
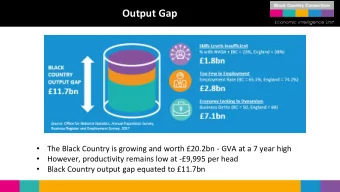
CS480/680 Lecture 19: July 10, 2019 Attention and Transformer - PowerPoint PPT Presentation
CS480/680 Lecture 19: July 10, 2019 Attention and Transformer Networks [Vaswani et al., Attention is All You Need, NeurIPS , 2017] University of Waterloo CS480/680 Spring 2019 Pascal Poupart 1 Attention Attention in Computer Vision
CS480/680 Lecture 19: July 10, 2019 Attention and Transformer Networks [Vaswani et al., Attention is All You Need, NeurIPS , 2017] University of Waterloo CS480/680 Spring 2019 Pascal Poupart 1
Attention • Attention in Computer Vision – 2014: Attention used to highlight important parts of an image that contribute to a desired output • Attention in NLP – 2015: Aligned machine translation – 2017: Language modeling with Transformer networks University of Waterloo CS480/680 Spring 2019 Pascal Poupart 2
Sequence Modeling Challenges with RNNs Transformer Networks • Long range dependencies • Facilitate long range dependencies • Gradient vanishing and • No gradient vanishing and explosion explosion • Large # of training steps • Fewer training steps • Recurrence prevents • No recurrence that facilitate parallel computation parallel computation University of Waterloo CS480/680 Spring 2019 Pascal Poupart 3
Attention Mechanism • Mimics the retrieval of a value ! " for a query # based on a key $ " in database • Picture %&&'(&)*( #, ,, - = ∑ " 0)1)2%3)&4 #, $ " ×! " University of Waterloo CS480/680 Spring 2019 Pascal Poupart 4
Attention Mechanism • Neural architecture • Example: machine translation – Query: ! "#$ (hidden vector for % − 1 () output word) – Key: ℎ + (hidden vector for , () input word) – Value: ℎ + (hidden vector for , () input word) University of Waterloo CS480/680 Spring 2019 Pascal Poupart 5
Transformer Network • Vaswani et al., (2017) Attention is all you need. • Encoder-decoder based on attention (no recurrence) University of Waterloo CS480/680 Spring 2019 Pascal Poupart 6
Multihead attention • Multihead attention: compute multiple attentions per query with different weights !"#$%ℎ'() *, ,, - = / 0 1231($ ℎ'() 4 , ℎ'() 5 , … , ℎ'() 7 9 *, / ; - : ,, / ℎ'() 8 = ($$'3$%23 / 8 8 8 9 ? : ($$'3$%23 *, ,, - = <2=$!(> @ A - University of Waterloo CS480/680 Spring 2019 Pascal Poupart 7
Masked Multi-head attention • Masked multi-head attention: multi-head where some values are masked (i.e., probabilities of masked values are nullified to prevent them from being selected). • When decoding, an output value should only depend on previous outputs (not future outputs). Hence we mask future outputs. 0 1 2 !""#$"%&$ ', ), * = ,&-".!/ 3 4 * 0 1 289 .!,5#67""#$"%&$ ', ), * = ,&-".!/ * 3 4 where : is a mask matrix of 0’s and −∞ ’s University of Waterloo CS480/680 Spring 2019 Pascal Poupart 8
Other layers • Layer normalization: – Normalize values in each layer to have 0 mean and 1 variance – For each hidden unit ℎ " compute ℎ " ← $ % (ℎ " − () where * is a variable, ( = , , - - - ∑ "/, - ∑ "/, ℎ " − ( 1 ℎ " and 0 = – This reduces “covariate shift” (i.e., gradient dependencies between each layer) and therefore fewer training iterations are needed • Positional embedding – Embedding to distinguish each position 23 456"7"58,1" = sin(=>?@A@>B/10000 1"/F ) 23 456"7"58,1"G, = cos(=>?@A@>B/10000 1"/F ) University of Waterloo CS480/680 Spring 2019 Pascal Poupart 9
Comparison • Attention reduces sequential operations and maximum path length, which facilitates long range dependencies University of Waterloo CS480/680 Spring 2019 Pascal Poupart 10
Results University of Waterloo CS480/680 Spring 2019 Pascal Poupart 11
GPT and GPT-2 • Radford et al., (2018) Language models are unsupervised multitask learners – Decoder transformer that predicts next word based on previous words by computing !(# $ |# &..$(& ) – SOTA in “zero-shot” setting for 7/8 language tasks (where zero-shot means no task training, only unsupervised language modeling) University of Waterloo CS480/680 Spring 2019 Pascal Poupart 12
BERT (Bidirectional Encoder Representations from Transformers) • Devlin et al., (2019) BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding – Decoder transformer that predicts a missing word based on surrounding words by computing !(# $ |# &..$(&,$*&..+ ) – Mask missing word with masked multi-head attention – Improved state of the art on 11 tasks University of Waterloo CS480/680 Spring 2019 Pascal Poupart 13
Recommend

