Topic Modeling and Clustering NIH Grants Neural Molecular/ Cellular - PowerPoint PPT Presentation
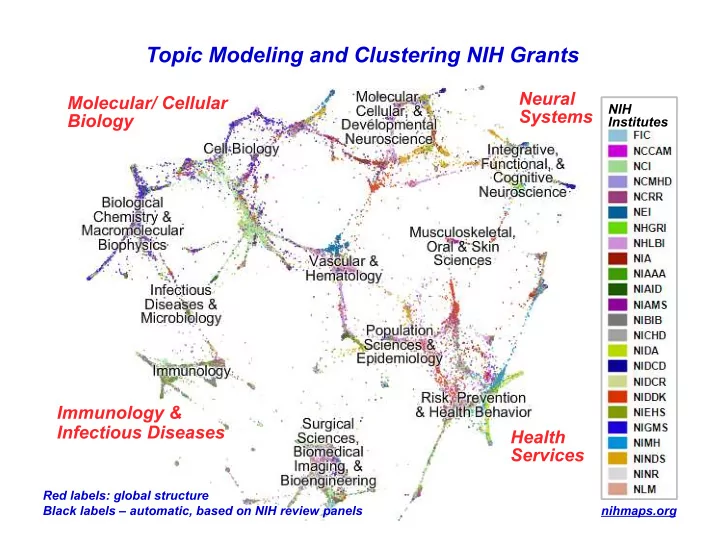
Topic Modeling and Clustering NIH Grants Neural Molecular/ Cellular NIH Systems Biology Institutes Immunology & Infectious Diseases Health Services Red labels: global structure Black labels automatic, based on NIH review panels
Topic Modeling and Clustering NIH Grants Neural Molecular/ Cellular NIH Systems Biology Institutes Immunology & Infectious Diseases Health Services Red labels: global structure Black labels – automatic, based on NIH review panels nihmaps.org
Two Complementary Analytic Systems Map-like Clusters Automated Topics • Based on overall textual similarity • Groupings of words determined by between grants statistical analysis • Represent groupings of grants that • Represent shared categories – each document consists of multiple topics share a common thematic focus
Background – NINDS Effort
Methods 1: Topic Modeling using LDA • Based on language in documents – not keywords – Native categories that are latent in the text – captures shared discourses – Groups of words rather than individual concepts – Context sensitive – accommodates diverse word meanings • Documents assigned to multiple categories – Documents treated as mixtures of topics • Quantitative information on textual content Topic allocation (proportion of words assigned to a topic) serves as a proxy for document relevance. Topic allocations are used for: – Topic-based queries – user sets document threshold – Ranking for lists of retrieved documents – Topic proportions for retrieved document sets – Measure similarity between documents
Methods 2: Graph Based Clustering using DrL • Force-directed algorithm – Nodes are attracted by similarity and repelled by areas of density – Highly scalable – Documents clustered based on lexical (topic and word) similarities • Surprising features – Local : thematically coherent clusters with striking face-validity – Intermediate : clusters linked in a lattice - links are formed by documents with “between cluster” focus – Global : compelling organization based on language rather than NIH bureaucratic structure • Interactive visual framework – Recognize patterns in the data that otherwise would be obscure
Document Upload for Analysis against NIH Awards Uploaded NSF Cognitive/Neuro Grants
Document Upload for Analysis against NIH Awards NIH Top Similar to Uploaded Documents NIH Study Sections CVP - Central Visual Processing COG - Cognitive Neuroscience CP - Cognition and Perception LCOM - Language and Communication NIH Program Directors STEINMETZ, MICHAEL (NEI) BABCOCK, DEBRA (NINDS) VOGEL, MICHAEL (NIMH) ROSSI, ANDREW (NIMH)
Acknowledgements • Original Inspiration and Development Gully Burns (USC) Dave Newman (UC Irvine) Bruce Herr (Indiana) Katy Borner (Indiana) • Topic Modeling Dave Newman (UC Irvine) Hanna Wallach (UMass) David Mimno (UMass) Andrew McCallum (UMass) • Map and User Interface Design Bruce Herr (Chalklabs) Gavin LaRowe (Chalklabs) Nathan Skiba (Chalklabs) • Advice and Assistance Many many people
Machine Learned Topics vs. NIH Study Sections
Machine Learned Topics vs. NIH Study Sections
Somatosensory & Chemosensory Systems Study Section Subset Inside the Bounded Region 73 27 14 6 Subset Outside the Bounded Region 123 18 3 2 Topics and clusters reveal research categories within Study Sections that are highly relevant to NIH Institutes
Machine Learned Topics vs. NIH RCDC Categories NIH RCDC Category: Sleep Research - Combined query with individual topics reveals finer grained research categories - Once again, clearly relevant to NIH Institutes
NIH RCDC Category: 196 (29%) Sleep Research 183 (27%) Two prominent clusters account for ~56% of the awards
Research Trend Analysis - Screened for topics that changed over this time period - Biggest “hit”: microRNA - Co-occurring topics 2007 vs. 2009: Cellular/molecular biology vs. Complex physiology, Cancer biomarkers
Topic Representation Within the Database Associated title words and document phrases give extra lexical information Co-occurring and similar topics give surrounding concept space Associated document metadata determined post-hoc by mutual information scoring Full grant list ranked by topic allocation allows determination of threshold for tagging accuracy
Topic Evaluation A: Good Topic Word Co-Occurrence Score Good (94.3%) Topic Size (% total) Intermediate (3.4%) Poor (2.3%) A B B: Poor Topic
Grant Similarity vs. Layout Proximity Initiating Grant: Topic Mix of Initiating Grant: Title : Structure and a: Regulation of the GPCR- b: G Protein Interactions in the Visual System c: 100 Most Similar Grants: b: Photo- a: receptor Cells GPCR Signaling c: Protein Structure Clusters correspond to the Similar grants are not necessarily proximal topics of the initiating grant on the graph, instead they are clustered
Document Retrieval Performance - Retrieval Performance: Graph Proximity vs. Document Similarity Values - For large document sets (n = 100-300), graph performance is comparable to similarity scores, which are the inputs Most Similar - This is # grants in all the Closest on Graph previous examples - Graph adds information: documents are clustered
Topic word assignments are sensitive to the contexts in which the words occur Topics that include the word “play” Documents that contain the word “play” Document 1 – “play” > Topic 77 > [ music ] Topic 77 Topic 82 Topic 166 Document 2 – “play” > Topic 82 > [ literature ] Document 3 – “play” > Topic 166 > [ game ] Topics are mixtures of words, each Each instance of a word is assigned to with an associated probability, a specific topic, depending on which are learned from word co- assignments of other words in the occurrence within documents. document.
Recommend
























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.