
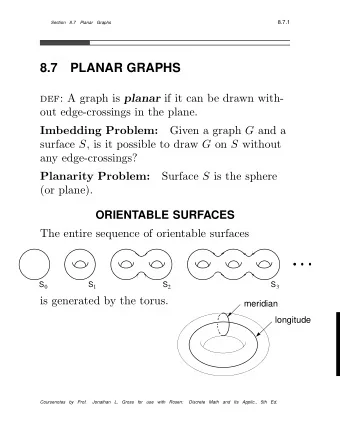
Sieve weights and their smoothings Dimitris Koukoulopoulos 1 Joint - PowerPoint PPT Presentation
Sieve weights and their smoothings Dimitris Koukoulopoulos 1 Joint work with Andrew Granville 1,2 and James Maynard 3 1 Universit de Montral 2 University College London 3 University of Oxford Oberwolfach, 10 November 2016 Selbergs sieve 2
Sieve weights and their smoothings Dimitris Koukoulopoulos 1 Joint work with Andrew Granville 1,2 and James Maynard 3 1 Université de Montréal 2 University College London 3 University of Oxford Oberwolfach, 10 November 2016
Selberg’s sieve 2 � � µ ( d ) ≤ λ d , d | ( a , m ) d | ( a , m ) for any λ d ∈ R with λ 1 = 1.
Selberg’s sieve 2 � � µ ( d ) ≤ λ d , d | ( a , m ) d | ( a , m ) for any λ d ∈ R with λ 1 = 1. Minimize quadratic form 2 � � � λ d = λ d 1 λ d 2 · # { a ∈ A : D | a } . a ∈A d | ( a , m ) d 1 , d 2 | m D =[ d 1 , d 2 ]
Selberg’s sieve 2 � � µ ( d ) ≤ λ d , d | ( a , m ) d | ( a , m ) for any λ d ∈ R with λ 1 = 1. Minimize quadratic form 2 � � � λ d = λ d 1 λ d 2 · # { a ∈ A : D | a } . a ∈A d | ( a , m ) d 1 , d 2 | m D =[ d 1 , d 2 ] Assume λ d supported on d ≤ R , so D ≤ R 2 .
Selberg’s sieve 2 � � µ ( d ) ≤ λ d , d | ( a , m ) d | ( a , m ) for any λ d ∈ R with λ 1 = 1. Minimize quadratic form 2 � � � λ d = λ d 1 λ d 2 · # { a ∈ A : D | a } . a ∈A d | ( a , m ) d 1 , d 2 | m D =[ d 1 , d 2 ] Assume λ d supported on d ≤ R , so D ≤ R 2 . Optimizing (making assumptions on A ) yields � κ � log ( R / d ) λ d ≈ c · µ ( d ) · · 1 d ≤ R , κ = sieve dimension log R
Selberg’s sieve weights & beyond � κ � log ( R / d ) λ d ≈ c · µ ( d ) · · 1 d ≤ R , κ = sieve dimension log R Weights λ d decay smoothly to 0, with ‘smoothness degree’ increasing with κ .
Selberg’s sieve weights & beyond � κ � log ( R / d ) λ d ≈ c · µ ( d ) · · 1 d ≤ R , κ = sieve dimension log R Weights λ d decay smoothly to 0, with ‘smoothness degree’ increasing with κ . More generally, consider � log d � � M f ( n ; R ) = µ ( d ) f , log R d | n supp ( f ) ⊂ ( −∞ , 1 ] , f ( 0 ) = 1.
Selberg’s sieve weights & beyond � κ � log ( R / d ) λ d ≈ c · µ ( d ) · · 1 d ≤ R , κ = sieve dimension log R Weights λ d decay smoothly to 0, with ‘smoothness degree’ increasing with κ . More generally, consider � log d � � M f ( n ; R ) = µ ( d ) f , log R d | n supp ( f ) ⊂ ( −∞ , 1 ] , f ( 0 ) = 1. M f ( n ; R ) should behave like a sieve weight for f sufficiently smooth, i.e. x M f ( n ; R ) 2 ≍ � � log R ≍ 1 . n ≤ x n ≤ x p | n ⇒ p > R
Selberg’s sieve weights & beyond � κ � log ( R / d ) λ d ≈ c · µ ( d ) · · 1 d ≤ R , κ = sieve dimension log R Weights λ d decay smoothly to 0, with ‘smoothness degree’ increasing with κ . More generally, consider � log d � � M f ( n ; R ) = µ ( d ) f , log R d | n supp ( f ) ⊂ ( −∞ , 1 ] , f ( 0 ) = 1. M f ( n ; R ) should behave like a sieve weight for f sufficiently smooth, i.e. x M f ( n ; R ) 2 ≍ � � log R ≍ 1 . n ≤ x n ≤ x p | n ⇒ p > R Maynard and Tao used k -dimensional generalization of M f ( n ; R ) to detect small gaps between primes.
