Statistical Modelling under Epistemic Data Imprecision Some Results on Estimating Multinomial Distributions and Logistic Regression for Coarse Categorical Data Julia Plass*, Thomas Augustin*, Marco Cattaneo**, Georg Schollmeyer* *Department of Statistics, Ludwigs-Maximilians University and **Department of Mathematics, University of Hull & 21 st of July 2015 1 / 8
Our working group 2 / 8
Our working group Julia Plass research interests: Georg Schollmeyer Marco Cattaneo survey statistics Talk on Thursday Thomas Augustin University of Hull deficient data 2 / 8
Epistemic vs. ontic interpretation (Couso, Dubois, S´ anchez, 2014) Epistemic imprecision: Ontic imprecision: “Imprecise observation of “Precise observation of something precise” something imprecise” OBSERVABLE LATENT or Coarsening or or = or = or = or or = ⇒ Truth is hidden due to the underlying ⇒ Truth is represented by coarse coarsening mechanism observation 3 / 8
Examples of data under epistemic imprecision Epistemic imprecision: Examples: Matched data sets “Imprecise observation of with partially something precise” overlapping variables Coarsening as OBSERVABLE LATENT anonymization technique or Missing data as Coarsening or special case or = or or = Here: PASS-data Ω Y = { <, ≥ , na } ⇒ Truth is hidden due to the underlying “ < 1000”, “ ≥ 1000” and “ < 1000 e or ≥ 1000 e ”(na) coarsening mechanism 4 / 8
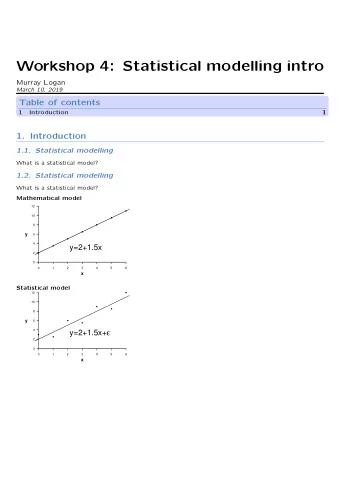
Already existing approaches Still common to enforce Relative bias of π ^ A if CAR is assumed ( π A =0.6) 0.9 precise results 0.8 abs. value coarsening param. 2 0.7 0.6 ⇒ Biased results: 0.6 0.4 0.2 0.5 0.4 sign 0.3 − + 0.2 0.1 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 coarsening param. 1 Variety of set-valued approaches via random sets using Bayesian approaches (e.g. Nguyen, 2006) (de Cooman, Zaffalon, 2004) via likelihood-based belief via profile likelihood function (Denœux, 2014) (Cattaneo, Wiencierz, 2012) Here: Likelihood-based approach influenced by methodology of partial identification (Manski, 2003) coarse categorical data only 5 / 8
Basic idea for the i.i.d. case (regression cf. poster) OBSERVABLE LATENT Observation model Q Y latent variable Y coarse data error-freeness Main goal: coarsening mechanism Estimation of π ij = P ( Y i = j ) p Y i = P ( Y i = Y i ) , i = 1 , . . . , n q Y | y = P ( Y = Y | Y = y ) π i 1 = π 1 , . . . , π iK = π K Use the connection between p and γ Use random-set perspective and determine γ = ( q T Y | y , π T y ) T Φ( γ ) = p ˆ maximum-likelihood estimator p Y Likelihood for parameters p = ( p 1 , . . . , p | Ω Y |− 1 ) T n Y � Y ∈ Ω Y p and the invariance of the likelihood L ( p ) ∝ is uniquely maximized by Y � n { y } under parameter transformations, i.e.: � Y ∋ y n Y � π y ∈ ˆ p Y = n Y n , ˆ n , Y ∈ { 1 , . . ., | Ω Y | − 1 } n ˆ � � n Y p | Ω Y | = 1 − � | Ω Y |− 1 q Y | y ∈ ˆ 0 , Γ = { γ | Φ( γ ) = ˆ p } and thus ˆ p m . ˆ n { y } + n Y m =1 6 / 8
