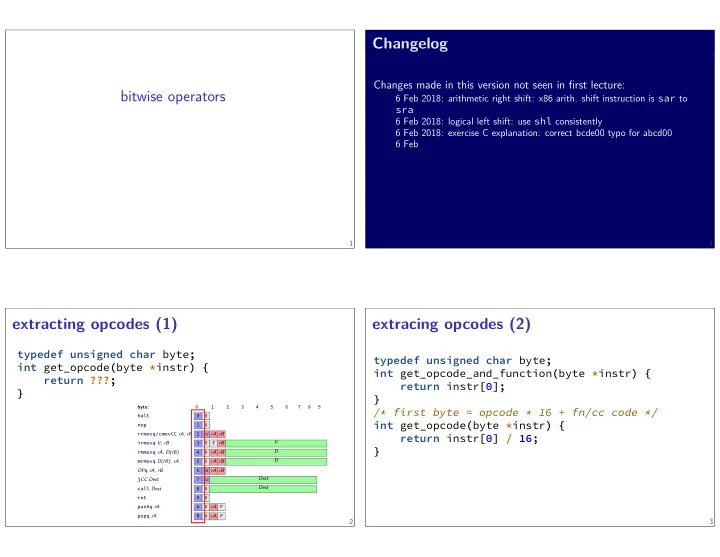
bitwise operators 9 B popq rA 0 rA F A pushq rA 0 ret V 0 8 - PowerPoint PPT Presentation
bitwise operators 9 B popq rA 0 rA F A pushq rA 0 ret V 0 8 call Dest 7 cc j CC Dest fn rA rB 6 0 rA F D 0 rA rB typedef unsigned char byte ; } return instr [0] / 16; int get_opcode ( byte * instr ) { /* first byte = opcode * 16 + fn/cc
bitwise operators 9 B popq rA 0 rA F A pushq rA 0 ret V 0 8 call Dest 7 cc j CC Dest fn rA rB 6 0 rA F D 0 rA rB typedef unsigned char byte ; } return instr [0] / 16; int get_opcode ( byte * instr ) { /* first byte = opcode * 16 + fn/cc code */ } return instr [0]; int get_opcode_and_function ( byte * instr ) { extracing opcodes (2) D 2 } return ???; int get_opcode ( byte * instr ) { typedef unsigned char byte ; Dest Dest OP q rA, rB 5 1 extracting opcodes (1) 4 3 2 1 0 byte: 1 6 6 Feb 6 Feb 2018: exercise C explanation: correct bcde00 typo for abcd00 6 Feb 2018: logical left shift: use shl consistently sra 6 Feb 2018: arithmetic right shift: x86 arith. shift instruction is sar to Changes made in this version not seen in fjrst lecture: Changelog 5 7 mrmovq D(rB), rA 2 cc rA rB 0 rA rB 4 rmmovq rA, D(rB) F rB 0 3 irmovq V, rB rrmovq / cmovCC rA, rB 8 0 1 nop 0 0 halt 9 3
aside: division 1 1 1 binary value — actually voltage value propagates to rest of wire (small delay) 5 circuits: wires 0 0 1 1 0 0 1 1 1 1 binary value — actually voltage value propagates to rest of wire (small delay) 1 0 division is really slow 0 Intel “Skylake” microarchitecture: …and much worse for eight-byte division but this case: it’s just extracting ‘top wires’ — simpler? 4 aside: division division is really slow Intel “Skylake” microarchitecture: 5 …and much worse for eight-byte division but this case: it’s just extracting ‘top wires’ — simpler? 4 circuits: wires 0 0 1 1 about six cycles per division about six cycles per division versus: four additions per cycle versus: four additions per cycle
circuits: wires same as 6 26 26 same as 26 26 11010 = 26 0 1 1 1 1 0 0 circuits: wire bundles 0 1 11010 = 26 26 26 same as 26 26 same as 1 1 1 1 1 0 0 1 1 0 0 1 0 circuits: wire bundles 5 value propagates to rest of wire (small delay) binary value — actually voltage 1 1 1 1 0 0 1 1 0 0 1 0 26 circuits: wire bundles 6 26 26 same as 26 same as 0 11010 = 26 1 1 1 1 0 6
extracting opcode in hardware 0 %reg (fjnal value) %reg (initial value) shr $ amount , %reg (or variable: shr %cl, %reg ) x86 instruction: shr — shift right exposing wire selection 8 0 0 0 0 0 0 0 0 ? ? ? ? 1 1 1 1 1 1 0 0 0 … 1 0 0 0 0 0 0 0 0 ? ? ? ? 1 1 0 1 1 1 0 0 … … … … 0 0 0 … 8 0 1 1 1 0 0 … … … … 0 0 … 0 0 0 %reg (fjnal value) %reg (initial value) shr $ amount , %reg (or variable: shr %cl, %reg ) x86 instruction: shr — shift right exposing wire selection 7 7 0111 0010 = 0x72 (fjrst byte of jl) 1 1 1 shr $ amount , %reg (or variable: shr %cl, %reg ) … 0 0 0 0 0 0 %reg (fjnal value) %reg (initial value) x86 instruction: shr — shift right exposing wire selection 8 0 0 0 0 0 0 0 0 ? ? ? ? 0 1 1 1 0 0 1 0 0 0 1 0 0 0 1 0 0 0 1 0
