
Sparse regression DS-GA 1013 / MATH-GA 2824 Mathematical Tools for - PowerPoint PPT Presentation
Sparse regression DS-GA 1013 / MATH-GA 2824 Mathematical Tools for Data Science https://cims.nyu.edu/~cfgranda/pages/MTDS_spring20/index.html Carlos Fernandez-Granda Sparse regression Linear regression is challenging when the number of features
Sparse regression DS-GA 1013 / MATH-GA 2824 Mathematical Tools for Data Science https://cims.nyu.edu/~cfgranda/pages/MTDS_spring20/index.html Carlos Fernandez-Granda
Sparse regression Linear regression is challenging when the number of features p is large Solution: Select subset of features I ⊂ { 1 , . . . , p } , such that � y ≈ β [ i ] x [ i ] i ∈I Equivalently, find sparse coefficient vector β ∈ R p such that y ≈ � x , β � Problem: How to promote sparsity?
Toy problem Find t such that t v t := t − 1 t − 1 is sparse Equivalently, find arg min t || v t || 0
ℓ 0 “norm" Number of nonzero entries in a vector Not a norm! || 2 x || 0 = || x || 0 � = 2 || x || 0
Toy problem || v t || 0 3 2 . 5 2 1 . 5 1 − 0 . 4 − 0 . 2 0 0 . 2 0 . 4 0 . 6 0 . 8 1 1 . 2 1 . 4 t
Alternative strategy Minimize another norm f ( t ) := || v t ||
Toy problem 5 || v t || 0 || v t || 1 4 || v t || 2 || v t || ∞ 3 2 1 − 0 . 4 − 0 . 2 0 0 . 2 0 . 4 0 . 6 0 . 8 1 1 . 2 1 . 4 t
The lasso Convexity Subgradients Analysis of the lasso estimator for a simple example
Sparse linear regression Find a small subset of useful features Model selection problem Two objectives: � 2 ◮ Good fit to the data; � �� � X T β − y � �� 2 should be as small as possible ◮ Using a small number of features; β should be as sparse as possible
The lasso Uses ℓ 1 -norm regularization to promote sparse coefficients 1 2 � � � � � y − X T β β lasso := arg min 2 + λ || β || 1 � � � � 2 � � � β
Temperature prediction via linear regression ◮ Dataset of hourly temperatures measured at weather stations all over the US ◮ Goal: Predict temperature in Jamestown (North Dakota) from other temperatures ◮ Response: Temperature in Jamestown ◮ Features: Temperatures in 133 other stations ( p = 133) in 2015 ◮ Test set: 10 3 measurements ◮ Additional test set: All measurements from 2016
Ridge regression n := 135 1.5 WolfPoint, MT Aberdeen, SD 1.0 Buffalo, SD 0.5 Coefficients 0.0 0.5 1.0 1.5 10 1 10 0 10 1 10 2 10 3 10 4 10 5 10 6 Regularization parameter ( / n )
Lasso n := 135 0.75 WolfPoint, MT Aberdeen, SD 0.50 Buffalo, SD 0.25 Coefficients 0.00 0.25 0.50 0.75 1.00 5 4 1 10 1 10 10 10 3 10 2 10 10 0 10 2 Regularization parameter ( / n )
Lasso n := 135 12 Average error (deg Celsius) 10 8 6 4 2 Training error Validation error 0 10 5 10 4 10 3 10 2 10 1 10 0 10 1 10 2 Regularization parameter ( )
Lasso n := 135 Regularization parameter ( ) 10 2 10 3 10 4 10 5 10 2 10 3 10 4 Number of training data (n)
Ridge-regression coefficients 0.6 0.4 0.2 Coefficients 0.0 0.2 WolfPoint, MT 0.4 Aberdeen, SD Buffalo, SD 0.6 10 2 10 3 10 4 Number of training data
