
Basics of Numerical Optimization: Iterative Methods Ju Sun - PowerPoint PPT Presentation
Basics of Numerical Optimization: Iterative Methods Ju Sun Computer Science & Engineering University of Minnesota, Twin Cities February 13, 2020 1 / 43 Find global minimum 1st-order necessary condition : Assume f is 1st-order
How to choose a search direction? We want to decrease the function value toward global minimum... shortsighted answer : find a direction to decrease most rapidly farsighted answer : find a direction based on both gradient and Hessian for any fixed t > 0 , using 2nd-order Taylor expansion f ( x k + t v ) − f ( v ) ≈ t �∇ f ( x k ) , v � + 1 2 t 2 � � v , ∇ 2 f ( x k ) v minimizing the right side � − 1 ∇ f ( x k ) ⇒ v = − t − 1 � ∇ 2 f ( x k ) = grad desc: green; Newton: red � − 1 ∇ f ( x k ) � ∇ 2 f ( x k ) Set d k = � − 1 ∇ f ( x k ) , � ∇ 2 f ( x k ) Newton’s method : x k +1 = x k − t t can set to be 1 . 8 / 43
Why called Newton’s method? � − 1 ∇ f ( x k ) , � ∇ 2 f ( x k ) Newton’s method : x k +1 = x k − t Recall Newton’s method for root-finding x k +1 = x k − f ′ ( x n ) f ( x n ) 9 / 43
Why called Newton’s method? � − 1 ∇ f ( x k ) , � ∇ 2 f ( x k ) Newton’s method : x k +1 = x k − t Recall Newton’s method for root-finding x k +1 = x k − f ′ ( x n ) f ( x n ) Newton’s method for solving nonliear system f ( x ) = 0 x k +1 = x k − [ J f ( x n )] † f ( x n ) 9 / 43
Why called Newton’s method? � − 1 ∇ f ( x k ) , � ∇ 2 f ( x k ) Newton’s method : x k +1 = x k − t Recall Newton’s method for root-finding x k +1 = x k − f ′ ( x n ) f ( x n ) Newton’s method for solving nonliear system f ( x ) = 0 x k +1 = x k − [ J f ( x n )] † f ( x n ) Newton’s method for solving ∇ f ( x ) = 0 � − 1 f ( x n ) � ∇ 2 f ( x n ) x k +1 = x k − 9 / 43
How to choose a search direction? grad desc: green; Newton: red Newton’s method take fewer steps 10 / 43
How to choose a search direction? nearsighted choice: cost O ( n ) per step gradient/steepest descent : x k +1 = x k − t ∇ f ( x k ) grad desc: green; Newton: red Newton’s method take fewer steps 10 / 43
How to choose a search direction? nearsighted choice: cost O ( n ) per step gradient/steepest descent : x k +1 = x k − t ∇ f ( x k ) farsighted choice: cost O ( n 3 ) per step Newton’s method : x k +1 = � − 1 ∇ f ( x k ) , � ∇ 2 f ( x k ) x k − t grad desc: green; Newton: red Newton’s method take fewer steps 10 / 43
How to choose a search direction? nearsighted choice: cost O ( n ) per step gradient/steepest descent : x k +1 = x k − t ∇ f ( x k ) farsighted choice: cost O ( n 3 ) per step Newton’s method : x k +1 = � − 1 ∇ f ( x k ) , � ∇ 2 f ( x k ) x k − t Implication: The plain Newton never grad desc: green; Newton: red used for large-scale problems. More on Newton’s method take fewer steps this later ... 10 / 43
Problems with Newton’s method � − 1 ∇ f ( x k ) , � ∇ 2 f ( x k ) Newton’s method : x k +1 = x k − t 11 / 43
Problems with Newton’s method � − 1 ∇ f ( x k ) , � ∇ 2 f ( x k ) Newton’s method : x k +1 = x k − t for any fixed t > 0 , using 2nd-order Taylor expansion f ( x k + t v ) − f ( v ) ≈ t �∇ f ( x k ) , v � + 1 2 t 2 � � v , ∇ 2 f ( x k ) v � − 1 ∇ f ( x k ) ⇒ v = − t − 1 � ∇ 2 f ( x k ) minimizing the right side = 11 / 43
