Administrivia Mini project is graded 1 st place: Justin (75.45) 2 - PowerPoint PPT Presentation
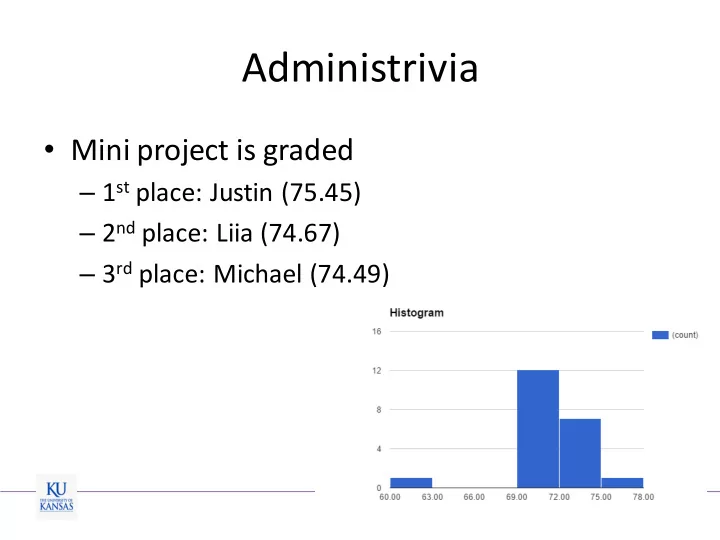
Administrivia Mini project is graded 1 st place: Justin (75.45) 2 nd place: Liia (74.67) 3 rd place: Michael (74.49) 1 Administrivia Project proposal due: 2/27 Original research Related to real-time embedded systems/CPS
Administrivia • Mini project is graded – 1 st place: Justin (75.45) – 2 nd place: Liia (74.67) – 3 rd place: Michael (74.49) 1
Administrivia • Project proposal due: 2/27 – Original research • Related to real-time embedded systems/CPS – Building a cyber-physical system (robot) • Must include real-time performance evaluation on a selected hardware platform – Repeating the evaluation of a chosen paper • Any one of the suggested papers. 2
Administrivia • Addition presentation schedule – 2 papers/day on Week 15 (a week before final) • eliminate individual meeting Or – 2 papers/day on Week 11,12,13 • Keep individual meeting 3
Real-Time DRAM Controller Heechul Yun 4
Memory Performance Isolation Part 3 Part 4 Part 2 Part 1 Core3 Core1 Core2 Core4 LLC LLC LLC LLC Memory Controller DRAM • Q. How to guarantee predictable memory performance? 5
How Page Works REQUEST #1 close the previous page REQUEST #1 COMPLETES, and load new one REQUEST #2 ARRIVES ARRIVES REQUEST #2 PRE ACT DATA READ COMPLETES Latency of Request #1 DATA READ page is already open, Latency of Request #2 just issue read command (with open page) * Latency – First Latency – Data Cycles for Access Further Accesses each core Single Core 35 9 4 • in clock cycles on a JEDEC-compliant DDR3 module
Effects of Contention ALL REQUESTS ARRIVE AT THE SAME TIME, TARGETED AT SAME BANK AND RANK P A D R P A R D P A D R * Latency – First Latency – Further Data Cycles for Access Accesses each core Single Core 35 9 4 Multiple Cores – 35*N 35*N 4 same bank/rank
Effects of Contention ALL REQUESTS ARRIVE AT THE SAME TIME, TARGETED AT DIFFERENT RANKS PRE ACT R DATA PRE ACT R DATA PRE ACT DATA R * Latency – First Latency – Further Data Cycles used Access Accesses by each access Single Core 35 9 4 N Cores – same 35 + 35*(N-1) 35 + 35*(N-1) 4 bank/rank N Cores – different 35 + 4*(N-1) 9 + 4*(N-1) 4 ranks
Real-Time Memory Controllers • Provided guaranteed performance in accessing DRAM. 9
Real-Time Memory Controllers • Common techniques – Command grouping • Force to use ALL banks for each memory access – Private banking • Assign private DRAM banks to cores – Scheduling • Use analysis friendly scheduling (e.g., round-robin) over difficult ones (e.g., FR-FCFS) 10
Predator 11
Worst-case Core1 Core2 Core3 Core4 L3 Memory Controller (MC) Slow DRAM DIMM • 1bank b/w Bank Bank Bank Bank – Less than peak b/w 1 2 3 4 – How much?