Lasso coefficients 0.6 0.4 0.2 Coefficients 0.0 0.2 WolfPoint, MT 0.4 Aberdeen, SD Buffalo, SD 0.6 10 2 10 3 10 4 Number of training data
Results Training error (RR) 3.0 Test error (RR) Test error 2016 (RR) Average error (deg Celsius) Training error (lasso) 2.5 Test error (lasso) Test error 2016 (lasso) 2.0 1.5 1.0 10 2 10 3 10 4 Number of training data
The lasso Convexity Subgradients Analysis of the lasso estimator for a simple example
Convex functions A function f : R n → R is convex if for any x , y ∈ R n and any θ ∈ ( 0 , 1 ) θ f ( x ) + ( 1 − θ ) f ( y ) ≥ f ( θ x + ( 1 − θ ) y )
Convex functions f ( y ) θ f ( x ) + ( 1 − θ ) f ( y ) f ( θ x + ( 1 − θ ) y ) f ( x )
Strictly convex functions A function f : R n → R is strictly convex if for any x , y ∈ R n and any θ ∈ ( 0 , 1 ) θ f ( x ) + ( 1 − θ ) f ( y ) > f ( θ x + ( 1 − θ ) y )
Linear and quadratic functions Linear functions are convex f ( θ x + ( 1 − θ ) y ) = θ f ( x ) + ( 1 − θ ) f ( y ) Positive definite quadratic forms are strictly convex
Norms are convex For any x , y ∈ R n and any θ ∈ ( 0 , 1 ) || θ x + ( 1 − θ ) y || ≤ || θ x || + || ( 1 − θ ) y || = θ || x || + ( 1 − θ ) || y ||
ℓ 0 “norm" is not convex Let x := ( 1 0 ) and y := ( 0 1 ) , for any θ ∈ ( 0 , 1 ) || θ x + ( 1 − θ ) y || 0 = 2 θ || x || 0 + ( 1 − θ ) || y || 0 = 1
Is the lasso cost function convex? f strictly convex, g convex, h := f + λ g ? h ( θ x + ( 1 − θ ) y ) = f ( θ x + ( 1 − θ ) y ) + λ g ( θ x + ( 1 − θ ) y ) < θ f ( x ) + ( 1 − θ ) f ( y ) + λθ g ( x ) + λ ( 1 − θ ) g ( y ) = θ h ( x ) + ( 1 − θ ) h ( y )
Lasso cost function is convex Sum of convex functions is convex If at least one is strictly convex, then sum is strictly convex Scaling by a positive factor preserves convexity Lasso cost function is convex!
Local minima are global Any local minimum of a convex function is also a global minimum
Strictly convex functions Strictly convex functions have at most one global minimum Proof: Assume two minima exist at x � = y with value v min f ( 0 . 5 x + 0 . 5 y ) < 0 . 5 f ( x ) + 0 . 5 f ( y ) = v min
The lasso Convexity Subgradients Analysis of the lasso estimator for a simple example
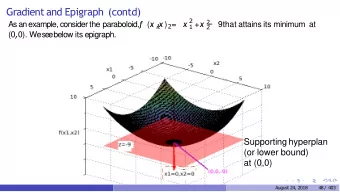
Epigraph The epigraph of f : R n → R is x [ 1 ] ≤ x [ n + 1 ] epi ( f ) := x | f · · · x [ n ]
Epigraph epi ( f ) f
Supporting hyperplane A hyperplane H is a supporting hyperplane of a set S at x if ◮ H and S intersect at x ◮ S is contained in one of the half-spaces bounded by H
Supporting hyperplane
Subgradient A function f : R n → R is convex if and only if it has a supporting hyperplane at every point It is strictly convex if and only for all x ∈ R n it only intersects with the supporting hyperplane at one point
Subgradients The subgradient of f : R n → R at x ∈ R n is a vector g ∈ R n such that f ( y ) ≥ f ( x ) + g T ( y − x ) , for all y ∈ R n The hyperplane y [ 1 ] y | y [ n + 1 ] = g T H g := · · · y [ n ] is a supporting hyperplane of the epigraph at x The set of all subgradients at x is called the subdifferential
