
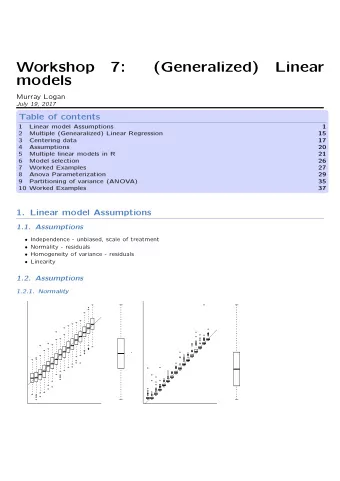
CS480/680 Lecture 8: June 3, 2019 Classification by Logistic - PowerPoint PPT Presentation
CS480/680 Lecture 8: June 3, 2019 Classification by Logistic Regression, Generalized linear models [RN] Sec 18.6.4, [B] Sec. 4.3, [M] Chapt. 8, [HTF] Sec. 4.4 University of Waterloo CS480/680 Spring 2019 Pascal Poupart 1 Beyond Mixtures of
CS480/680 Lecture 8: June 3, 2019 Classification by Logistic Regression, Generalized linear models [RN] Sec 18.6.4, [B] Sec. 4.3, [M] Chapt. 8, [HTF] Sec. 4.4 University of Waterloo CS480/680 Spring 2019 Pascal Poupart 1
Beyond Mixtures of Gaussians • Mixture of Gaussians: – Restrictive assumption: each class is Gaussian – Picture: • Can we consider other distributions than Gaussians? University of Waterloo CS480/680 Spring 2019 Pascal Poupart 2
Exponential Family • More generally, when Pr($|& ' ) are members of the exponential family (e.g., Gaussian, exponential, Bernoulli, categorical, Poisson, Beta, Dirichlet, Gamma, etc.) . / $ − 1 ) ' + 3($)) Pr $ ) ' = exp() ' where ) ' : parameters of class 4 / $ , 1 ) ' , 3 $ : arbitrary fns of the inputs and params • the posterior is a sigmoid logistic linear function in $ Pr & ' $ = 7(8 . $ + 9 : ) University of Waterloo CS480/680 Spring 2019 Pascal Poupart 3
Probabilistic Discriminative Models • Instead of learning Pr($ % ) and Pr('|$ % ) by maximum likelihood and finding Pr $ % ' by Bayesian inference, why not learn Pr $ % ' directly by maximum likelihood? • We know the general form of Pr($ % |') : – Logistic sigmoid (binary classification) – Softmax (general classification) University of Waterloo CS480/680 Spring 2019 Pascal Poupart 4
Logistic Regression • Consider a single data point (", $) : 451 & ∗ = )*+,)- & . & / 0 " 1 1 − . & / 0 " • Similarly, for an entire dataset 6, 7 : 451 ; & ∗ = )*+,)- & 9 " : 1 ; 1 − . & / 0 . & / 0 " : : Objective: negative log likelihood (minimization) < & = − ∑ : $ : ln .(& / 0 " : ) + 1 − $ : ln(1 − . & / 0 " : ) Tip: AB C = .())(1 − . ) ) AC University of Waterloo CS480/680 Spring 2019 Pascal Poupart 5
Logistic Regression • NB: Despite the name, logistic regression is a form of classification. • However, it can be viewed as regression where the goal is to estimate the posterior Pr # $ % , which is a continuous function University of Waterloo CS480/680 Spring 2019 Pascal Poupart 6
Maximum likelihood • Convex loss: set derivative to 0 * % + , /0* % + , - . - . - . , #$ #% = − ∑ ( ) ( 0 = * % + , - . /0* % + , * % + , - . - 2 0, - . − ∑ ( 1 − ) ( /0* % + , - . - ( − ∑ ( ) ( 4 % 5 , ⟹ 0 = − ∑ ( ) ( , - ( , - ( + ∑ ( 4 % 5 , - ( + ∑ ( ) ( 4 % 5 , - ( , - ( , - ( ⟹ 0 = ∑ ( 4 % 5 , - ( − ) ( , - ( • Sigmoid prevents us from isolating % , so we use an iterative method instead University of Waterloo CS480/680 Spring 2019 Pascal Poupart 7