Problems with Newton’s method � − 1 ∇ f ( x k ) , � ∇ 2 f ( x k ) Newton’s method : x k +1 = x k − t for any fixed t > 0 , using 2nd-order Taylor expansion f ( x k + t v ) − f ( v ) ≈ t �∇ f ( x k ) , v � + 1 2 t 2 � � v , ∇ 2 f ( x k ) v � − 1 ∇ f ( x k ) ⇒ v = − t − 1 � ∇ 2 f ( x k ) minimizing the right side = – ∇ 2 f ( x k ) may be non-invertible 11 / 43
Problems with Newton’s method � − 1 ∇ f ( x k ) , � ∇ 2 f ( x k ) Newton’s method : x k +1 = x k − t for any fixed t > 0 , using 2nd-order Taylor expansion f ( x k + t v ) − f ( v ) ≈ t �∇ f ( x k ) , v � + 1 2 t 2 � � v , ∇ 2 f ( x k ) v � − 1 ∇ f ( x k ) ⇒ v = − t − 1 � ∇ 2 f ( x k ) minimizing the right side = – ∇ 2 f ( x k ) may be non-invertible � � � − 1 ∇ f ( x k ) � – the minimum value is − 1 ∇ 2 f ( x k ) ∇ f ( x k ) , . If 2 ∇ 2 f ( x k ) not positive definite, may be positive 11 / 43
Problems with Newton’s method � − 1 ∇ f ( x k ) , � ∇ 2 f ( x k ) Newton’s method : x k +1 = x k − t for any fixed t > 0 , using 2nd-order Taylor expansion f ( x k + t v ) − f ( v ) ≈ t �∇ f ( x k ) , v � + 1 2 t 2 � � v , ∇ 2 f ( x k ) v � − 1 ∇ f ( x k ) ⇒ v = − t − 1 � ∇ 2 f ( x k ) minimizing the right side = – ∇ 2 f ( x k ) may be non-invertible � � � − 1 ∇ f ( x k ) � – the minimum value is − 1 ∇ 2 f ( x k ) ∇ f ( x k ) , . If 2 ∇ 2 f ( x k ) not positive definite, may be positive solution : e.g., modify the Hessian ∇ 2 f ( x k ) + τ I with τ sufficiently large 11 / 43
How to choose step size? x k = x k − 1 + t k d k 12 / 43
How to choose step size? x k = x k − 1 + t k d k – Naive choice: sufficiently small constant t for all k 12 / 43
How to choose step size? x k = x k − 1 + t k d k – Naive choice: sufficiently small constant t for all k – Robust and practical choice: back-tracking line search 12 / 43
How to choose step size? x k = x k − 1 + t k d k – Naive choice: sufficiently small constant t for all k – Robust and practical choice: back-tracking line search Intuition for back-tracking line search: – By Taylor’s theorem, � � f ( x k + t d k ) = f ( x k ) + t �∇ f ( x k ) , d k � + o t � d k � 2 when t sufficiently small — t �∇ f ( x k ) , d k � dictates the value decrease 12 / 43
How to choose step size? x k = x k − 1 + t k d k – Naive choice: sufficiently small constant t for all k – Robust and practical choice: back-tracking line search Intuition for back-tracking line search: – By Taylor’s theorem, � � f ( x k + t d k ) = f ( x k ) + t �∇ f ( x k ) , d k � + o t � d k � 2 when t sufficiently small — t �∇ f ( x k ) , d k � dictates the value decrease – But we also want t large as possible to make rapid progress 12 / 43
How to choose step size? x k = x k − 1 + t k d k – Naive choice: sufficiently small constant t for all k – Robust and practical choice: back-tracking line search Intuition for back-tracking line search: – By Taylor’s theorem, � � f ( x k + t d k ) = f ( x k ) + t �∇ f ( x k ) , d k � + o t � d k � 2 when t sufficiently small — t �∇ f ( x k ) , d k � dictates the value decrease – But we also want t large as possible to make rapid progress – idea : find a large possible t ∗ to make sure f ( x k + t ∗ d k ) − f ( x k ) ≤ ct ∗ �∇ f ( x k ) , d k � ( key condition ) for a chosen parameter c ∈ (0 , 1) , and no less 12 / 43