Basic idea for the i.i.d. case (regression cf. poster) OBSERVABLE LATENT Observation model Q Y latent variable Y coarse data error-freeness Main goal: coarsening mechanism Estimation of π ij = P ( Y i = j ) p Y i = P ( Y i = Y i ) , i = 1 , . . . , n q Y | y = P ( Y = Y | Y = y ) π i 1 = π 1 , . . . , π iK = π K Use the connection between p and γ Use random-set perspective and determine γ = ( q T Y | y , π T y ) T Φ( γ ) = p p Y ˆ maximum-likelihood estimator Likelihood for parameters p = ( p 1 , . . . , p | Ω Y |− 1 ) T n Y � Y ∈ Ω Y p is uniquely maximized by and the invariance of the likelihood L ( p ) ∝ Y � n { y } under parameter transformations, i.e.: � Y ∋ y n Y � p Y = n Y π y ∈ ˆ n , ˆ n , Y ∈ { 1 , . . ., | Ω Y | − 1 } n ˆ � n Y � p | Ω Y | = 1 − � | Ω Y |− 1 Γ = { γ | Φ( γ ) = ˆ q Y | y ∈ ˆ 0 , and thus ˆ p m . ˆ p } n { y } + n Y m =1 6 / 8
Basic idea for the i.i.d. case (regression cf. poster) OBSERVABLE LATENT Observation model Q Y latent variable Y coarse data error-freeness Main goal: coarsening mechanism Estimation of π ij = P ( Y i = j ) p Y i = P ( Y i = Y i ) , i = 1 , . . . , n q Y | y = P ( Y = Y | Y = y ) π i 1 = π 1 , . . . , π iK = π K Use the connection between p and γ Use random-set perspective and determine γ = ( q T Y | y , π T y ) T Φ( γ ) = p ˆ p Y maximum-likelihood estimator Likelihood for parameters p = ( p 1 , . . . , p | Ω Y |− 1 ) T n Y � L ( p ) ∝ Y ∈ Ω Y p is uniquely maximized by and the invariance of the likelihood Y � n { y } under parameter transformations, i.e.: � Y ∋ y n Y � p Y = n Y π y ∈ ˆ n , ˆ Y ∈ { 1 , . . ., | Ω Y | − 1 } n , n ˆ � n Y � p | Ω Y | = 1 − � | Ω Y |− 1 Γ = { γ | Φ( γ ) = ˆ p } q Y | y ∈ ˆ 0 , and thus ˆ p m . ˆ n { y } + n Y m =1 6 / 8
Basic idea for the i.i.d. case (regression cf. poster) OBSERVABLE LATENT Observation model Q Y latent variable coarse data Y error-freeness Main goal: coarsening mechanism Estimation of π ij = P ( Y i = j ) p Y i = P ( Y i = Y i ) , i = 1 , . . . , n q Y | y = P ( Y = Y | Y = y ) π i 1 = π 1 , . . . , π iK = π K Use the connection between p and γ Use random-set perspective and determine γ = ( q T Y | y , π T y ) T Φ( γ ) = p p Y ˆ maximum-likelihood estimator Likelihood for parameters p = ( p 1 , . . . , p | Ω Y |− 1 ) T n Y � Y ∈ Ω Y p and the invariance of the likelihood L ( p ) ∝ is uniquely maximized by Y � n { y } under parameter transformations, i.e.: � Y ∋ y n Y � p Y = n Y π y ∈ ˆ n , ˆ n , Y ∈ { 1 , . . ., | Ω Y | − 1 } n ˆ � � n Y p | Ω Y | = 1 − � | Ω Y |− 1 q Y | y ∈ ˆ 0 , and thus ˆ p m . ˆ Γ = { γ | Φ( γ ) = ˆ p } n { y } + n Y m =1 6 / 8
