UMBC A B M A L T F O U M B C I M Y O R T 1 - PowerPoint PPT Presentation
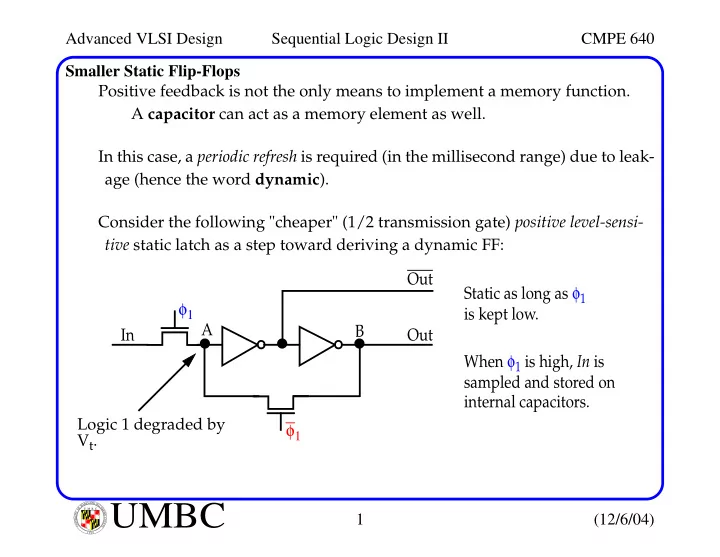
Advanced VLSI Design Sequential Logic Design II CMPE 640 Smaller Static Flip-Flops Positive feedback is not the only means to implement a memory function. A capacitor can act as a memory element as well. In this case, a periodic refresh is
Advanced VLSI Design Sequential Logic Design II CMPE 640 Smaller Static Flip-Flops Positive feedback is not the only means to implement a memory function. A capacitor can act as a memory element as well. In this case, a periodic refresh is required (in the millisecond range) due to leak- age (hence the word dynamic ). Consider the following "cheaper" (1/2 transmission gate) positive level-sensi- tive static latch as a step toward deriving a dynamic FF: Out Static as long as φ 1 φ 1 is kept low. A B In Out When φ 1 is high, In is sampled and stored on internal capacitors. Logic 1 degraded by φ 1 V t . L A N R Y D UMBC A B M A L T F O U M B C I M Y O R T 1 (12/6/04) I E S R C E O V U I N N U T Y 1 6 9 6
Advanced VLSI Design Sequential Logic Design II CMPE 640 Smaller Static Flip-Flops A master-slave FF is created by cascading two of these latches and reversing the clocks. φ 1 φ 1 Q QM A A B D N 1 N 2 φ 1 φ 1 The problem with this latch is that φ 1 and φ 1 might overlap, which may cause two types of failures: • Node A can become undefined as it is driven by both D and B when φ 1 and φ 1 are both high. • D can propagate through both the master and slave if both φ 1 and φ 1 are high simultaneously for a long enough period (race condition). L A N R Y D UMBC A B M A L T F O U M B C I M Y O R T 2 (12/6/04) I E S R C E O V U I N N U T Y 1 6 9 6
Advanced VLSI Design Sequential Logic Design II CMPE 640 Single Phase Clock Skew/Slew Clock skew causes conflicts and transparency. φ 1 φ 1 Both n transistors are "on". Clock slew (slow rise and fall times) can also cause transparency: φ 1 φ 1 Clock skew is a dominant problem in current high performance designs. L A N R Y D UMBC A B M A L T F O U M B C I M Y O R T 3 (12/6/04) I E S R C E O V U I N N U T Y 1 6 9 6
Advanced VLSI Design Sequential Logic Design II CMPE 640 Pseudo-Static Two-Phase Flip-Flops The fix is to use two non-overlapping clocks φ 1 and φ 2 : φ 1 φ 2 Q QM A A D φ 2 φ 1 A large t φ -12 allows proper operation even in the presence of clock skew. φ 1 t φ 1 t φ 12 φ 2 t φ 2 Note that node A floats (dynamic) during the time period t φ -12 but is driven during t φ -1 and t φ -2 (static). Hence, the name pseudostatic . L A N R Y D UMBC A B M A L T F O U M B C I M Y O R T 4 (12/6/04) I E S R C E O V U I N N U T Y 1 6 9 6
Advanced VLSI Design Sequential Logic Design II CMPE 640 CMOS Dynamic Two-Phase Flip-Flops This version is simplier (6 trans) and is often used in pipelined datapaths for microprocessors and signal processors. D Q φ 1 φ 2 Degraded ’1’ values may increase static current if below V tp . Disadv: 2 non-overlapping clocks required (4 if transmission gates are used). p leakers V DD V DD D Q φ 1 φ 2 p leakers provide fully restored logic levels. These implementations MUST be simulated at all process corners (under worst-case conditions). L A N R Y D UMBC A B M A L T F O U M B C I M Y O R T 5 (12/6/04) I E S R C E O V U I N N U T Y 1 6 9 6
Advanced VLSI Design Sequential Logic Design II CMPE 640 Two-Phase Clocking Clock skew/slew: Both n-transistors become transparent! Nonoverlapping clocks: φ 1 φ 1 logic Skew large delay φ 2 φ 2 logic small delay Overlap! φ 1 Excessive loads Slew can increase φ 2 rise/fall times. L A N R Y D UMBC A B M A L T F O U M B C I M Y O R T 6 (12/6/04) I E S R C E O V U I N N U T Y 1 6 9 6
Advanced VLSI Design Sequential Logic Design II CMPE 640 C 2 MOS Register C 2 MOS: A clever method which is insensitive to clock skew: φ 1 V DD V DD φ 1 V DD φ 1 φ 1 Q D Q D φ 1 φ 1 GND φ 1 φ 1 Note: Dual phase version is identical except φ 2 and φ 2 are used to drive the n/p-trans in the right inverter. L A N R Y D UMBC A B M A L T F O U M B C I M Y O R T 7 (12/6/04) I E S R C E O V U I N N U T Y 1 6 9 6
Advanced VLSI Design Sequential Logic Design II CMPE 640 C 2 MOS Register C 2 MOS is insensitive to overlap as long as the rise and fall times of the clk edges (clock slew) are sufficiently small: Acts as a negative edge-triggered V DD V DD master-slave D FF. φ 1 φ 1 Q D φ 1 φ 1 0-0 overlap 1-1 overlap V DD V DD V DD V DD No race is possible! 0 0 Q In order for D Q D D to race to the 1 1 Q, a pull-up followed by a pull-down must be enabled. L A N R Y D UMBC A B M A L T F O U M B C I M Y O R T 8 (12/6/04) I E S R C E O V U I N N U T Y 1 6 9 6