To smooth or not to smooth? � log d � � M f ( n ; R ) = µ ( d ) f , supp ( f ) ⊂ ( −∞ , 1 ] . log R d | n Is this a sieve weight when f is not smooth?
To smooth or not to smooth? � log d � � M f ( n ; R ) = µ ( d ) f , supp ( f ) ⊂ ( −∞ , 1 ] . log R d | n Is this a sieve weight when f is not smooth? If n = 2 m , 2 ∤ m , then � � � µ ( d ) = µ ( d ) + µ ( 2 d ) d | n , d ≤ R d | m , d ≤ R d | m , 2 d ≤ R
To smooth or not to smooth? � log d � � M f ( n ; R ) = µ ( d ) f , supp ( f ) ⊂ ( −∞ , 1 ] . log R d | n Is this a sieve weight when f is not smooth? If n = 2 m , 2 ∤ m , then � � � µ ( d ) = µ ( d ) + µ ( 2 d ) d | n , d ≤ R d | m , d ≤ R d | m , 2 d ≤ R � = µ ( d ) . d | m , R / 2 < d ≤ R
To smooth or not to smooth? � log d � � M f ( n ; R ) = µ ( d ) f , supp ( f ) ⊂ ( −∞ , 1 ] . log R d | n Is this a sieve weight when f is not smooth? If n = 2 m , 2 ∤ m , then � � � µ ( d ) = µ ( d ) + µ ( 2 d ) d | n , d ≤ R d | m , d ≤ R d | m , 2 d ≤ R � = µ ( d ) . d | m , R / 2 < d ≤ R # { n ≤ x : ∃ ! d ∈ ( R / 2 , R ] , d | n } ≍ x ( log R ) − δ ( log log R ) − 3 / 2 , Ford: where δ ≈ 0 . 086 < 1, i.e. � d | m , d ≤ R µ ( d ) � = 0 too often.
How much to smooth? For f ∈ C 1 ( R ) , n = p v m with p ∤ m , � log d � � log ( pd ) � � � M f ( n ; R ) = µ ( d ) f + µ ( pd ) f log R log R d | m d | m
How much to smooth? For f ∈ C 1 ( R ) , n = p v m with p ∤ m , � log d � � log ( pd ) � � � M f ( n ; R ) = µ ( d ) f + µ ( pd ) f log R log R d | m d | m log p � � u + log d � log R � µ ( d ) f ′ = − d u . log R 0 d | m
How much to smooth? For f ∈ C 1 ( R ) , n = p v m with p ∤ m , � log d � � log ( pd ) � � � M f ( n ; R ) = µ ( d ) f + µ ( pd ) f log R log R d | m d | m log p � � u + log d � log R � µ ( d ) f ′ = − d u . log R 0 d | m For f ∈ C A ( R ) , n = p v 1 1 · · · p v A A m with p 1 , . . . , p A ∤ m , � A log p 1 log pA � � � u a + log d log R log R � � M f ( n ; R ) = ( − 1 ) A µ ( d ) f ( A ) · · · d u log R 0 0 d | m a = 1
How much to smooth? For f ∈ C 1 ( R ) , n = p v m with p ∤ m , � log d � � log ( pd ) � � � M f ( n ; R ) = µ ( d ) f + µ ( pd ) f log R log R d | m d | m log p � � u + log d � log R � µ ( d ) f ′ = − d u . log R 0 d | m For f ∈ C A ( R ) , n = p v 1 1 · · · p v A A m with p 1 , . . . , p A ∤ m , � A log p 1 log pA � � � u a + log d log R log R � � M f ( n ; R ) = ( − 1 ) A µ ( d ) f ( A ) · · · d u log R 0 0 d | m a = 1 A log p a � ⇒ M f ( n ; R ) � M f ( A ) ( m ; R ) log R . a = 1
How much to smooth? For f ∈ C A ( R ) , n = p v 1 1 · · · p v A A m with p 1 , . . . , p A ∤ m , A log p a � M f ( n ; R ) � M f ( A ) ( m ; R ) log R . a = 1
How much to smooth? For f ∈ C A ( R ) , n = p v 1 1 · · · p v A A m with p 1 , . . . , p A ∤ m , A log p a � M f ( n ; R ) � M f ( A ) ( m ; R ) log R . a = 1 � d | n , d ≤ R µ ( d )) 2 k � � n ≤ x ( � x M f ( n ; R ) 2 k � max � Guess : log R , ( log R ) 2 kA n ≤ x
How much to smooth? For f ∈ C A ( R ) , n = p v 1 1 · · · p v A A m with p 1 , . . . , p A ∤ m , A log p a � M f ( n ; R ) � M f ( A ) ( m ; R ) log R . a = 1 � d | n , d ≤ R µ ( d )) 2 k � � n ≤ x ( � x M f ( n ; R ) 2 k � max � Guess : log R , ( log R ) 2 kA n ≤ x d | n , d ≤ R µ ( d )) 2 k ∼ c k x ( log R ) E k , then we would need If � n ≤ x ( � A > E k / 2 k for M f ( n ; R ) 2 k to act as a sieve weight.