Basic idea for the i.i.d. case (regression cf. poster) OBSERVABLE LATENT Observation model Q Y latent variable Y coarse data error-freeness Main goal: coarsening mechanism Estimation of π ij = P ( Y i = j ) p Y i = P ( Y i = Y i ) , i = 1 , . . . , n q Y | y = P ( Y = Y | Y = y ) π i 1 = π 1 , . . . , π iK = π K Use the connection between p and γ Use random-set perspective and determine γ = ( q T Y | y , π T y ) T Φ( γ ) = p ˆ p Y maximum-likelihood estimator Likelihood for parameters p = ( p 1 , . . . , p | Ω Y |− 1 ) T n Y � Y ∈ Ω Y p and the invariance of the likelihood L ( p ) ∝ is uniquely maximized by Y � n { y } under parameter transformations, i.e.: � Y ∋ y n Y � p Y = n Y π y ∈ ˆ n , ˆ n , Y ∈ { 1 , . . ., | Ω Y | − 1 } n ˆ � � n Y p | Ω Y | = 1 − � | Ω Y |− 1 q Y | y ∈ ˆ 0 , and thus ˆ p m . ˆ Γ = { γ | Φ( γ ) = ˆ p } n { y } + n Y m =1 6 / 8
Basic idea for the i.i.d. case (regression cf. poster) OBSERVABLE LATENT Observation model Q Y latent variable coarse data Y error-freeness Main goal: coarsening mechanism Estimation of π ij = P ( Y i = j ) p Y i = P ( Y i = Y i ) , i = 1 , . . . , n q Y | y = P ( Y = Y | Y = y ) π i 1 = π 1 , . . . , π iK = π K Use the connection between p and γ Use random-set perspective and determine γ = ( q T Y | y , π T y ) T Φ( γ ) = p p Y ˆ maximum-likelihood estimator Likelihood for parameters p = ( p 1 , . . . , p | Ω Y |− 1 ) T n Y � Y ∈ Ω Y p and the invariance of the likelihood L ( p ) ∝ is uniquely maximized by Y � n { y } under parameter transformations, i.e.: � Y ∋ y n Y � π y ∈ ˆ p Y = n Y n , ˆ Y ∈ { 1 , . . ., | Ω Y | − 1 } n , n ˆ � � n Y p | Ω Y | = 1 − � | Ω Y |− 1 Γ = { γ | Φ( γ ) = ˆ p } q Y | y ∈ ˆ 0 , and thus ˆ p m . ˆ n { y } + n Y m =1 6 / 8
Basic idea for the i.i.d. case (regression cf. poster) OBSERVABLE LATENT Observation model Q Y latent variable coarse data Y error-freeness Main goal: coarsening mechanism Estimation of π ij = P ( Y i = j ) p Y i = P ( Y i = Y i ) , i = 1 , . . . , n q Y | y = P ( Y = Y | Y = y ) π i 1 = π 1 , . . . , π iK = π K Use the connection between p and γ Use random-set perspective and determine γ = ( q T Y | y , π T y ) T Φ( γ ) = p ˆ p Y maximum-likelihood estimator Likelihood for parameters p = ( p 1 , . . . , p | Ω Y |− 1 ) T n Y � Y ∈ Ω Y p L ( p ) ∝ is uniquely maximized by and the invariance of the likelihood Y � n { y } under parameter transformations, i.e.: � Y ∋ y n Y � p Y = n Y ˆ π y ∈ n , ˆ n , Y ∈ { 1 , . . ., | Ω Y | − 1 } n ˆ � n Y � p | Ω Y | = 1 − � | Ω Y |− 1 q Y | y ∈ ˆ 0 , and thus ˆ ˆ p m . Γ = { γ | Φ( γ ) = ˆ p } n { y } + n Y m =1 Illustration (PASS data) n < = 238 , n ≥ = 835 , n na = 338 � 238 ˆ π < ∈ 238+338 � 1411 , 1411 6 / 8
Reliable incorporation of auxiliary information Starting from point-identifying assumptions, we use sensitivity parameters to allow inclusion of partial knowledge. Assumption about exact value 1 q na |≥ of R = q na | < (Nordheim, 1984): e.g. Q specified by R=1 , R=4 na |≥ where R=1 corresponds to CAR (Heitjan, Rubin, 1991). q 0 1 q na | < 7 / 8
Recommend
More recommend
Unleash a World of Digital Possibilities—Browse, Share, and Explore Content Without Boundaries