Advanced VLSI Design Sequential Logic Design II CMPE 640 C 2 MOS Register Races are just not possible since the overlaps activate either the pull-up or the pull-down networks but never both simultaneously. The inverters force 0-1 and 1-0 propagation modes only. However, if the rise and fall times of the clock are slow, there exists a time slot in which both n- and p-transistors are conducting simultaneously. Correct operation requires the clock rise/fall times be smaller than about 5 times the propagation delay through the FF. This is not hard to meet in practical designs, making C 2 MOS especially attractive in high speed designs where avoiding clock overlap is hard. L A N R Y D UMBC A B M A L T F O U M B C I M Y O R T 9 (12/6/04) I E S R C E O V U I N N U T Y 1 6 9 6
Advanced VLSI Design Sequential Logic Design II CMPE 640 Pipelining Reg Reg a a out out + + abs log abs log b b Reg Reg Reg Reg The minimum allowed clock for the pipelined system is: ( , , ) T min t q max t d,add t d,abs t d,log t s = + + Implementation using pass-transistor based D latches In Out F G C 1 C 2 C 3 φ φ φ As indicated, races can occur when φ and φ overlap. L A N R Y D UMBC A B M A L T F O U M B C I M Y O R T 10 (12/6/04) I E S R C E O V U I N N U T Y 1 6 9 6
Advanced VLSI Design Sequential Logic Design II CMPE 640 Pipelining C 2 MOS latches can be used instead, but ONLY if the logic functions, F , imple- mented between the latches are non-inverting . φ φ φ Out In G F φ φ φ C 2 C 3 C 1 1 0 1 If F is inverting, and φ and φ overlap (1-1), then C 2 is discharged as shown above. NORA-CMOS (NO-RAce) targets the implementation of fast pipelined data- paths by combining C 2 MOS with np -CMOS dynamic function blocks. L A N R Y D UMBC A B M A L T F O U M B C I M Y O R T 11 (12/6/04) I E S R C E O V U I N N U T Y 1 6 9 6
Advanced VLSI Design Sequential Logic Design II CMPE 640 Pipelining with NORA-CMOS φ φ φ -module φ In 1 PUN Evaluating Out In 2 when φ PDN φ In 3 is 1. φ φ Combo Latch φ In 4 φ -module φ In 1 Out In 2 PDN φ In 3 φ In 4 L A N R Y D UMBC A B M A L T F O U M B C I M Y O R T 12 (12/6/04) I E S R C E O V U I N N U T Y 1 6 9 6
Advanced VLSI Design Sequential Logic Design II CMPE 640 Pipelining with NORA-CMOS The NORA datapath consists of a chain of alternating φ and φ modules. While one class of modules is precharging with its output latch in hold mode , the other class is evaluating . Note that dynamic and static logic can be mixed freely. 0-0 clock overlap φ This implementation is problematic φ In 1 Out PDN φ In 2 φ Rule: # of static inversions between C 2 MOS latches should be even . When dynamic gates are present, the # of static inverters between a latch and dynamic gate and between the last dynamic gate and latch should be even . L A N R Y D UMBC A B M A L T F O U M B C I M Y O R T 13 (12/6/04) I E S R C E O V U I N N U T Y 1 6 9 6
Advanced VLSI Design Sequential Logic Design II CMPE 640 True Single-Phase Clocked Logic (TSPCL) The NORA design style can be simplified so that a single clock is sufficient. Out φ φ φ φ In In Out Doubled n-C 2 MOS latch Doubled p-C 2 MOS latch For the doubled n -C 2 MOS latch, when φ = 1, the latch is in the transparent evaluate mode and corresponds to 2 cascaded inverters (non-inverting). When φ = 0, both inverters are disabled ( hold mode) -- only the pull-up net- work is still active. The dual stage approach completely eliminates races . This style combines the advantages of C 2 MOS and eliminates all constraints. L A N R Y D UMBC A B M A L T F O U M B C I M Y O R T 14 (12/6/04) I E S R C E O V U I N N U T Y 1 6 9 6
Advanced VLSI Design Sequential Logic Design II CMPE 640 True Single-Phase Clocked Logic (TSPCL) The one disadvantage is that 6 transistors (vs. 4 ) are needed per latch. Include logic in the latch PUN Static φ φ φ φ In logic Out PDN A further simplification is to control only the first inverter with the clock. φ -latch φ -latch φ φ In In Out Out L A N R Y D UMBC A B M A L T F O U M B C I M Y O R T 15 (12/6/04) I E S R C E O V U I N N U T Y 1 6 9 6
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.