Theorem (Granville, K., Maynard (201?)) Let k , A ∈ N . Assume that: d | n , d ≤ R µ ( d )) 2 k ∼ c k x ( log R ) E k when x / R 2 k → ∞ ; • � n ≤ x ( � • f ∈ C A ( R ) , supp ( f ) ⊂ ( −∞ , 1 ] , f , f ′ , . . . , f ( A ) unif. bounded.
Theorem (Granville, K., Maynard (201?)) Let k , A ∈ N . Assume that: d | n , d ≤ R µ ( d )) 2 k ∼ c k x ( log R ) E k when x / R 2 k → ∞ ; • � n ≤ x ( � • f ∈ C A ( R ) , supp ( f ) ⊂ ( −∞ , 1 ] , f , f ′ , . . . , f ( A ) unif. bounded. (a) If A > E k / 2 k + 1 , then η 3 / 2 x M f ( n ; R ) 2 k ≪ f , k , A � • ( x ≥ R ≥ 2 ) log R n ≤ x ∃ p | n , p ≤ R η
Theorem (Granville, K., Maynard (201?)) Let k , A ∈ N . Assume that: d | n , d ≤ R µ ( d )) 2 k ∼ c k x ( log R ) E k when x / R 2 k → ∞ ; • � n ≤ x ( � • f ∈ C A ( R ) , supp ( f ) ⊂ ( −∞ , 1 ] , f , f ′ , . . . , f ( A ) unif. bounded. (a) If A > E k / 2 k + 1 , then η 3 / 2 x M f ( n ; R ) 2 k ≪ f , k , A � • ( x ≥ R ≥ 2 ) log R n ≤ x ∃ p | n , p ≤ R η M f ( n ; R ) 2 k = c k , f x � x � � ( x ≥ R 2 k + ǫ ) • log R + O f , k , A ( log R ) 3 / 2 n ≤ x
Theorem (Granville, K., Maynard (201?)) Let k , A ∈ N . Assume that: d | n , d ≤ R µ ( d )) 2 k ∼ c k x ( log R ) E k when x / R 2 k → ∞ ; • � n ≤ x ( � • f ∈ C A ( R ) , supp ( f ) ⊂ ( −∞ , 1 ] , f , f ′ , . . . , f ( A ) unif. bounded. (a) If A > E k / 2 k + 1 , then η 3 / 2 x M f ( n ; R ) 2 k ≪ f , k , A � • ( x ≥ R ≥ 2 ) log R n ≤ x ∃ p | n , p ≤ R η M f ( n ; R ) 2 k = c k , f x � x � � ( x ≥ R 2 k + ǫ ) • log R + O f , k , A ( log R ) 3 / 2 n ≤ x (b) If A ≤ E k / 2 k + 1 and x ≥ R ≥ 2 , then n ≤ x M f ( n ; R ) 2 k ≪ x ( log R ) E k − 2 k ( A − 1 ) . � Dominant contribution when # { p | n : p ≤ R } ∼ ( E k + 2 k ) log log R.
The exponent E k � 2 k � ( x / R 2 k → ∞ ) . � � ∼ c k x ( log R ) E k µ ( d ) n ≤ x d | n , d ≤ R
The exponent E k � 2 k � ( x / R 2 k → ∞ ) . � � ∼ c k x ( log R ) E k µ ( d ) n ≤ x d | n , d ≤ R Dress, Iwaniec, Tenenbaum (1983): E 1 = 0
The exponent E k � 2 k � ( x / R 2 k → ∞ ) . � � ∼ c k x ( log R ) E k µ ( d ) n ≤ x d | n , d ≤ R Dress, Iwaniec, Tenenbaum (1983): E 1 = 0 Motohashi (2004): E 2 = 2
Recommend






















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.