
Chrome Dino DQN AU T H T H O R : G E O RG E M A RG A R I T I S - PowerPoint PPT Presentation
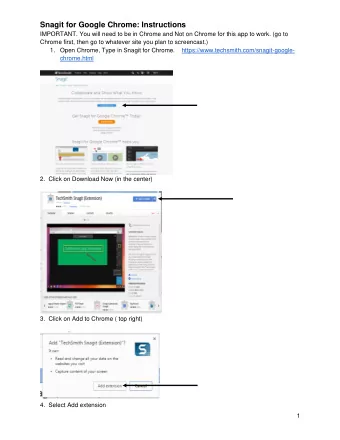
Chrome Dino DQN AU T H T H O R : G E O RG E M A RG A R I T I S I N S N ST RU C T U C TO R : P RO F. M L AG O U DA K I S C O U R U R S E S E : C O M P 513 , AUTO N O M O US AG E N T S S C H O O L : E C E , T E C HN I C A L UN I
Chrome Dino DQN AU T H T H O R : G E O RG E M A RG A R I T I S I N S N ST RU C T U C TO R : P RO F. M L AG O U DA K I S C O U R U R S E S E : C O M P 513 , AUTO N O M O US AG E N T S S C H O O L : E C E , T E C HN I C A L UN I VE R S I T Y O F C R E T E P E R I E R I O D O D: FA L L S E M E ST E R , 2 019 - 2 0 2 0
Overview What is Chrome Dino? Model Deep Q Learning Implementation Results Conclusions Pros – Cons Future Work References
What is Chrome Dino? 2D Arcade Game created by Google for Chrome Designed as an “Easter Egg” game for when there is no internet in Chrome Player: A little Dino Task: The player controls a dino and can either jump or duck at any specific time. The goal is to avoid as many obstacles as you can in order to maximize your score. As time progresses, the game becomes more difficult as the environment moves faster and more obstacles appear.
What is Chrome Dino?
Model State space -> Very Large: Each state -> Represented by 4 frames of 84x84 binary images Actions: Do nothing Jump Duck Rewards: +0.1 in every frame the Dino is alive -1 when the Dino dies
Deep Q Learning
Implementation The game is run on a browser simulator (Selenium) Python uses a chrome webriver to communicate with selenium and play the game Our DQN model is implemented in Tensorflow 2.0 The agent interacts with the environment and the environment returns (s,a,r,s’) where: s: current state (4x84x84 matrix) a: action (0 for do nothing, 1 for jump, 2 for duck) r: numeric reward s’: new state
Implementation For better results and smoother training, our agent uses: Experience replay: • Transitions are used in batches of past experiences for training • Same transition used multiple times to improve learning Target Network: • Use se o of 2 2 ne networks: Target network to estimate target Q value and Policy network to get Q values • Increases training stability
Results In our results we tested 2 different models: Model 1: without duck action (learning rate = 10 −3 ) Model 2: with duck action (learning rate = 10 −4 ) For those models, we measured every 20 episodes (games): The ma maximum mum score of the last 20 episodes The average score of the last 20 episodes The mi mini nimum mum score of the last 20 episodes Then we smoothed the curves in order to better observe the trend
Results (max score) 350 300 Model 1 (No duck) 250 Model 2 (Duck) 200 150 100 50 0 0 1k 2k 3k 4k 5k 6k 7k 8k 9k 10k 11k Episodes
Results (avg score) 140 120 Model 1 (No duck) 100 Model 2 (Duck) 80 60 40 20 0 0 1k 2k 3k 4k 5k 6k 7k 8k 9k 10k 11k Episodes
Results (min score) 47 46 Model 1 (No duck) 45 Model 2 (Duck) 44 43 42 41 0 1k 2k 3k 4k 5k 6k 7k 8k 9k 10k 11k Episodes
Conclusions By reducing the learning rate and allowing duck action we can observe: Slower convergence BUT UT Better and more consistent results Observation on: Using duck action, our agent discovers a hidden strategy: Jump While in the air, hit duck to descend: Minimizes air-time Returns to ground where the agent has more control -> Avoids more obstacles
Pros - Cons Advan antag tages: Can be used without any domain specific knowledge or assumptions about the environment The exact same model can be used to beat many different games when trained in a different environment Disad advan antag ages: Slow learning ability: A lot of time taken for training (1 or 2 days) • Scores between near episodes not very consistent: • Increased score variation in near episodes
Future Work Try to improve DQN using: Better hyperparameter tuning Double DQN Prioritized Experience Replay Dueling DQN Try different approaches: Use statistics (dino height, distance to next obstacle e.t.c) instead of images -> Already implemented in code (enabled using flag ---use-statistics) Use NEAT (Neuro Evolution of Augmented Topologies) instead of DQN in conjunction with statistics -> Will yield better results
Code The source code is available on GitHub with documentation: https://github.com/margaeor/dino-dqn
References Atari DQN - Paper Intro to Deep RL – Article Intro to DQN - Article DQN Hands On - Article DQN by sentdex - Video courses – lectures
Recommend






















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.