![CS480/680 Lecture 18: July 8, 2019 Recurrent and Recursive Neural Networks [GBC] Chap. 10](https://c.sambuz.com/717990/cs480-680-lecture-18-july-8-2019-s.webp)
![CS480/680 Lecture 24: July 29, 2019 Gradient Boosting, Bagging, Decision Forest [RN] Sec. 18.10,](https://c.sambuz.com/864322/cs480-680-lecture-24-july-29-2019-s.webp)
![CS480/680 Lecture 22: July 22, 2019 Ensemble Learning [RN] Sec. 18.10, [M] Sec. 16.2.5, [B]](https://c.sambuz.com/894062/cs480-680-lecture-22-july-22-2019-s.webp)
![CS480/680 Lecture 9: June 5, 2019 Perceptrons, Neural Networks [D] Chapt. 4, [HTF] Chapt. 11,](https://c.sambuz.com/690997/cs480-680-lecture-9-june-5-2019-s.webp)
![CS480/680 Lecture 4: May 15, 2019 Statistical Learning [RN]: Sec 20.1, 20.2, [M]: Sec. 2.2, 3.2](https://c.sambuz.com/753766/cs480-680-lecture-4-may-15-2019-s.webp)
![CS480/680 Lecture 15: June 26, 2019 Deep Neural Networks [GBC] Chap. 6, 7, 8 University of](https://c.sambuz.com/791678/cs480-680-lecture-15-june-26-2019-s.webp)

![CS480/680 Lecture 2: May 8 th , 2019 Nearest Neighbour [RN] Sec. 18.8.1, [HTF] Sec. 2.3.2, [D]](https://c.sambuz.com/926633/cs480-680-lecture-2-may-8-th-2019-s.webp)
![CS480/680 Lecture 12: June 17, 2019 Gaussian Processes [B] Section 6.4 [M] Chap. 15 [HTF] Sec.](https://c.sambuz.com/961504/cs480-680-lecture-12-june-17-2019-s.webp)

![CS480/680 Machine Learning Lecture 3: May 13, 2019 Linear Regression [RN] Sec. 18.6.1, [HTF]](https://c.sambuz.com/988148/cs480-680-machine-learning-lecture-3-may-13-2019-s.webp)
![CS480/680 Lecture 7: May 29, 2019 Classification with Mixture of Gaussians [B] Sections 4.2,](https://c.sambuz.com/997749/cs480-680-lecture-7-may-29-2019-s.webp)
![CS480/680 Lecture 11: June 12, 2019 Kernel methods [D] Chap. 11 [B] Sec. 6.1, 6.2 [M] Sec.](https://c.sambuz.com/1002349/cs480-680-lecture-11-june-12-2019-s.webp)
![CS480/680 Lecture 14: June 24, 2019 Support Vector Machines (continued) [B] Sec. 7.1 [D] Sec.](https://c.sambuz.com/1006611/cs480-680-lecture-14-june-24-2019-s.webp)

![1 [9-4] Mor M. Peretz, Switch-Mode Power Supplies Current feedback loop I o L i o V o v o S V](https://c.sambuz.com/1071065/1-s.webp)





More recommend
Explore More Topics
Stay informed with curated content and fresh updates.