CS 4100: Artificial Intelligence Optimization and Neural Nets - PDF document
CS 4100: Artificial Intelligence Optimization and Neural Nets Jan-Willem van de Meent, Northeastern University [These slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley. All CS188 materials are available at
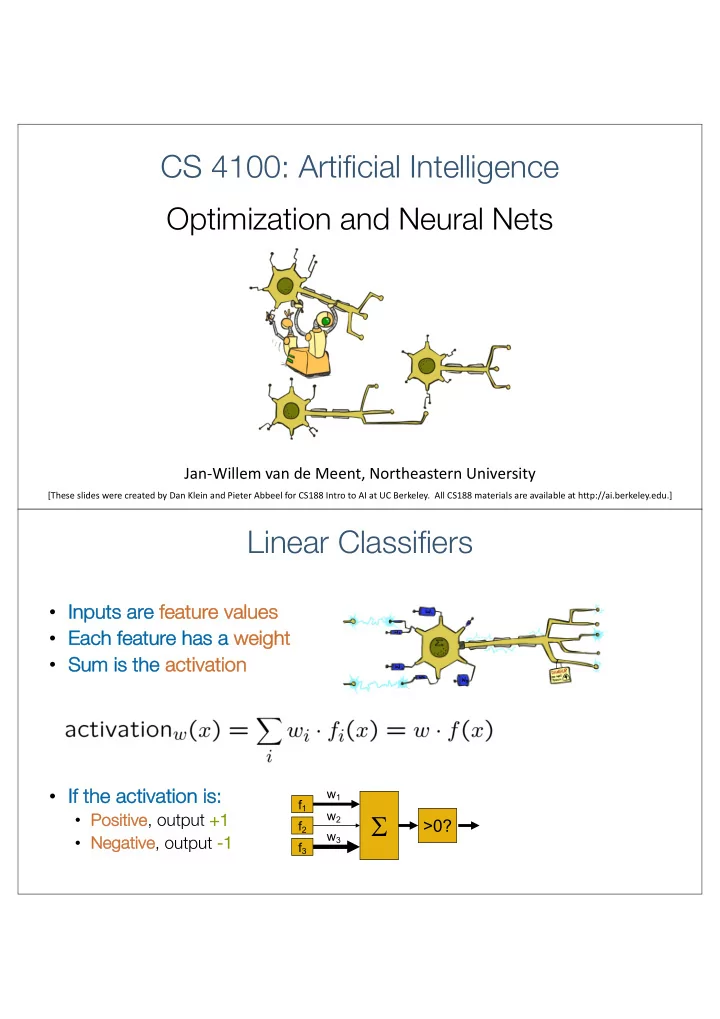
CS 4100: Artificial Intelligence Optimization and Neural Nets Jan-Willem van de Meent, Northeastern University [These slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley. All CS188 materials are available at http://ai.berkeley.edu.] Linear Classifiers • In Inputs s are fe feature values • Ea Each feature has s a we weight • Su Sum is the act activat ation • If If the activa vation is: s: w 1 f 1 S w 2 • Po Positive ve , output +1 +1 >0? f 2 w 3 • Ne Negative , output -1 f 3
How to get probabilistic decisions? • Ac Activ ivation ion: z = w · f ( x ) • If If very po positive à want probability going to 1 z = w · f ( x ) very ne ive à want probability going to 0 • If If negative z = w · f ( x ) • Sigmoid Sigmoid fu function ion 1 φ ( z ) = 1 + e − z Best w? • Maximum like kelihood estimation: X log P ( y ( i ) | x ( i ) ; w ) max ll ( w ) = max w w i 1 P ( y ( i ) = +1 | x ( i ) ; w ) = wi with th: 1 + e − w · f ( x ( i ) ) 1 P ( y ( i ) = − 1 | x ( i ) ; w ) = 1 − 1 + e − w · f ( x ( i ) ) Th This is is is calle lled Lo Logis istic ic Regressio ion
Multiclass Logistic Regression • Re Recall Perceptron: n: • A we weig ight vector for each class: • Sc Score (activation) of a class y: • Prediction with hi highe ghest st sc scor ore wins ns • Ho How w to tur urn n sc scores s in into pr proba babi bilities? ? e z 1 e z 2 e z 3 z 1 , z 2 , z 3 → e z 1 + e z 2 + e z 3 , e z 1 + e z 2 + e z 3 , e z 1 + e z 2 + e z 3 original activations softmax activations Best w? • Maximum like kelihood estimation: X log P ( y ( i ) | x ( i ) ; w ) max ll ( w ) = max w w i e w y ( i ) · f ( x ( i ) ) P ( y ( i ) | x ( i ) ; w ) = with wi th: y e w y · f ( x ( i ) ) P Th This is is is calle lled Mu Multi-Cl Class L ss Logist stic R Regressi ssion
This Lecture • Op Opti timizati tion • i.e., how do we solve: X log P ( y ( i ) | x ( i ) ; w ) max ll ( w ) = max w w i Hill Climbing • Re Recall fro rom CSPs lectu ture re: simple, general idea • St Start wherever Repeat: move to the best neighboring state • Re • If no neighbors better than current, quit • What’s particularly tricky ky when hill-cl climbi bing for for mu mult ltic icla lass logis logistic ic regr gression ion? • Optimization over a co continuous s space ace • Infinitely many neighbors! • How to do this efficiently?