Worst-Case For Single-Bank: Horrible 13
Bank Interleaving and Groups 14
Arbitration: CCSP 15
Controller Architecture 16
Real-Time Memory Controllers (RTMC) • Predator – Command grouping, CCSP arbitration • AMC – Command grouping, round-robin arbitration • PRET-MC – Private bank, TDMA arbitration • DcMc, MEDUSA – RR + FR-FCFS hybrid, bank partitioning • Read/Write Bundling – Reduce bus turn-around overhead. . 17
RTMC References • Predator: a predictable sdram memory controller”. CODES+ISSS 2007. • An analyzable memory controller for hard real-time CMPs, IEEE Embedded Systems Letters, 2009 • PRET DRAM controller: Bank privatization for predictability and temporal isolation, CODES+ISSS, 2011 • A dual-criticality memory controller (dcmc): Proposal and evaluation of a space case study, RTAS, 2015 • Improved DRAM Timing Bounds for Real-Time DRAM Controllers with Read/Write Bundling, 2016 • A Comprehensive Study of DRAM Controllers in Real-Time Systems. Danlu Guo, MS Thesis, University of Waterloo, 2016 18
Real-Time Multi/Many-Core Architecture • Why is it difficult to analyze WCET? • Projects on Real-Time CPU Architectures 19
Worst-Case Execution Time (WCET) Image source: [Wilhelm et al., 2008] • Real-time scheduling theory is based on the assumption of known WCETs of real-time tasks 20
Computing WCET • Static analysis – Input: program code, architecture model – output: WCET – Problem: architecture model is hard and pessimistic (recall “Parallelism - aware…” paper) • Measurement – No guarantee on true worst-case – But, widely used in practice 21
Memory Hierarchies, Pipelines, and Buses for Future Architectures in Time-Critical Embedded Systems 22
“Problematic” CPU Features • Architectures are optimized to reduce average performance • WCET estimation is hard because of – Pipelining – TLBs/Caches – Super-scalar – Out-of-order scheduling – Branch predictors – Hardware prefetchers – Basically anything that affect processor state 23
Static Timing Analysis processor’ finally control-flo 24 [11]–[13]. control-flo flo ely—together interactions—to first first ol-flow program’ flo control-flo influence identifies influence ol-flow influence
Control Flow Graph (CFG) • Analyze code • Split basic blocks • Compute per-block WCET – use abstract CPU model 25
Timing Anomalies • Locally faster != globally faster 26 Image source: [Wilhelm et al., 2008]
Timing Anomalies • Locally faster != globally faster 27 Image source: [Wilhelm et al., 2008]
Real-Time CPU Architectures • PRET – UC Berkeley. • MERASA/parMERASA project – EU • ACROSS – EU • ARAMIS – Germany • EMC2 – EU 28
29
PRET Pipeline Thread 1, Instruction 1 Thread 1, Instruction 2 DECOD EXECUT DECOD EXECUT THREAD#1 FETCH REGACC MEM EXCEPT FETCH REGACC MEM EXCEPT E E E E DECOD EXECUT DECOD EXECUT THREAD#2 FETCH REGACC MEM EXCEPT FETCH REGACC MEM E E E E DECOD EXECUT DECOD THREAD#3 FETCH REGACC MEM EXCEPT FETCH REGACC MEM E E E DECOD EXECUT DECOD FETCH REGACC MEM EXCEPT FETCH REGACC THREAD#4 E E E DECOD EXECUT DECOD FETCH REGACC MEM EXCEPT FETCH THREAD#5 E E E DECOD EXECUT FETCH REGACC MEM EXCEPT FETCH E E THREAD#6 t 1 clock 30
FlexPRET Pipeline 31
MERASA Multicore 32
33
Acknowledgement • Some slides are from: – Prof. Rodolfo Pellizzoni, University of Waterloo – Prof. Edward A. Lee, University of Berkeley 34
Summary • Timing anomalies – Locally fast != globally fast on non-timing compositional architectures (i.e., most architectures) • Timing compositional architecture – Free of timing anomalies 35
Recommend
























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.