
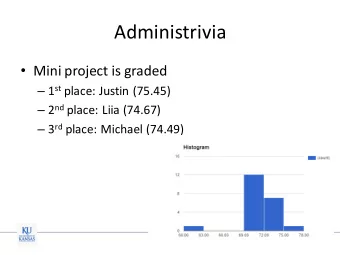
Administrivia Mini project deadline: today Attach the capture of - PowerPoint PPT Presentation
Administrivia Mini project deadline: today Attach the capture of the evaluation run output Guest lecture on Friday Algorithmic Verification of Stability of Hybrid Systems by Dr. Pavithra Prabhakar. K-State 1 Administrivia
Administrivia • Mini project deadline: today – Attach the capture of the evaluation run output • Guest lecture on Friday – Algorithmic Verification of Stability of Hybrid Systems by Dr. Pavithra Prabhakar. K-State 1
Administrivia • Project proposal due: 2/27 – Original research • Related to real-time embedded systems/CPS – Building a cyber-physical system (robot) • Must include real-time performance evaluation on a selected hardware platform – Repeating the evaluation of a chosen paper • Any one of the suggested papers. 2
Real-Time DRAM Controller Heechul Yun 3
Multicore for Embedded Systems • Benefits of multicore processors – Lots of sensor data to process – More performance, less cost – Save space, weight, power (SWaP) 4
Challenges: Shared Resources T T T T T T T T T1 T2 1 2 3 4 5 6 7 8 Core Core Core Core CPU 4 1 2 3 Memory Hierarchy Memory Hierarchy Unicore Multicore Performance Impact 5
Why is DRAM Important? • Why do we need bigger and faster memory? • Data intensive computing – Bigger, more complex application – Large amount of data processing 6
Why is DRAM Important? • Parallelism – Out-of-order core • A single core can generate many memory requests – Multicore • Multiple cores share DRAM – Accelerator • GPU 7
Memory Performance Isolation Part 2 Part 3 Part 4 Part 1 Core3 Core1 Core2 Core4 LLC LLC LLC LLC Memory Controller DRAM • Q. How to guarantee predictable memory performance? 8
Memory System Architecture L2 CACHE 0 L2 CACHE 1 SHARED L3 CACHE DRAM INTERFACE DRAM BANKS CORE 0 CORE 1 DR DRAM MEM EMORY CONTRO ROLLER L2 CACHE 2 L2 CACHE 3 CORE 2 CORE 3 This slide is from Prof. Onur Mutlu 9
DRAM Organization • Channel • Rank • Chip • Bank • Row • Row/Column 10
The DRAM subsystem “ Channel ” DIMM (Dual in-line memory module) Processor Memory channel Memory channel This slide is from Prof. Onur Mutlu
Breaking down a DIMM DIMM (Dual in-line memory module) Side view Front of DIMM Back of DIMM This slide is from Prof. Onur Mutlu
Breaking down a DIMM DIMM (Dual in-line memory module) Side view Front of DIMM Back of DIMM Rank 0: collection of 8 chips Rank 1 This slide is from Prof. Onur Mutlu
Rank Rank 0 (Front) Rank 1 (Back) <0:63> <0:63> Addr/Cmd CS <0:1> Data <0:63> Memory channel This slide is from Prof. Onur Mutlu
Breaking down a Rank . . . Chip 0 Chip 1 Chip 7 Rank 0 <56:63> <8:15> <0:7> <0:63> Data <0:63> This slide is from Prof. Onur Mutlu
Breaking down a Chip Chip 0 Bank 0 <0:7> <0:7> <0:7> ... <0:7> <0:7> This slide is from Prof. Onur Mutlu
Breaking down a Bank 2kB 1B (column) row 16k-1 ... Bank 0 row 0 <0:7> Row-buffer 1B 1B 1B ... <0:7> This slide is from Prof. Onur Mutlu
Example: Transferring a cache block Physical memory space 0xFFFF…F Channel 0 ... DIMM 0 0x40 Rank 0 64B cache block 0x00 This slide is from Prof. Onur Mutlu
Example: Transferring a cache block Physical memory space Chip 0 Chip 1 Chip 7 Rank 0 0xFFFF…F . . . ... <56:63> <8:15> <0:7> 0x40 64B Data <0:63> cache block 0x00 This slide is from Prof. Onur Mutlu
Example: Transferring a cache block Physical memory space Chip 0 Chip 1 Chip 7 Rank 0 0xFFFF…F . . . Row 0 Col 0 ... <56:63> <8:15> <0:7> 0x40 64B Data <0:63> cache block 0x00 This slide is from Prof. Onur Mutlu
Example: Transferring a cache block Physical memory space Chip 0 Chip 1 Chip 7 Rank 0 0xFFFF…F . . . Row 0 Col 0 ... <56:63> <8:15> <0:7> 0x40 64B Data <0:63> cache block 8B 0x00 8B This slide is from Prof. Onur Mutlu
Example: Transferring a cache block Physical memory space Chip 0 Chip 1 Chip 7 Rank 0 0xFFFF…F . . . Row 0 Col 1 ... <56:63> <8:15> <0:7> 0x40 64B Data <0:63> cache block 8B 0x00 This slide is from Prof. Onur Mutlu