Subgradients
Subgradient of differentiable function If a function is differentiable, the only subgradient at each point is the gradient
Proof Assume g is a subgradient at x , for any α ≥ 0 f ( x + α e i ) ≥ f ( x ) + g T α e i = f ( x ) + g [ i ] α f ( x ) ≤ f ( x − α e i ) + g T α e i = f ( x − α e i ) + g [ i ] α Combining both inequalities f ( x ) − f ( x − α e i ) ≤ g [ i ] ≤ f ( x + α e i ) − f ( x ) α α Letting α → 0, implies g [ i ] = ∂ f ( x ) ∂ x [ i ]
Optimality condition for nondifferentiable functions x is a minimum of f if and only if the zero vector is a subgradient of f at x 0 T ( y − x ) f ( y ) ≥ f ( x ) + � = f ( x ) for all y ∈ R n Under strict convexity the minimum is unique
Sum of subgradients Let g 1 and g 2 be subgradients at x ∈ R n of f 1 : R n → R and f 2 : R n → R g := g 1 + g 2 is a subgradient of f := f 1 + f 2 at x Proof: For any y ∈ R n f ( y ) = f 1 ( y ) + f 2 ( y ) ≥ f 1 ( x ) + g T 1 ( y − x ) + f 2 ( y ) + g T 2 ( y − x ) ≥ f ( x ) + g T ( y − x )
Subgradient of scaled function Let g 1 be a subgradient at x ∈ R n of f 1 : R n → R For any α ≥ 0 g 2 := α g 1 is a subgradient of f 2 := α f 1 at x Proof: For any y ∈ R n f 2 ( y ) = α f 1 ( y ) � � f 1 ( x ) + g T ≥ α 1 ( y − x ) ≥ f 2 ( x ) + g T 2 ( y − x )
Subdifferential of absolute value At x � = 0, f ( x ) = | x | is differentiable, so g = sign ( x ) At x = 0, we need f ( 0 + y ) ≥ f ( 0 ) + g ( y − 0 ) | y | ≥ gy Holds if and only if | g | ≤ 1
Subdifferential of absolute value f ( x ) = | x |
Subdifferential of ℓ 1 norm g is a subgradient of the ℓ 1 norm at x ∈ R n if and only if g [ i ] = sign ( x [ i ]) if x [ i ] � = 0 | g [ i ] | ≤ 1 if x [ i ] = 0
Proof (one direction) Assume g [ i ] is a subgradient of |·| at | x [ i ] | for 1 ≤ i ≤ n For any y ∈ R n n � || y || 1 = | y [ i ] | i = 1 n � ≥ | x [ i ] | + g [ i ] ( y [ i ] − x [ i ]) i = 1 = || x || 1 + g T ( y − x )
Subdifferential of ℓ 1 norm
Subdifferential of ℓ 1 norm
Subdifferential of ℓ 1 norm
The lasso Convexity Subgradients Analysis of the lasso estimator for a simple example
Additive model y train := X T β true + ˜ ˜ z train Goal: Gain intuition about why the lasso promotes sparse solutions
Decomposition of lasso cost function y train − X T β � 2 arg min β � ˜ 2 + λ || β || 1 β ( β − β true ) T XX T ( β − β true )+ λ || β || 1 − 2 ˜ z T train X T β = arg min
Sparse regression with two features One true feature y := x true + ˜ ˜ z We fit a model using an additional feature � T � X := x true x other � 1 � β true := 0
( β − β true ) T XX T ( β − β true ) 0 . 8 2.00 0 . 1.00 0 . 6 5 0 0 . 4 0.25 0 . 2 β true β [2] 0 . 0 0.01 2.00 1.00 0.50 − 0 . 2 0.10 0.10 − 0 . 4 4.00 − 0 . 6 − 0 . 8 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 1 . 2 1 . 4 β [1]
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.