Newton’s method • Iterative reweighted least square: ! ← ! − $ %& '((!) where '( is the gradient (column vector) and + is the Hessian (matrix) -( -( ⋯ - . / 0 -/ 0 -/ 2 + = ⋮ ⋱ ⋮ -( -( ⋯ -/ 2 . -/ 2 -/ 0 University of Waterloo CS480/680 Spring 2019 Pascal Poupart 8
Hessian ! = #(#% & ) , - & . / 1 − - & . / . = ∑ )*+ 0 ) 0 ) / 0 ) / 0 ) = / 34/ 3 . - + (1 − - + ) where 4 = ⋱ - , (1 − - , ) and - + = -(& . / 0 + ) , - , = -(& . / 0 , ) University of Waterloo CS480/680 Spring 2019 Pascal Poupart 9
Case study • Applications: recommender systems, ad placement • Used by all major companies • Advantages: logistic regression is simple, flexible and efficient University of Waterloo CS480/680 Spring 2019 Pascal Poupart 10
App Recommendation • Flexibility: millions of features (binary & numerical) – Examples: • Efficiency: classification by dot products Multiple classes: Two classes: H = I @ ? @ 0 ∗ = F1 A ≥ 0.5 0 ∗ = 345637 8 9:;(= > A) ? @ ∑ >D 9:;(E >D 0 otherwise. A) = I @ 0 ∗ = F1 A ≥ 0 I @ = 345637 8 = 8 A 0 otherwise – Sparsity: – Parallelization: University of Waterloo CS480/680 Spring 2019 Pascal Poupart 11
Numerical Issues • Logistic Regression is subject to overfitting – Without enough data, logistic regression can classify each data point arbitrarily well (i.e., Pr #$%%&#' #()** → 1 ) • Problems: -&./ℎ'* → ±∞ Hessian → singular • Picture University of Waterloo CS480/680 Spring 2019 Pascal Poupart 12
Regularization • Solution: penalize large weights ) $ % & + ( • Objective: min ) * & ) 3 " ) + 1 . " ln 0(& # 2 3 " ) + 1 − . " ln(1 − 0 & # 2 2 *& # & = min ! − - " • Hessian 8 : + *; 7 = 2 892 where < == = 0(& > 2 3 = )(1 − 0(& > 2 3 = ) the term *? ensures that 7 is not singular (eigenvalues ≥ * ) University of Waterloo CS480/680 Spring 2019 Pascal Poupart 13
Generalized Linear Models • How can we do non-linear regression and classification while using the same machinery? • Idea: map inputs to a different space and do linear regression/classification in that space University of Waterloo CS480/680 Spring 2019 Pascal Poupart 14
Example • Suppose the underlying function is quadratic University of Waterloo CS480/680 Spring 2019 Pascal Poupart 15
Basis functions • Use non-linear basis functions: – Let ! " denote a basis function ! # $ = 1 ! ' $ = $ ! ( $ = $ ( – Let the hypothesis space ) be ) = {$ → , # ! # $ + , ' ! ' $ + , ( ! ( ($)|, " ∈ ℜ} • If the basis functions are non-linear in $ , then a non- linear hypothesis can still be found by linear regression University of Waterloo CS480/680 Spring 2019 Pascal Poupart 16
Common basis functions • Polynomial: ! " # = # " % !"#$ • Gaussian: ! " # = % & %&% (&) $ • Sigmoid: ! " # = ' * , where ' + = ,-. "' • Also Fourier basis functions, wavelets, etc. University of Waterloo CS480/680 Spring 2019 Pascal Poupart 17