How to choose step size? x k = x k − 1 + t k d k – Naive choice: sufficiently small constant t for all k – Robust and practical choice: back-tracking line search Intuition for back-tracking line search: – By Taylor’s theorem, � � f ( x k + t d k ) = f ( x k ) + t �∇ f ( x k ) , d k � + o t � d k � 2 when t sufficiently small — t �∇ f ( x k ) , d k � dictates the value decrease – But we also want t large as possible to make rapid progress – idea : find a large possible t ∗ to make sure f ( x k + t ∗ d k ) − f ( x k ) ≤ ct ∗ �∇ f ( x k ) , d k � ( key condition ) for a chosen parameter c ∈ (0 , 1) , and no less – details : start from t = 1 . If the key condition not satisfied, t = ρt for a chosen parameter ρ ∈ (0 , 1) . 12 / 43
Back-tracking line search A widely implemented strategy in numerical optimization packages Back-tracking line search Input: initial t > 0 , ρ ∈ (0 , 1) , c ∈ (0 , 1) 1: while f ( x k + t d k ) − f ( x k ) ≥ ct �∇ f ( x k ) , d k � do t = ρt 2: 3: end while Output: t k = t . 13 / 43
Where to initialize? convex vs. nonconvex functions 14 / 43
Where to initialize? convex vs. nonconvex functions – Convex : most iterative methods converge to the global min no matter the initialization 14 / 43
Where to initialize? convex vs. nonconvex functions – Convex : most iterative methods converge to the global min no matter the initialization – Nonconvex : initialization matters a lot. Common heuristics: random initialization, multiple independent runs 14 / 43
Where to initialize? convex vs. nonconvex functions – Convex : most iterative methods converge to the global min no matter the initialization – Nonconvex : initialization matters a lot. Common heuristics: random initialization, multiple independent runs – Nonconvex : clever initialization is possible with certain assumptions on the data: 14 / 43
Where to initialize? convex vs. nonconvex functions – Convex : most iterative methods converge to the global min no matter the initialization – Nonconvex : initialization matters a lot. Common heuristics: random initialization, multiple independent runs – Nonconvex : clever initialization is possible with certain assumptions on the data: https://sunju.org/research/nonconvex/ and sometimes random initialization works! 14 / 43
When to stop? 1st-order necessary condition : Assume f is 1st-order differentiable at x 0 . If x 0 is a local minimizer, then ∇ f ( x 0 ) = 0 . 2nd-order necessary condition : Assume f ( x ) is 2-order differentiable at x 0 . If x 0 is a local min, ∇ f ( x 0 ) = 0 and ∇ 2 f ( x 0 ) � 0 . 15 / 43
When to stop? 1st-order necessary condition : Assume f is 1st-order differentiable at x 0 . If x 0 is a local minimizer, then ∇ f ( x 0 ) = 0 . 2nd-order necessary condition : Assume f ( x ) is 2-order differentiable at x 0 . If x 0 is a local min, ∇ f ( x 0 ) = 0 and ∇ 2 f ( x 0 ) � 0 . Fix some positive tolerance values ε g , ε H , ε f , ε v . Possibilities: 15 / 43
When to stop? 1st-order necessary condition : Assume f is 1st-order differentiable at x 0 . If x 0 is a local minimizer, then ∇ f ( x 0 ) = 0 . 2nd-order necessary condition : Assume f ( x ) is 2-order differentiable at x 0 . If x 0 is a local min, ∇ f ( x 0 ) = 0 and ∇ 2 f ( x 0 ) � 0 . Fix some positive tolerance values ε g , ε H , ε f , ε v . Possibilities: – �∇ f ( x k ) � 2 ≤ ε g 15 / 43
