
CS 4803 / 7643: Deep Learning Topics: Backpropagation - PowerPoint PPT Presentation
CS 4803 / 7643: Deep Learning Topics: Backpropagation Vector/Matrix/Tensor math Deriving vectorized gradients for ReLU Zsolt Kira Georgia Tech Administrivia PS1/HW1 out Start thinking about project topics/teams (C)
CS 4803 / 7643: Deep Learning Topics: – Backpropagation – Vector/Matrix/Tensor math – Deriving vectorized gradients for ReLU Zsolt Kira Georgia Tech
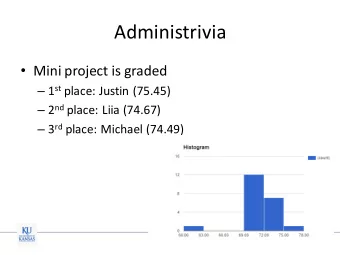
Administrivia • PS1/HW1 out • Start thinking about project topics/teams (C) Dhruv Batra & Zsolt Kira 2
Do the Readings! (C) Dhruv Batra & Zsolt Kira 3
Recap from last time (C) Dhruv Batra & Zsolt Kira 4
Gradient Descent Pseudocode for i in {0,…,num_epochs}: for x, y in data: 𝑧 � � 𝑇𝑁 𝑋𝑦 𝑀 � 𝐷𝐹 𝑧 �, 𝑧 �� �� �? ? ? �� 𝑋 ≔ 𝑋 � 𝛽 �� Some design decisions: • How many examples to use to calculate gradient per iteration? • What should alpha (learning rate) be? • Should it be constant throughout? • How many epochs to run to?
How to Simplify? • Calculating gradients for large functions is complicated • Step 1 : Decompose the function and compute local gradients for each part! • Step 2: Apply generic algorithm that computes gradients locally and uses chain rule to propagate across computation graph (C) Dhruv Batra & Zsolt Kira 6
Computational Graph Any DAG of differentiable modules is allowed! (C) Dhruv Batra & Zsolt Kira 7 Slide Credit: Marc'Aurelio Ranzato
Key Computation: Forward-Prop (C) Dhruv Batra & Zsolt Kira 8 Slide Credit: Marc'Aurelio Ranzato, Yann LeCun
Key Computation: Back-Prop (C) Dhruv Batra & Zsolt Kira 9 Slide Credit: Marc'Aurelio Ranzato, Yann LeCun
Neural Network Training • Step 1: Compute Loss on mini-batch [F-Pass] (C) Dhruv Batra & Zsolt Kira 10 Slide Credit: Marc'Aurelio Ranzato, Yann LeCun
Neural Network Training • Step 1: Compute Loss on mini-batch [F-Pass] (C) Dhruv Batra & Zsolt Kira 11 Slide Credit: Marc'Aurelio Ranzato, Yann LeCun
Neural Network Training • Step 1: Compute Loss on mini-batch [F-Pass] (C) Dhruv Batra & Zsolt Kira 12 Slide Credit: Marc'Aurelio Ranzato, Yann LeCun
Neural Network Training • Step 1: Compute Loss on mini-batch [F-Pass] • Step 2: Compute gradients wrt parameters [B-Pass] (C) Dhruv Batra & Zsolt Kira 13 Slide Credit: Marc'Aurelio Ranzato, Yann LeCun
Neural Network Training • Step 1: Compute Loss on mini-batch [F-Pass] • Step 2: Compute gradients wrt parameters [B-Pass] (C) Dhruv Batra & Zsolt Kira 14 Slide Credit: Marc'Aurelio Ranzato, Yann LeCun
Neural Network Training • Step 1: Compute Loss on mini-batch [F-Pass] • Step 2: Compute gradients wrt parameters [B-Pass] (C) Dhruv Batra & Zsolt Kira 15 Slide Credit: Marc'Aurelio Ranzato, Yann LeCun
Neural Network Training • Step 1: Compute Loss on mini-batch [F-Pass] • Step 2: Compute gradients wrt parameters [B-Pass] • Step 3: Use gradient to update parameters (C) Dhruv Batra & Zsolt Kira 16 Slide Credit: Marc'Aurelio Ranzato, Yann LeCun
Backpropagation: a simple example e.g. x = -2, y = 5, z = -4 Chain rule: Want: Upstream Local gradient gradient 17 Slide Credit: Fei-Fei Li, Justin Johnson, Serena Yeung, CS 231n
Patterns in backward flow add gate: gradient distributor max gate: gradient router mul gate: gradient switcher Slide Credit: Fei-Fei Li, Justin Johnson, Serena Yeung, CS 231n
Summary • We will have a composed non-linear function as our model – Several portions will have parameters • We will use (stochastic/mini-batch) gradient descent with a loss function to define our objective • Rather than analytically derive gradients for complex function, we will modularize computation – Back propagation = Gradient Descent + Chain Rule • Now: – Work through mathematical view – Vectors, matrices, and tensors – Next time: Can the computer do this for us automatically? • Read: – https://explained.ai/matrix-calculus/index.html – https://www.cc.gatech.edu/classes/AY2020/cs7643_fall/slides/L5_gradients _notes.pdf (C) Dhruv Batra and Zsolt Kira 19
Matrix/Vector Derivatives Notation • Read: – https://explained.ai/matrix-calculus/index.html – https://www.cc.gatech.edu/classes/AY2020/cs7643_fall/slide s/L5_gradients_notes.pdf • Matrix/Vector Derivatives Notation • Vector Derivative Example • Extension to Tensors • Chain Rule: Composite Functions – Scalar Case – Vector Case – Jacobian view – Graphical view – Tensors • Logistic Regression Derivatives (C) Dhruv Batra & Zsolt Kira 20
(C) Dhruv Batra & Zsolt Kira 21
Recommend






















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.