Deep Learning: multi-layer neural networks Recurrent Neural - PowerPoint PPT Presentation
Deep Learning: multi-layer neural networks Recurrent Neural Networks: sequence data Long Short-Term Memory: LSTM
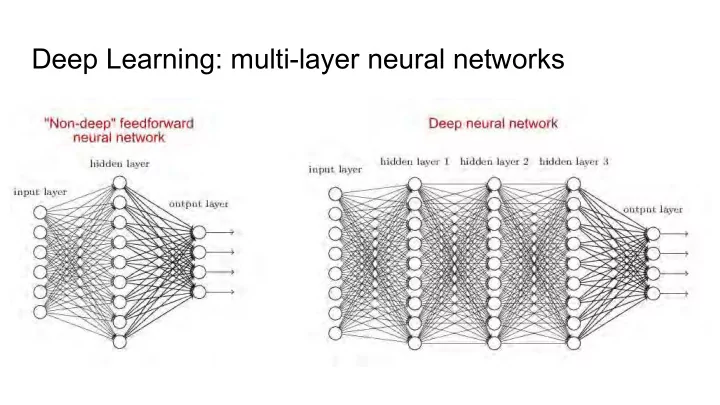
Deep Learning: multi-layer neural networks
Recurrent Neural Networks: sequence data
Long Short-Term Memory: LSTM
• • • • • • • • • • • • • •
• • • • • • • • • • • • • • •
• • • • • • • • • • •
• • • • • • •
1. 2. a. b.
Algorithm AUC S.E. 95% C.I. Outcome mean 0.500 0.025 0.451 0.549 Decision tree 0.561 0.027 0.508 0.613 Decision tree (pruned) 0.573 0.027 0.520 0.626 Xgboost, default settings 0.730 0.013 0.704 0.757 Lasso 0.749 0.014 0.722 0.775 Random forest 0.756 0.013 0.731 0.781 Xgboost (depth = 6, shrinkage = 0.2) 0.762 0.013 0.735 0.788 Xgboost (depth = 3, shrinkage = 0.2) 0.763 0.014 0.736 0.790 Discrete SuperLearner 0.766 0.014 0.739 0.793 Xgboost (depth = 6, shrinkage = 0.1) 0.766 0.013 0.740 0.792 Xgboost (depth = 3, shrinkage = 0.05) 0.768 0.013 0.742 0.794 Xgboost (depth = 3, shrinkage = 0.1) 0.769 0.013 0.744 0.794 Xgboost (depth = 6, shrinkage = 0.05) 0.770 0.013 0.745 0.795 SuperLearner 0.775 0.013 0.750 0.800 Bayesian additive regression tree 0.775 0.013 0.750 0.800
Rank Algorithm Mean SD Min Max 1 Bayesian additive regression trees 0.355 0.146 0.181 0.595 2 Xgboost (default settings) 0.221 0.033 0.177 0.278 3 Xgboost (depth = 3, shrinkage = 0.2) 0.120 0.105 0.000 0.293 4 Lasso 0.086 0.047 0.000 0.167 5 Xgboost (depth = 6, shrinkage = 0.1) 0.067 0.088 0.000 0.245 6 Random forest 0.049 0.046 0.000 0.112 7 Xgboost (depth = 3, shrinkage = 0.1) 0.041 0.057 0.000 0.149 8 Xgboost (depth = 3, shrinkage = 0.05) 0.032 0.082 0.000 0.262 9 Xgboost (depth = 6, shrinkage = 0.2) 0.012 0.036 0.000 0.116 10 Xgboost (depth = 6, shrinkage = 0.05) 0.006 0.019 0.000 0.060 11 Decision tree (pruned) 0.006 0.013 0.000 0.032 12 Decision Tree 0.005 0.015 0.000 0.048 13 Outcome mean 0.000 0.000 0.000 0.000
Algorithm AUC S.E. 95% C.I. Outcome mean 0.500 0.03 0.45 0.55 Decision tree 0.545 0.02 0.50 0.59 Decision tree (pruned) 0.663 0.02 0.63 0.70 Random forest 0.748 0.01 0.72 0.77 Lasso 0.794 0.01 0.77 0.81 Xgboost, default hyperparameters 0.836 0.01 0.82 0.86 Xgboost, learning rate = 0.2 0.840 0.01 0.82 0.86 Xgboost, learning rate = 0.1 0.847 0.01 0.83 0.87 Xgboost, learning rate = 0.05 0.849 0.01 0.83 0.87 Bayesian additive regression tree 0.851 0.01 0.83 0.87 SuperLearner 0.855 0.01 0.84 0.87
Rank Algorithm Mean SD Min Max 1 Bayesian additive regression trees 0.42 0.06 0.35 0.54 2 Xgboost, learning rate = 0.05 0.23 0.15 0.00 0.46 3 Xgboost, default hyperparameters 0.16 0.05 0.10 0.23 4 Xgboost, learning rate = 0.1 0.11 0.09 0.00 0.27 5 Xgboost, learning rate = 0.2 0.06 0.09 0.00 0.23 6 Decision tree 0.01 0.01 0.00 0.04 7 Decision tree (pruned) 0.00 0.01 0.00 0.02 8 Random forest 0.00 0.01 0.00 0.03 9 Outcome mean 0.00 0.00 0.00 0.00 10 Lasso 0.00 0.00 0.00 0.00
Results (Area Under Curve) Deploy ● Standard features + classical models: 0.78 ○ Best model: bartMachine ● Word embeddings + classical models: 0.85! ○ Best model: XGBoost ○ No benefit from standard features + embeddings ● Deep learning: only 0.71 so far ○ Pre-trained embeddings not yet attempted
Deploy Random Forest variable importance
Future work Deploy ● Apply model to websites to track hate speech over time ● Crowdsourced coding - virtually code 25,000+ comments ● Optimized, sequential coding protocol ● Wider variety of source websites ● Machine Learning ○ Optimize deep learning methods ■ Pre-trained word embeddings ■ 1-dimensional convolutional neural nets (CNNs) ○ Feature selection ○ EDA on word embedding dimensions ○ Create our own domain-specific word embeddings ○ Online learning - dynamically update models over time ○ Investigation & interpretation of modeling algorithms
Questions, Comments, Feedback, Collaborations? Chris Kennedy ck37@berkeley.edu http://dlab.berkeley.edu
Recommend
























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.