When to stop? 1st-order necessary condition : Assume f is 1st-order differentiable at x 0 . If x 0 is a local minimizer, then ∇ f ( x 0 ) = 0 . 2nd-order necessary condition : Assume f ( x ) is 2-order differentiable at x 0 . If x 0 is a local min, ∇ f ( x 0 ) = 0 and ∇ 2 f ( x 0 ) � 0 . Fix some positive tolerance values ε g , ε H , ε f , ε v . Possibilities: – �∇ f ( x k ) � 2 ≤ ε g � � ∇ 2 f ( x k ) – �∇ f ( x k ) � 2 ≤ ε g and λ min ≥ − ε H 15 / 43
When to stop? 1st-order necessary condition : Assume f is 1st-order differentiable at x 0 . If x 0 is a local minimizer, then ∇ f ( x 0 ) = 0 . 2nd-order necessary condition : Assume f ( x ) is 2-order differentiable at x 0 . If x 0 is a local min, ∇ f ( x 0 ) = 0 and ∇ 2 f ( x 0 ) � 0 . Fix some positive tolerance values ε g , ε H , ε f , ε v . Possibilities: – �∇ f ( x k ) � 2 ≤ ε g � � ∇ 2 f ( x k ) – �∇ f ( x k ) � 2 ≤ ε g and λ min ≥ − ε H – | f ( x k ) − f ( x k − 1 ) | ≤ ε f 15 / 43
When to stop? 1st-order necessary condition : Assume f is 1st-order differentiable at x 0 . If x 0 is a local minimizer, then ∇ f ( x 0 ) = 0 . 2nd-order necessary condition : Assume f ( x ) is 2-order differentiable at x 0 . If x 0 is a local min, ∇ f ( x 0 ) = 0 and ∇ 2 f ( x 0 ) � 0 . Fix some positive tolerance values ε g , ε H , ε f , ε v . Possibilities: – �∇ f ( x k ) � 2 ≤ ε g � � ∇ 2 f ( x k ) – �∇ f ( x k ) � 2 ≤ ε g and λ min ≥ − ε H – | f ( x k ) − f ( x k − 1 ) | ≤ ε f – � x k − x k − 1 � 2 ≤ ε v 15 / 43
Nonconvex optimization is hard Nonconvex: Even computing (verifying!) a local minimizer is NP-hard! (see, e.g., [Murty and Kabadi, 1987]) 16 / 43
Nonconvex optimization is hard Nonconvex: Even computing (verifying!) a local minimizer is NP-hard! (see, e.g., [Murty and Kabadi, 1987]) 2nd order sufficient: ∇ f ( x 0 ) = 0 and ∇ 2 f ( x 0 ) ≻ 0 2nd order necessary: ∇ f ( x 0 ) = 0 and ∇ 2 f ( x 0 ) � 0 16 / 43
Nonconvex optimization is hard Nonconvex: Even computing (verifying!) a local minimizer is NP-hard! (see, e.g., [Murty and Kabadi, 1987]) 2nd order sufficient: ∇ f ( x 0 ) = 0 and ∇ 2 f ( x 0 ) ≻ 0 2nd order necessary: ∇ f ( x 0 ) = 0 and ∇ 2 f ( x 0 ) � 0 Cases in between: local shapes around SOSP determined by spectral properties of higher-order derivative tensors , calculating which is hard [Hillar and Lim, 2013]! 16 / 43
Outline Classic line-search methods Advanced line-search methods Momentum methods Quasi-Newton methods Coordinate descent Conjugate gradient methods Trust-region methods 17 / 43
Outline Classic line-search methods Advanced line-search methods Momentum methods Quasi-Newton methods Coordinate descent Conjugate gradient methods Trust-region methods 18 / 43
Why momentum? Credit: Princeton ELE522 – GD is cheap ( O ( n ) per step) but overall convergence sensitive to conditioning – Newton’s convergence is not sensitive to conditioning but expensive ( O ( n 3 ) per step) 19 / 43
Why momentum? Credit: Princeton ELE522 – GD is cheap ( O ( n ) per step) but overall convergence sensitive to conditioning – Newton’s convergence is not sensitive to conditioning but expensive ( O ( n 3 ) per step) A cheap way to achieve faster convergence? 19 / 43
Why momentum? Credit: Princeton ELE522 – GD is cheap ( O ( n ) per step) but overall convergence sensitive to conditioning – Newton’s convergence is not sensitive to conditioning but expensive ( O ( n 3 ) per step) A cheap way to achieve faster convergence? Answer: using historic information 19 / 43