Generalized Linear Models • Linear regression: + + 7 + ! ∗ = $%&'() ! * / 0 - − ! 2 3 + ∑ -.* 4 5 ! + + • Generalized linear regression: + + 7 + ! ∗ = $%&'() ! * / 0 - − ! 2 8(4 5 ) + ∑ -.* ! + + • Linear separator (classification): + ! ∗ = $%&'() ! − ∑ - ; - ln >(! ? 3 7 4 - ) + 1 − ; - ln(1 − > ! ? 3 4 - ) + ! + + • Generalized linear separator (classification): + ! ∗ = $%&'() ! − ∑ - ; - ln >(! ? 8(4 - )) + 1 − ; - ln(1 − > ! ? 8(4 - ) ) + 7 ! + + University of Waterloo CS480/680 Spring 2019 Pascal Poupart 18
Recommend

![CS480/680 Lecture 9: June 5, 2019 Perceptrons, Neural Networks [D] Chapt. 4, [HTF] Chapt. 11,](https://c.sambuz.com/690997/cs480-680-lecture-9-june-5-2019-s.webp)
![CS480/680 Lecture 15: June 26, 2019 Deep Neural Networks [GBC] Chap. 6, 7, 8 University of](https://c.sambuz.com/791678/cs480-680-lecture-15-june-26-2019-s.webp)
![CS480/680 Lecture 12: June 17, 2019 Gaussian Processes [B] Section 6.4 [M] Chap. 15 [HTF] Sec.](https://c.sambuz.com/961504/cs480-680-lecture-12-june-17-2019-s.webp)
![CS480/680 Lecture 11: June 12, 2019 Kernel methods [D] Chap. 11 [B] Sec. 6.1, 6.2 [M] Sec.](https://c.sambuz.com/1002349/cs480-680-lecture-11-june-12-2019-s.webp)
![CS480/680 Lecture 14: June 24, 2019 Support Vector Machines (continued) [B] Sec. 7.1 [D] Sec.](https://c.sambuz.com/1006611/cs480-680-lecture-14-june-24-2019-s.webp)
![CS480/680 Lecture 18: July 8, 2019 Recurrent and Recursive Neural Networks [GBC] Chap. 10](https://c.sambuz.com/717990/cs480-680-lecture-18-july-8-2019-s.webp)
![CS480/680 Lecture 4: May 15, 2019 Statistical Learning [RN]: Sec 20.1, 20.2, [M]: Sec. 2.2, 3.2](https://c.sambuz.com/753766/cs480-680-lecture-4-may-15-2019-s.webp)

![CS480/680 Lecture 24: July 29, 2019 Gradient Boosting, Bagging, Decision Forest [RN] Sec. 18.10,](https://c.sambuz.com/864322/cs480-680-lecture-24-july-29-2019-s.webp)
![CS480/680 Lecture 22: July 22, 2019 Ensemble Learning [RN] Sec. 18.10, [M] Sec. 16.2.5, [B]](https://c.sambuz.com/894062/cs480-680-lecture-22-july-22-2019-s.webp)
![CS480/680 Lecture 2: May 8 th , 2019 Nearest Neighbour [RN] Sec. 18.8.1, [HTF] Sec. 2.3.2, [D]](https://c.sambuz.com/926633/cs480-680-lecture-2-may-8-th-2019-s.webp)
![CS480/680 Machine Learning Lecture 3: May 13, 2019 Linear Regression [RN] Sec. 18.6.1, [HTF]](https://c.sambuz.com/988148/cs480-680-machine-learning-lecture-3-may-13-2019-s.webp)
![CS480/680 Lecture 7: May 29, 2019 Classification with Mixture of Gaussians [B] Sections 4.2,](https://c.sambuz.com/997749/cs480-680-lecture-7-may-29-2019-s.webp)









More recommend
Explore More Topics
Stay informed with curated content and fresh updates.