1-D Optimization g ( w ) g ( w 0 ) w w 0 • Co Could ev eval aluate ate an and g ( w 0 + h ) g ( w 0 − h ) • Then step in be best di dire rection on ∂ g ( w 0 ) g ( w 0 + h ) − g ( w 0 − h ) • Or, Or, evaluate te der derivat ative = lim ∂ w 2 h h → 0 • Defines di dire rection on to step into 2-D Optimization Source: offconvex.org
Gradient Ascent • Pe Perfo form update in uphill direction fo for each coordinate • The steeper the slope (i.e. the higher the derivative) the bigger the step for that coordinate • E. E.g., consi sider: g ( w 1 , w 2 ) Up Updates: • • Up Updates in in vector r notatio ion: w 1 ← w 1 + α ∗ @ g ( w 1 , w 2 ) w ← w + α ∗ r w g ( w ) @ w 1 w 2 ← w 2 + α ∗ @ g " # ∂g ( w 1 , w 2 ) ∂w 1 ( w ) = gradient = • with: r w g ( w ) = @ w 2 ∂g ∂w 2 ( w ) Gradient Ascent • Id Idea: • St Start somewhere Repeat: Take a step in the gradient direction • Re Figure source: Mathworks
What is the Steepest Direction? | Δ | ≤ ε 1/2 w max g ( w + ∆) ∆:∆ 2 1 +∆ 2 2 ≤ ε g ( w + ∆) ≈ g ( w ) + ∂ g ∆ 1 + ∂ g • Fi First-Or Orde der Taylor Expa pansion: ∆ 2 ∂ w 1 ∂ w 2 g ( w ) + ∂ g ∆ 1 + ∂ g • St Steepest Asc scent Dire Directio ion: max ∆ 2 ∂ w 1 ∂ w 2 ∆:∆ 2 1 +∆ 2 2 ≤ ε Δ ∆ = ε a ∆: k ∆ k≤ ε ∆ > a max • Re Recall: à a k a k " # ∂g ∆ = ε r g • He Henc nce, solut ution: n: Gr Gradi dient di direction = = steepe pest di direction! ∂w 1 r g = ∂g kr g k ∂w 2 Gradient in n dimensions ∂g ∂w 1 ∂g r g = ∂w 2 · · · ∂g ∂w n
Optimization Procedure: Gradient Ascent w • initialize • for iter = 1 , 2 , … w ← w + α ∗ r g ( w ) le learning ning ra rate te - hyperparameter • α that needs to be chosen carefully How? Try multiple choices • Ho • Cr Crude rule of thumb mb: update changes about 0. 0.1 1 – 1% 1% w Gradient Ascent on the Log Likelihood Objective X log P ( y ( i ) | x ( i ) ; w ) max ll ( w ) = max w w i (Sum over al all training examples) g ( w ) • initialize w • for iter = 1 , 2 , … X r log P ( y ( i ) | x ( i ) ; w ) w ← w + α ∗ i
St Stoch chast astic c Gradient Ascent on the Log Likelihood Objective X log P ( y ( i ) | x ( i ) ; w ) max ll ( w ) = max w w i Obs Observation: once the gradient on one training example has been computed, we might as well incorporate before computing next one • initialize w • for iter = 1 , 2 , … • pick random j w ← w + α ∗ r log P ( y ( j ) | x ( j ) ; w ) Intuition: Use sampling to approximate the gradient. In This is called st stochast stic g gradient d desc scent . Batch Gradient Ascent on the Log Likelihood Objective Mi Mini-Ba X log P ( y ( i ) | x ( i ) ; w ) max ll ( w ) = max w w i Observation: gradient over small set of training examples ( =m Obs =mini-ba batch ) can be computed in parallel, might as well do that instead of a single one • initialize w • for iter = 1 , 2 , … • pick random subset of training examples J X r log P ( y ( j ) | x ( j ) ; w ) w ← w + α ∗ j ∈ J
How about computing all the derivatives? • We’ll talk about that once we covered neural networks, which are a generalization of logistic regression Neural Networks
