Generalized Anderson task • 2 hidden states only, K = { 1 , 2 } . • Separation of X ( k ) , k = { 1 , 2 } using the hyperplane � w, x � + b = 0 . • p ( x | k, z ) is a Gaussian distribution.
GAndersonT, FORMULATION (3) 21/44 � Seeking a strategy q : X → { 1 , 2 } which minimises j ∈ J 1 ∪ J 2 ε ( j, µ j , σ j , q ) , max where ε ( j, µ j , σ j , q ) is the probability that the Gaussian random vector x with mathematical expectation µ j and the covariance matrix σ j satisfies either the relation q ( x ) = 1 for j ∈ J 2 or q ( x ) = 2 for j ∈ J 1 . � Additional constraint (linearity of the classifier) � � w, x � > b , 1 , if q ( x ) = � w, x � < b . 2 , if
SIMPLIFICATION OF GAndersonT (1) 22/44 Anderson–Bahadur task � A special case of GAndersonT solved in 1962. � For | J 1 | = | J 2 | = 1 . � Anderson, T. and Bahadur, R. Classification into two multivariate normal distributions with different covariance matrices. Annals of Mathematical Statistics , 1962, 33:420–431.
SIMPLIFICATION OF GAndersonT (2) 23/44 Optimal separation of a finite sets of points Finite set of observations � � X = x 1 , x 2 , . . . , x n has to be decomposed into � X 1 and � X 2 , � X 1 ∩ � X 2 = ∅ . � w, x � > b for x ∈ � � X 1 . � w, x � < b for x ∈ � X 2 . � under the condition � � � w, x � − b b − � w, x � argmax min min , min | w | | w | x ∈ � x ∈ � w,b X 1 X 2
SIMPLIFICATION OF GAndersonT (3) 24/44 Simple separation of a finite sets of points Finite set of observations � � X = x 1 , x 2 , . . . , x n has to be decomposed into � X 1 and � X 2 , � X 1 ∩ � X 2 = ∅ . � w, x � > b for x ∈ � � X 1 . � w, x � < b for x ∈ � X 2 . The division hyperplane can lie anywhere between sets � � X 1 and � X 2 .
GOOD NEWS FOR GAndersonT 25/44 � The minimised optimisation criterion will appear to be unimodal. � Steepest descent optimization methods can be used with which the optimum can be found without being stuck in local extremes. � Bad news: minimised unimodal criterion is neither convex, nor differentiable. Therefore neither calculating the gradient, nor that the gradient in the point corresponding to the minimum is equal to zero can be applied. � Convex optimisation techniques alow to solve the problem.
EQUIVALENT FORMULATION OF GAndersonT 26/44 Without loss of generality we can assume that the recognition strategy based on comparing the value of the linear function � w, x � with the threshold value b � w, x � + b > 0 can be replaced by an equivalent strategy making decision according to the sign of the linear function � w ′ , x ′ � � w ′ , x ′ � > 0 .
ORIGINAL FORMULATION 27/44 w, x + b = 0 n X � w, x j � + b > 0 , j ∈ J 1 � w, x j � + b < 0 , j ∈ J 2
EQUIVALENT FORMULATION, through origin 28/44 Embedding into n + 1 -dimensional space w ′ = ( w 1 , w 2 , . . . , w n , − b ) n+1 X w’, x’ = 0 x ′ = ( x 1 , x 2 , . . . , x n , 1) � w ′ , x ′ j � > 0 , j ∈ J 1 � w ′ , x ′ j � < 0 , j ∈ J 2
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.