
Gen enerativ erative e Adver ersaria sarial l Im Imitation - PowerPoint PPT Presentation
Gen enerativ erative e Adver ersaria sarial l Im Imitation itation Le Learning arning Stefan efano o Ermon on Joint work with Jayesh Gupta, Jonathan Ho, Yunzhu Li, Hongyu Ren, and Jiaming Song Reinforcement Learning Goal: Learn
Gen enerativ erative e Adver ersaria sarial l Im Imitation itation Le Learning arning Stefan efano o Ermon on Joint work with Jayesh Gupta, Jonathan Ho, Yunzhu Li, Hongyu Ren, and Jiaming Song
Reinforcement Learning • Goal: Learn policies • High-dimensional, raw observations action
Reinforcement Learning • MDP: Model for (stochastic) sequential decision making problems +5 +1 • States S • Actions A • Co Cost st function (immediate): C: SxA R • Transition Probabilities: P(s’| s,a) 0 • Policy: mapping from states to actions – E.g., (S 0 ->a 1 , S 1 ->a 0 , S 2 ->a 0 ) • Reinforcement learning: minimize total (expected, discounted) cost 1 T ( ) c s t t 0
Reinforcement Learning Cost Function Optimal Reinforcement c(s,a) policy p Learning (RL) Policy: mapping from states to actions C: SxA R Environment E.g., (S 0 ->a 1 , (MDP) S 1 ->a 0 , Cost S 2 ->a 0 ) +5 +1 • States S • Actions A RL nee eeds ds • Transitions: P( s’ |s, a) cost st sig ignal 0
Imitation Input: expert behavior generated by π E Goal: learn cost function (reward) or policy (Ng and Russell, 2000), (Abbeel and Ng, 2004; Syed and Schapire, 2007), (Ratliff et al., 2006), (Ziebart et al., 2008), (Kolter et al., 2008), (Finn et al., 2016), etc.
Behavioral Cloning (State,Action) (State,Action) Policy … (State,Action) Supervised Learning (regression) • Small errors compound over time (cascading errors) • Decisions are purposeful (require planning)
Inverse RL • An approach to imitation • Learns a cost c such that
Problem setup Optimal Cost Function Reinforcement c(s) policy p Learning (RL) Environment (MDP) Inverse Reinforcement Expert’s Trajectories Cost Function Learning (IRL) s 0 , s 1 , s 2 , … c(s) Expert has Everything else (Ziebart et al., 2010; small cost has high cost Rust 1987) 15
Problem setup Optimal Cost Function Reinforcement c(s) policy p Learning (RL) ≈ ? Environment (similar wrt ψ ) (MDP) Inverse Reinforcement Expert’s Trajectories Cost Function Learning (IRL) s 0 , s 1 , s 2 , … c(s) Convex cost regularizer 16
Combining RL o IRL ρ p = occupancy measure = Optimal Reinforcement distribution of state-action pairs policy p Learning (RL) encountered when navigating ≈ the environment with the policy (similar w.r.t. ψ ) ρ pE = Expert’s ψ -regularized Inverse Expert’s Trajectories Reinforcement occupancy measure s 0 , s 1 , s 2 , … Learning (IRL) Theorem orem: ψ -regularized inverse reinforcement learning, implicitly, seeks ks a polic icy y whose e occupancy ncy measure sure is close e to the expert’s , as measured by ψ * (convex conjugate of ψ ) 17
Takeaway Theorem rem: ψ -regularized inverse reinforcement learning, implicitly, se seeks s a poli licy cy wh whose se occupancy upancy measure sure is s close to the expert’s , as measured by ψ * • Typical IRL definition: finding a cost function c such that the expert policy is uniquely optimal w.r.t. c • Alternative view: IRL as a procedure that tries to induce a policy that matches the expert’s occupancy measure (gene nerati rative model)
Special cases • If ψ (c)=constant, then – Not a useful algorithm. In practice, we only have sampled trajectories • Ov Overfitting: itting: Too much flexibility in choosing the cost function (and the policy) All cost functions ψ (c)=constant
Towards Apprenticeship learning • Solu lution: tion: use fea eatu tures res f s,a ) = θ . f s,a • Cost st c( c(s,a s,a) Only these “simple” cost functions are allowed ψ(c)= ∞ Linear in features All cost functions ψ (c)= 0 20
Apprenticeship learning • For that choice of ψ , RL o IRL ψ framework gives apprenticeship learning • Apprenticeship learning: find π performing better than π E over costs linear in the features – Abbeel and Ng (2004) – Syed and Schapire (2007)
Apprenticeship learning • Given • Goal: find π performing better than π E over a class of costs Approximated using demonstrations
Issues with Apprenticeship learning • Need to craft features very carefully – unless the true expert cost function (assuming it exists) lies in C, there is no guarantee that AL will recover the expert policy • RL o IRL ψ ( p E ) is “encoding” the expert behavior as a cost function in C. – it might not be possible to decode it back if C is too simple All cost functions RL p R IRL p E
Generative Adversarial Imitation Learning • Solu lution tion: use a more expressive class of cost functions All cost functions Linear in features
Generative Adversarial Imitation Learning • ψ * = optimal negative log-loss of the binary classification problem of distinguishing between state- action pairs of π and π E Policy π Expert Policy π E D
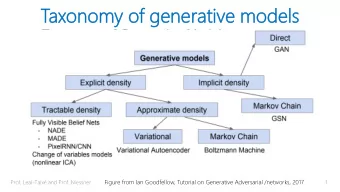
Generative Adversarial Networks Figure from Goodfellow et al, 2014
GAIL D tries to D tries to output 1 output 0 Differentiable Differentiable function D function D Sample from Sample from model expert Simulator Black box simulator (Environment) Generator G Differentiable function P Ho and Ermon, Generative Adversarial Imitation Learning
How to optimize the objective • Previous Apprenticeship learning work: – Full dynamics model – Small environment – Repeated RL • We propose: gradient descent over policy parameters (and discriminator) J. Ho, J. K. Gupta, and S. Ermon. Model-free imitation learning with policy optimization. ICML 2016.