shift right int get_opcode1 ( byte * instr ) { return instr [0] >> 4; } shrl $4, %eax ret typedef unsigned char byte ; int get_opcode ( byte * instr ) { return instr [0] >> 4; } 10 right shift in C typedef unsigned char byte ; int get_opcode2 ( byte * instr ) { return instr [0] / 16; } // intel syntax: movzx eax, byte ptr [rdi] example output from optimizing compiler: get_opcode1: movzbl (%rdi), %eax shrl $4, %eax ret get_opcode2: movb (%rdi), %al shrb $4, %al movzbl %al, %eax ret movzbl (%rdi), %eax 11 x86 instruction: shr — shift right get_opcode: // %rdi -- instruction address shr $ amount , %reg (or variable: shr %cl, %reg ) get_opcode: // intel syntax: movzx eax, byte ptr [rdi] movzbl (%rdi), %eax shrl $4, %eax ret 9 shift right x86 instruction: shr — shift right shr $ amount , %reg (or variable: shr %cl, %reg ) get_opcode: // intel syntax: movzx eax, byte ptr [rdi] movzbl (%rdi), %eax shrl $4, %eax ret 9 right shift in C // eax ← byte at memory[rdi] with zero padding // eax ← byte at memory[rdi] with zero padding // eax ← one byte of memory[rdi] with zero padding
right shift in C 1 %reg (fjnal value) %reg (initial value) sar $ amount , %reg (or variable: sar %cl, %reg ) x86 instruction: sar — arithmetic shift right arithmetic right shift 13 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 1 1 0 1 0 0 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 1 1 1 0 0 … … … … 0 … typedef unsigned char byte ; movzbl %al, %eax 1 >> 2 == 0 0000 0000 1 >> 1 == 0 0000 0001 1 >> 0 == 1 right shift in math 11 ret shrb $4, %al 10 >> 0 == 10 movb (%rdi), %al get_opcode2: ret shrl $4, %eax movzbl (%rdi), %eax get_opcode1: example output from optimizing compiler: int get_opcode2 ( byte * instr ) { return instr [0] / 16; } int get_opcode1 ( byte * instr ) { return instr [0] >> 4; } 0000 0000 0000 1010 … %reg (initial value) … … 1 1 0 0 %reg (fjnal value) sar $ amount , %reg (or variable: sar %cl, %reg ) x86 instruction: sar — arithmetic shift right arithmetic right shift 12 0000 0010 10 >> 2 == 2 0000 0101 10 >> 1 == 5 13 � x × 2 − y � x >> y = 1 0 1 1 1 0 1 1
dividing negative by two movl %edi, %eax } shift_signed: movl %edi, %eax sarl $5, %eax ret shift_unsigned: shrl $5, eax unsigned shift_unsigned (unsigned x ) { ret 15 standards and shifts in C signed right shift is implementation-defjned standard lets compilers choose which type of shift to do all x86 compilers I know of — arithmetic x86 assembly: only uses lower bits of shift amount return x >> 5; } 16 dividing negative by two int shift_signed (int x ) { right shift in C 14 (except for rounding) same as right shift by one, adding 1 s instead of 0 s same as right shift by one, adding 1 s instead of 0 s (except for rounding) 14 return x >> 5; start with − x start with − x fmip all bits and add one to get x fmip all bits and add one to get x right shift by one to get x/ 2 right shift by one to get x/ 2 fmip all bits and add one to get − x/ 2 fmip all bits and add one to get − x/ 2 shift amount ≥ width of type: undefjned