<latexit sha1_base64="5jPDuadc92/H0mDYLheYrIDBNTY=">AHNnicfZXPb9MwFMe9AWUXxsckVBFhzSkqkrW0Y1JSNPGNG6MiW1ITVU5idumdX5gO107yzf+Gq5w4F/hwg1x5U/ATgIkcZijNZ7n/f1s/ts2xH2KDOMb0vL167fqN1cuVW/fefuvfuraw/OaBgTB506IQ7JextShL0AnTKPYfQ+Igj6Nkbn9vRA+c9niFAvDN6xRYT6PhwF3tBzIJOmwerjy4HXeNmwaOwPJo3zAfdaE9GwdhvDwWRj/myw2jTaRtIaesfMOs09kLbjwVoNWG7oxD4KmIMhpT3TiFifQ8I8ByNRt2KIuhM4Qj1ZDeAPqJ9nkxENOr1pzk/D9BFNGdozkSF3YdsLOp5PQ59mlpLxmEYMFq0Yih16cIvWm2/qNhD8ygkKn13ElNmh3OhUnTRUC53kjN3bRwjwU+O9gU3Wt1Oy9zcFmWGIDdDzB2jJR+NGBGEgozZ2WqZ3Z0KIpJhNE/ylCcyjhPvYJkepyBjr+YyrTa3W5L/lctI3k7HaFH7CezSHkzw67iT9SM/sgbiXoa9rwCPljAoCiuXvM/9FG6FLncjSvV3xAYjFA+m9yEVfJygQiSNeOEvg8Dl1sz5Iie2ecWCmhMkKoZbtkhdmVByA9vmkILSgNkbGJX4rmvWgGseBWSwYNMXJUqfB1CyPoUhauC2u3HDAXxeFnfJ4MmcWGrPQmEuNudSYscZYiMGKOcZFMC4LfSgJsXGiU5bBJQzL8it4FhZDmojDktINPa0tYdk5EO1nmGECGQhUYfKhcfG2PM9RnmF3qUF1wdJf3lwQ5LCalf2+aHQiMdGyclI3vFbZaUTxElroaqHVZBjohGphumgo10NjsZKmBnocHJvq1AQ10324QKTu6MF6p1/94Qeuds212ltvt5p7+9ntsQIegSdgA5hgG+yB1+AYnAIHfASfwGfwpfa19r32o/YzRZeXspiHoNBqv34DRKiTHQ=</latexit> Multi-class Logistic Regression • Lo Logis istic ic regressio ion n is is a specia ial l case of of a a ne neur ural l ne network f 1 (x) W 1, 1,1 e z 1 W 1, W 1, z 1 1,2 s P ( y 1 | x ; w ) = 1,3 e z 1 + e z 2 + e z 3 o f 2 (x) f e z 2 t z 2 P ( y 2 | x ; w ) = e z 1 + e z 2 + e z 3 f 3 (x) m a e z 3 x … z 3 P ( y 3 | x ; w ) = e z 1 + e z 2 + e z 3 W 3,3 ,3 f K (x) X z i = W i,j f j ( x ) j Deep Neural Network = Also learn the features! Can we automatically learn good features f j (x (x) ? f 1 (x) e z 1 z 1 s P ( y 1 | x ; w ) = e z 1 + e z 2 + e z 3 o f 2 (x) f e z 2 t z 2 P ( y 2 | x ; w ) = e z 1 + e z 2 + e z 3 f 3 (x) m a e z 3 x … z 3 P ( y 3 | x ; w ) = e z 1 + e z 2 + e z 3 f K (x)
Deep Neural Network = Also learn the features! z (1) x 1 z (2) z ( n − 1) f 1 (x) 1 1 1 z ( OUT ) s P ( y 1 | x ; w ) = 1 z (1) z (2) x 2 o f 2 (x) z ( n − 1) 2 2 2 f … t z ( OUT ) P ( y 2 | x ; w ) = x 3 z (2) z (1) z ( n − 1) f 3 (x) 2 m 3 3 3 a x … … … … … z ( OUT ) P ( y 3 | x ; w ) = 3 z (1) z (2) x L f K (x) z ( n − 1) K (1) K (2) K ( n − 1) z ( k ) W ( k − 1 ,k ) z ( k − 1) X g = nonlinear activation function = g ( ) i i,j j j Deep Neural Network = Also learn the features! z (1) z ( n ) x 1 z (2) z ( n − 1) 1 1 1 1 z ( OUT ) s P ( y 1 | x ; w ) = 1 z ( n ) z (1) z (2) x 2 o z ( n − 1) 2 2 2 2 f … t z ( OUT ) P ( y 2 | x ; w ) = z ( n ) z (2) x 3 z (1) z ( n − 1) 2 m 3 3 3 3 a x … … … … … P ( y 3 | x ; w ) = z ( OUT ) 3 z (1) z (2) z ( n ) x L z ( n − 1) K (1) K (2) K ( n ) K ( n − 1) z ( k ) W ( k − 1 ,k ) z ( k − 1) X = g ( ) g = nonlinear activation function i i,j j j
Common Activation Functions [source: MIT 6.S191 introtodeeplearning.com] Deep Neural Network: Also Learn the Features! • Tr Train inin ing g a a deep neural network k is just like ke logistic regression: X log P ( y ( i ) | x ( i ) ; w ) max ll ( w ) = max w w i just w tends to be a much, much larger vector J à ju just run gradie ient ascent + st stop when log likelihood of hold-out data starts to decrease
Recommend
























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.