Heavy ball method In physics, a heavy object has a large inertia/momentum — resistance to change velocity. 20 / 43
Heavy ball method In physics, a heavy object has a large inertia/momentum — resistance to change velocity. x k +1 = x k − α k ∇ f ( x k ) + β k ( x k − x k − 1 ) due to Polyak � �� � momentum 20 / 43
Heavy ball method In physics, a heavy object has a large inertia/momentum — resistance to change velocity. x k +1 = x k − α k ∇ f ( x k ) + β k ( x k − x k − 1 ) due to Polyak � �� � momentum Credit: Princeton ELE522 History helps to smooth out the zig-zag path! 20 / 43
Nesterov’s accelerated gradient methods Another version, due to Y. Nesterov x k +1 = x k + β k ( x k − x k − 1 ) − α k ∇ f ( x k + β k ( x k − x k − 1 )) 21 / 43
Nesterov’s accelerated gradient methods Another version, due to Y. Nesterov x k +1 = x k + β k ( x k − x k − 1 ) − α k ∇ f ( x k + β k ( x k − x k − 1 )) Credit: Stanford CS231N 21 / 43
Nesterov’s accelerated gradient methods Another version, due to Y. Nesterov x k +1 = x k + β k ( x k − x k − 1 ) − α k ∇ f ( x k + β k ( x k − x k − 1 )) Credit: Stanford CS231N For more info, see Chap 10 of [Beck, 2017] and Chap 2 of [Nesterov, 2018]. 21 / 43
Outline Classic line-search methods Advanced line-search methods Momentum methods Quasi-Newton methods Coordinate descent Conjugate gradient methods Trust-region methods 22 / 43
Quasi-Newton methods quasi-: seemingly; apparently but not really. Newton’s method: cost O ( n 2 ) storage and O ( n 3 ) computation per step � − 1 ∇ f ( x k ) � ∇ 2 f ( x k ) x k +1 = x k − t 23 / 43
Quasi-Newton methods quasi-: seemingly; apparently but not really. Newton’s method: cost O ( n 2 ) storage and O ( n 3 ) computation per step � − 1 ∇ f ( x k ) � ∇ 2 f ( x k ) x k +1 = x k − t � − 1 to allow efficient storage and � Idea: approximate ∇ 2 f ( x k ) or ∇ 2 f ( x k ) computation — Quasi-Newton Methods 23 / 43
Quasi-Newton methods quasi-: seemingly; apparently but not really. Newton’s method: cost O ( n 2 ) storage and O ( n 3 ) computation per step � − 1 ∇ f ( x k ) � ∇ 2 f ( x k ) x k +1 = x k − t � − 1 to allow efficient storage and � Idea: approximate ∇ 2 f ( x k ) or ∇ 2 f ( x k ) computation — Quasi-Newton Methods Choose H k to approximate ∇ 2 f ( x k ) so that – avoid calculation of second derivatives – simplify matrix inversion, i.e., computing the search direction 23 / 43
Quasi-Newton methods – Different variants differ on how to compute H k +1 – Normally H − 1 or its factorized version stored to simplify calculation k of ∆ x k Credit: UCLA ECE236C 24 / 43
BFGS method Broyden–Fletcher–Goldfarb–Shanno (BFGS) method 25 / 43
BFGS method Broyden–Fletcher–Goldfarb–Shanno (BFGS) method Cost of update: O ( n 2 ) (vs. O ( n 3 ) in Newton’s method), storage: O ( n 2 ) 25 / 43
BFGS method Broyden–Fletcher–Goldfarb–Shanno (BFGS) method Cost of update: O ( n 2 ) (vs. O ( n 3 ) in Newton’s method), storage: O ( n 2 ) To derive the update equations, three conditions are imposed: – secant condition: H k +1 s = y (think of 1st Taylor expansion to ∇ f ) – Curvature condition: s ⊺ k y k > 0 to ensure that H k +1 ≻ 0 if H k ≻ 0 – H k +1 and H k are close in an appropriate sense See Chap 6 of [Nocedal and Wright, 2006] Credit: UCLA ECE236C 25 / 43