Example: Transferring a cache block Physical memory space Chip 0 Chip 1 Chip 7 Rank 0 0xFFFF…F . . . Row 0 Col 1 ... <56:63> <8:15> <0:7> 0x40 64B Data <0:63> 8B cache block 8B 0x00 8B This slide is from Prof. Onur Mutlu
Example: Transferring a cache block Physical memory space Chip 0 Chip 1 Chip 7 Rank 0 0xFFFF…F . . . Row 0 Col 1 ... <56:63> <8:15> <0:7> 0x40 64B Data <0:63> 8B cache block 8B 0x00 A 64B cache block takes 8 I/O cycles to transfer. During the process, 8 columns are read sequentially. This slide is from Prof. Onur Mutlu
DRAM Organization Core1 Core2 Core3 Core4 L3 Memory Controller (MC) • DRAM DIMM Have multiple banks • Different banks can be accessed in parallel Bank Bank Bank Bank 1 2 3 4
Best-case Core1 Core2 Core3 Core4 L3 Memory Controller (MC) Fast DRAM DIMM • Peak = 10.6 GB/s Bank Bank Bank Bank – DDR3 1333Mhz 1 2 3 4
Best-case Core1 Core2 Core3 Core4 L3 Memory Controller (MC) Fast DRAM DIMM • Peak = 10.6 GB/s Bank Bank Bank Bank – DDR3 1333Mhz 1 2 3 4 • Out-of-order processors
Most-cases Core1 Core2 Core3 Core4 L3 Memory Controller (MC) Mess DRAM DIMM • Performance = ?? Bank Bank Bank Bank 1 2 3 4
Worst-case Core1 Core2 Core3 Core4 L3 Memory Controller (MC) Slow DRAM DIMM • 1bank b/w Bank Bank Bank Bank – Less than peak b/w 1 2 3 4 – How much?
DRAM Chip Bank 4 Bank 3 Bank 2 READ (Bank 1, Row 3, Col 7) Bank 1 Row 1 precharge Row 2 Col7 Row 3 Row 4 Row 5 activate Row Buffer Read/write • State dependent access latency – Row miss: 19 cycles, Row hit: 9 cycles (*) PC6400-DDR2 with 5-5-5 (RAS-CAS-CL latency setting)
DDR3 Timing Parameters Kim et al., “Bounding Memory Interference Delay in COTS-based Multi-Core Systems,” RTAS’14 31
DRAM Controller • Service DRAM requests (from CPU) while obeying timing/resource constraints – Translate requests to DRAM command sequences – Timing constraints: e.g., minimum write-to-read delay, activation time, … – Resource conflicts: bank, bus, channel • Maximize performance – Buffering, reordering, pipelining in scheduling requests 32
DRAM Controller Bruce Jacob et al, “Memory Systems: Cache, DRAM, Disk” Fig 13.1. • Request queue – Buffer read/write requests from CPU cores – Unpredictable queuing delay due to reordering 33
Request Reordering Initial Queue Reordered Queue Core1: READ Row 1, Col 1 Core1: READ Row 1, Col 1 Core2: READ Row 2, Col 1 Core1: READ Row 1, Col 2 Core1: READ Row 1, Col 2 Core2: READ Row 2, Col 1 DRAM DRAM 2 Row Switch 1 Row Switch • Improve row hit ratio and throughput • Unpredictable queuing delay 34
Row Management Policy • Open row – Keep the row open after an access • If next access targets the same row: CAS • If next access targets a different row: PRE + ACT + CAS • Close row – Close the row after an access • always pay the same (longer) cost: ACT + CAS • Adaptive policies 35
Real-Time Memory Controllers • Provided guaranteed performance in accessing DRAM. 36
Real-Time Memory Controllers • Bank grouping – Each mem req. access ALL banks • Private banking – Each core has dedicated DRAM banks • Scheduling – Use analysis friendly scheduling (e.g., round-robin) 37
Real-Time Memory Controllers (RTMC) • Predator • AMC • PRET-MC • DcMc • MEDUSA • Bundling 38
RTMC References • Predator: a predictable sdram memory controller”. CODES+ISSS 2007. • An analyzable memory controller for hard real-time CMPs, IEEE Embedded Systems Letters, 2009 • PRET DRAM controller: Bank privatization for predictability and temporal isolation, CODES+ISSS, 2011 • A dual-criticality memory controller (dcmc): Proposal and evaluation of a space case study, RTAS, 2015 • Improved DRAM Timing Bounds for Real-Time DRAM Controllers with Read/Write Bundling, 2016 • A Comprehensive Study of DRAM Controllers in Real-Time Systems. Danlu Guo, MS Thesis, University of Waterloo, 2016 39
Recommend






















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.