constructing instructions in hardware 0 0 0 %reg (fjnal value) %reg (initial value) shl $ amount , %reg (or variable: shl %cl, %reg ) x86 instruction: shl — shift left shift left 18 0 1 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 … 0 0 1 1 0 0 … … … 1 0 icode 0 0 0 0 0 1 1 0 0 0 opcode >> (-4) shr $-4, %reg shift left 17 opcode 0 0 0 0 0 0 0 shift left opcode >> (-4) shr $-4, %reg 19 18 0 0 0 ✭✭✭✭✭✭✭✭✭✭✭✭ ❤❤❤❤❤❤❤❤❤❤❤❤ instead: shl $4, %reg (“ sh ift l eft”) ❤❤❤❤❤❤❤❤❤❤❤❤ ✭ ✭✭✭✭✭✭✭✭✭✭✭✭ ❤ instead: opcode << 4 1 0 1 1 0 ❤❤❤❤❤❤❤❤❤❤❤❤ ✭✭✭✭✭✭✭✭✭✭✭✭ instead: shl $4, %reg (“ sh ift l eft”) ❤❤❤❤❤❤❤❤❤❤❤❤ ✭ ✭✭✭✭✭✭✭✭✭✭✭✭ ❤ instead: opcode << 4 1 0 1 1 0 1 0 1 1 0
shift left 1 << 2 == 4 0010 1000 10 << 2 == 40 0001 0100 10 << 1 == 20 0000 1010 10 << 0 == 10 0000 0100 0000 0010 extracting icode from more 1 << 1 == 2 0000 0001 1 << 0 == 1 left shift in math 20 << 0010 1000 20 1 x86 instruction: shl — shift left rA } return ( value % 256) / 16; unsigned extract_opcode2 (unsigned value ) { } return ( value / 16) % 16; unsigned extract_opcode1 (unsigned value ) { // % -- remainder rB 1 ifun icode 0 0 0 1 1 1 10 << 2 == 40 0001 0100 10 << 1 == 20 … 0 1 1 0 0 … … … 0000 1010 1 1 0 0 0 %reg (fjnal value) %reg (initial value) shl $ amount , %reg (or variable: shl %cl, %reg ) 0 0 0 left shift in math 10 << 0 == 10 0000 0100 1 << 2 == 4 0000 0010 1 << 1 == 2 0000 0001 1 << 0 == 1 19 0 0 0 0 0 0 0 0 21 1 0 1 1 0 0 0 1 0 0 0 0 0 x << y = x × 2 y
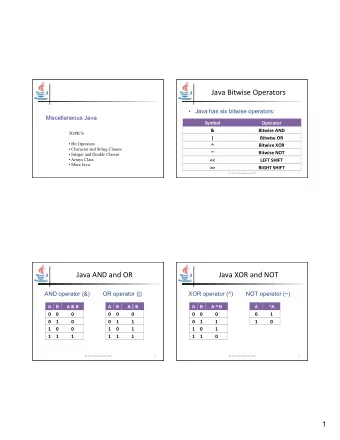
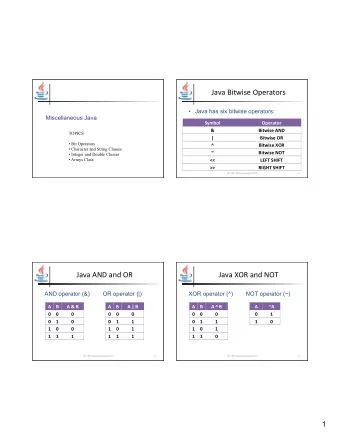
extracting icode from more interlude: a truth table 1 1 0 1 1 0 1 1 0 23 AND 0 0 1 0 0 0 1 0 1 AND with 1: keep a bit the same AND with 0: clear a bit method: construct “mask” of what to keep/remove 0 0 1 rA 1 1 1 1 0 0 0 icode ifun rB // % -- remainder circuits: gates unsigned extract_opcode1 (unsigned value ) { return ( value / 16) % 16; } unsigned extract_opcode2 (unsigned value ) { return ( value % 256) / 16; } 21 manipulating bits? easy to manipulate individual bits in HW how do we expose that to software? 22 24 0 0 1 0 0 0 0 0
interlude: a truth table 1 0 0 1 0 … & 0 0 0 0 … 10 & 7 == 2 2 & 4 == 0 0 & 0 == 0 1 & 0 == 0 1 & 1 == 1 … 0 bitwise AND — & 1 0 1 0 0 … 1 1 0 0 … & 0 1 0 1 … 0 Treat value as array of bits 24 AND AND with 0: clear a bit 0 1 0 AND interlude: a truth table 24 method: construct “mask” of what to keep/remove AND with 1: keep a bit the same 0 1 0 1 0 0 0 1 0 0 1 method: construct “mask” of what to keep/remove 0 AND with 0: clear a bit AND with 1: keep a bit the same 1 0 1 0 0 1 0 0 AND interlude: a truth table 24 method: construct “mask” of what to keep/remove AND with 0: clear a bit AND with 1: keep a bit the same 1 25
Recommend






















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.