Limited-memory BFGS (L-BFGS) 26 / 43
Limited-memory BFGS (L-BFGS) Cost of update: O ( mn ) (vs. O ( n 2 ) in BFGS), storage: O ( mn ) (vs. O ( n 2 ) in BFGS) — linear in dimension n ! recall the cost of GD? See Chap 7 of [Nocedal and Wright, 2006] Credit: UCLA ECE236C 26 / 43
Outline Classic line-search methods Advanced line-search methods Momentum methods Quasi-Newton methods Coordinate descent Conjugate gradient methods Trust-region methods 27 / 43
Block coordinate descent Consider a function f ( x 1 , . . . , x p ) with x 1 ∈ R n 1 , . . . , x p ∈ R n p 28 / 43
Block coordinate descent Consider a function f ( x 1 , . . . , x p ) with x 1 ∈ R n 1 , . . . , x p ∈ R n p A generic block coordinate descent algorithm Input: initialization ( x 1 , 0 , . . . , x p, 0 ) (the 2nd subscript indexes iteration number) 1: for k = 1 , 2 , . . . do 2: Pick a block index i ∈ { 1 , . . . , p } 3: Minimize wrt the chosen block: x i,k = arg min ξ ∈ R ni f ( x 1 ,k − 1 , . . . , x i − 1 ,k − 1 , ξ , x i +1 ,k − 1 , . . . , x p,k − 1 ) 4: Leave other blocks unchanged: x j,k = x j,k − 1 ∀ j � = i 5: end for 28 / 43
Block coordinate descent Consider a function f ( x 1 , . . . , x p ) with x 1 ∈ R n 1 , . . . , x p ∈ R n p A generic block coordinate descent algorithm Input: initialization ( x 1 , 0 , . . . , x p, 0 ) (the 2nd subscript indexes iteration number) 1: for k = 1 , 2 , . . . do 2: Pick a block index i ∈ { 1 , . . . , p } 3: Minimize wrt the chosen block: x i,k = arg min ξ ∈ R ni f ( x 1 ,k − 1 , . . . , x i − 1 ,k − 1 , ξ , x i +1 ,k − 1 , . . . , x p,k − 1 ) 4: Leave other blocks unchanged: x j,k = x j,k − 1 ∀ j � = i 5: end for – Also called alternating direction/minimization methods 28 / 43
Block coordinate descent Consider a function f ( x 1 , . . . , x p ) with x 1 ∈ R n 1 , . . . , x p ∈ R n p A generic block coordinate descent algorithm Input: initialization ( x 1 , 0 , . . . , x p, 0 ) (the 2nd subscript indexes iteration number) 1: for k = 1 , 2 , . . . do 2: Pick a block index i ∈ { 1 , . . . , p } 3: Minimize wrt the chosen block: x i,k = arg min ξ ∈ R ni f ( x 1 ,k − 1 , . . . , x i − 1 ,k − 1 , ξ , x i +1 ,k − 1 , . . . , x p,k − 1 ) 4: Leave other blocks unchanged: x j,k = x j,k − 1 ∀ j � = i 5: end for – Also called alternating direction/minimization methods – When n 1 = n 2 = · · · = n p = 1 , called coordinate descent 28 / 43
Block coordinate descent Consider a function f ( x 1 , . . . , x p ) with x 1 ∈ R n 1 , . . . , x p ∈ R n p A generic block coordinate descent algorithm Input: initialization ( x 1 , 0 , . . . , x p, 0 ) (the 2nd subscript indexes iteration number) 1: for k = 1 , 2 , . . . do 2: Pick a block index i ∈ { 1 , . . . , p } 3: Minimize wrt the chosen block: x i,k = arg min ξ ∈ R ni f ( x 1 ,k − 1 , . . . , x i − 1 ,k − 1 , ξ , x i +1 ,k − 1 , . . . , x p,k − 1 ) 4: Leave other blocks unchanged: x j,k = x j,k − 1 ∀ j � = i 5: end for – Also called alternating direction/minimization methods – When n 1 = n 2 = · · · = n p = 1 , called coordinate descent – Minimization in Line 3 can be inexact: e.g., ∂f x i,k = x i,k − 1 − t k ∂ ξ ( x 1 ,k − 1 , . . . , x i − 1 ,k − 1 , x i,k − 1 , x i +1 ,k − 1 , . . . , x p,k − 1 ) 28 / 43