Properties • Inherits pros of policy gradient – Convergence to local minima – Can be model free • Inherits cons of policy gradient – High variance – Small steps required
Properties • Inherits pros of policy gradient – Convergence to local minima – Can be model free • Inherits cons of policy gradient – High variance – Small steps required • Solu lution: tion: tr trust t reg egion ion policy licy optim timizat ization ion
Results
Results Input: driving demonstrations (Torcs) Output policy: From m raw visual al inputs uts Li et al, 2017. InfoGAIL: Interpretable Imitation Learning from Visual Demonstrations
Experimental results
Latent structure in demonstrations Human model Observed Latent variables Environment Policy Behavior Z Semantically meaningful latent structure? 35
InfoGAIL Observed Latent structure data Infer structure Hou el al. Maximize mutual information Observed Latent variables Environment Policy Behavior Z
InfoGAIL Latent code Maximize mutual information (s,a ,a) Observed Environment c Policy Z Behavior
Synthetic Experiment Demonstrations GAIL Info-GAIL Demonstrations
InfoGAIL Li et al, 2017. InfoGAIL: Interpretable Imitation Learning from Visual Demonstrations model Latent variables Trajectories Environment Policy Z Pass right (z=1) Pass left (z=0) 40
InfoGAIL Li et al, 2017. InfoGAIL: Interpretable Imitation Learning from Visual Demonstrations model Latent variables Trajectories Environment Policy Z Turn outside (z=1) Turn inside (z=0) 41
Multi-agent environments What are the goals of these 4 agents?
Problem setup Optimal policies p1 Cost Functions c 1 (s,a 1 ) … MA Reinforcement .. Learning (MARL) c N (s,a N ) Optimal policies pK Environment (Markov Game) R L R 0,0 10,10 L 10,10 0,0
Problem setup Cost Functions Optimal c 1 (s,a 1 ) MA Reinforcement .. policies p Learning (MARL) c N (s,a N ) ≈ Environment (similar wrt ψ ) (Markov Game) Expert’s Trajectories Cost Functions (s (s 0 ,a ,a 0 1 ,..a 0 N ) c 1 (s,a 1 ) Inverse Reinforcement .. (s 1 ,a ,a 1 1 ,..a 1 N ) Learning (MAIRL) c N (s,a N ) … 46
MAGAIL D 1 tries D 2 tries D 2 tries D1 tries D N tries D N tries to to to to to to output 0 output 1 output 0 output 1 output 0 output 1 Diff. Diff. Diff. Diff. Diff. Diff. … … function function function function function function D 1 D 2 D1 D 2 D N D N Sample from model Sample from expert (s,a 1 ,a 2 ,…, a N ) (s,a 1 ,a 2 ,…, a N ) Black box simulator Generator G Policy Policy Agent N Agent 1 Song, Ren, Sadigh, Ermon, Multi-Agent Generative Adversarial Imitation Learning
Environments Demonstrations MAGAIL
Environments Demonstrations MAGAIL
Suboptimal demos MAGAIL Expert lighter plank + bumps on ground
Conclusions • IRL is a dual of an occupancy measure matching problem (generative modeling) • Might need flexible cost functions – GAN style approach • Policy gradient approach – Scales to high dimensional settings • Towards unsupervised learning of latent structure from demonstrations 51
Recommend






















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.