Block coordinate descent Consider a function f ( x 1 , . . . , x p ) with x 1 ∈ R n 1 , . . . , x p ∈ R n p A generic block coordinate descent algorithm Input: initialization ( x 1 , 0 , . . . , x p, 0 ) (the 2nd subscript indexes iteration number) 1: for k = 1 , 2 , . . . do 2: Pick a block index i ∈ { 1 , . . . , p } 3: Minimize wrt the chosen block: x i,k = arg min ξ ∈ R ni f ( x 1 ,k − 1 , . . . , x i − 1 ,k − 1 , ξ , x i +1 ,k − 1 , . . . , x p,k − 1 ) 4: Leave other blocks unchanged: x j,k = x j,k − 1 ∀ j � = i 5: end for – Also called alternating direction/minimization methods – When n 1 = n 2 = · · · = n p = 1 , called coordinate descent – Minimization in Line 3 can be inexact: e.g., ∂f x i,k = x i,k − 1 − t k ∂ ξ ( x 1 ,k − 1 , . . . , x i − 1 ,k − 1 , x i,k − 1 , x i +1 ,k − 1 , . . . , x p,k − 1 ) – In Line 2, many different ways of picking an index, e.g., cyclic, randomized, weighted sampling, etc 28 / 43
Block coordinate descent: examples Least-squares min x f ( x ) = � y − Ax � 2 2 – � y − Ax � 2 2 = � y − A − i x − i − a i x i � 2 – coordinate descent: min ξ ∈ R � y − A − i x − i − a i ξ � 2 ⇒ x i, + = � y − A − i x − i , a i � = � a i � 2 2 ( A − i is A with the i -th column removed; x − i is x with the i -th coordinate removed) 29 / 43
Block coordinate descent: examples Least-squares min x f ( x ) = � y − Ax � 2 2 – � y − Ax � 2 2 = � y − A − i x − i − a i x i � 2 – coordinate descent: min ξ ∈ R � y − A − i x − i − a i ξ � 2 ⇒ x i, + = � y − A − i x − i , a i � = � a i � 2 2 ( A − i is A with the i -th column removed; x − i is x with the i -th coordinate removed) Matrix factorization min A , B � Y − AB � 2 F – Two groups of variables, consider block coordinate descent – Updates: A + = Y B † , B + = A † Y . ( · ) † denotes the matrix pseudoinverse.) 29 / 43
Why block coordinate descent? – may work with constrained problems and non-differentiable problems (e.g., min A , B � Y − AB � 2 F , s . t . A orthogonal , Lasso: min x � y − Ax � 2 2 + λ � x � 1 ) 30 / 43
Why block coordinate descent? – may work with constrained problems and non-differentiable problems (e.g., min A , B � Y − AB � 2 F , s . t . A orthogonal , Lasso: min x � y − Ax � 2 2 + λ � x � 1 ) – may be faster than gradient descent or Newton (next) 30 / 43
Why block coordinate descent? – may work with constrained problems and non-differentiable problems (e.g., min A , B � Y − AB � 2 F , s . t . A orthogonal , Lasso: min x � y − Ax � 2 2 + λ � x � 1 ) – may be faster than gradient descent or Newton (next) – may be simple and cheap! 30 / 43
Why block coordinate descent? – may work with constrained problems and non-differentiable problems (e.g., min A , B � Y − AB � 2 F , s . t . A orthogonal , Lasso: min x � y − Ax � 2 2 + λ � x � 1 ) – may be faster than gradient descent or Newton (next) – may be simple and cheap! Some references: – [Wright, 2015] – Lecture notes by Prof. Ruoyu Sun 30 / 43
Outline Classic line-search methods Advanced line-search methods Momentum methods Quasi-Newton methods Coordinate descent Conjugate gradient methods Trust-region methods 31 / 43
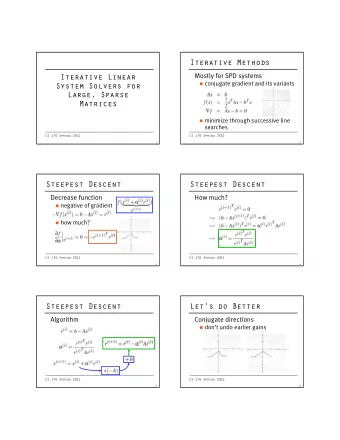
Conjugate direction methods 1 Solve linear equation y = Ax ⇐ ⇒ min x 2 x ⊺ Ax − b ⊺ x with A ≻ 0 32 / 43
Recommend






















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.