
Sequential Data Oliver Schulte - CMPT 726 Bishop PRML Ch. 13 - PowerPoint PPT Presentation
Hidden Markov Models Inference for HMMs Learning for HMMs Sequential Data Oliver Schulte - CMPT 726 Bishop PRML Ch. 13 Russell and Norvig, AIMA Hidden Markov Models Inference for HMMs Learning for HMMs Outline Hidden Markov Models
Hidden Markov Models Inference for HMMs Learning for HMMs Sequential Data Oliver Schulte - CMPT 726 Bishop PRML Ch. 13 Russell and Norvig, AIMA
Hidden Markov Models Inference for HMMs Learning for HMMs Outline Hidden Markov Models Inference for HMMs Learning for HMMs
Hidden Markov Models Inference for HMMs Learning for HMMs Outline Hidden Markov Models Inference for HMMs Learning for HMMs
Hidden Markov Models Inference for HMMs Learning for HMMs Temporal Models • The world changes over time • Explicitly model this change using Bayesian networks • Undirected models also exist (will not cover) • Basic idea: copy state and evidence variables for each time step • e.g. Diabetes management • z t is set of unobservable state variables at time t • bloodSugar t , stomachContents t , ... • x t is set of observable evidence variables at time t • measuredBloodSugar t , foodEaten t , ... • Assume discrete time step, fixed • Notation: x a : b = x a , x a + 1 , . . . , x b − 1 , x b
Hidden Markov Models Inference for HMMs Learning for HMMs Markov Chain • Construct Bayesian network from these variables • parents? distributions? for state variables z t :
Hidden Markov Models Inference for HMMs Learning for HMMs Markov Chain • Construct Bayesian network from these variables • parents? distributions? for state variables z t : • Markov assumption: z t depends on bounded subset of z 1 : t − 1 • First-order Markov process: p ( z t | z 1 : t − 1 ) = p ( z t | z t − 1 ) • Second-order Markov process: p ( z t | z 1 : t − 1 ) = p ( z t | z t − 2 , z t − 1 ) x 1 x 2 x 3 x 4 x 1 x 2 x 3 x 4 • Stationary process: p ( z t | z t − 1 ) fixed for all t
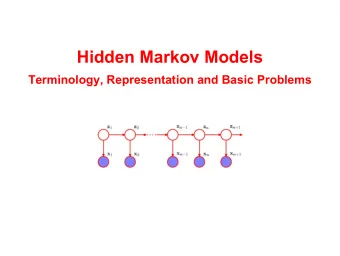
Hidden Markov Models Inference for HMMs Learning for HMMs Hidden Markov Model (HMM) • Sensor Markov assumption: p ( x t | z 1 : t , x 1 : t − 1 ) = p ( x t | z t ) • Stationary process: transition model p ( z t | z t − 1 ) and sensor model p ( x t | z t ) fixed for all t (separate p ( z 1 ) ) • HMM special type of Bayesian network, z t is a single discrete random variable: z n − 1 z n +1 z 1 z 2 z n x 1 x 2 x n − 1 x n x n +1 • Joint distribution: p ( z 1 : t , x 1 : t ) =
Hidden Markov Models Inference for HMMs Learning for HMMs Hidden Markov Model (HMM) • Sensor Markov assumption: p ( x t | z 1 : t , x 1 : t − 1 ) = p ( x t | z t ) • Stationary process: transition model p ( z t | z t − 1 ) and sensor model p ( x t | z t ) fixed for all t (separate p ( z 1 ) ) • HMM special type of Bayesian network, z t is a single discrete random variable: z n − 1 z n +1 z 1 z 2 z n x 1 x 2 x n − 1 x n x n +1 • Joint distribution: p ( z 1 : t , x 1 : t ) = p ( z 1 ) � i = 2 : t p ( z i | z i − 1 ) � i = 1 : t p ( x i | z i )
Hidden Markov Models Inference for HMMs Learning for HMMs HMM Example R t � 1 P(R ) t t 0.7 f 0.3 Rain t � 1 Rain Rain t +1 t R P(U ) t t t 0.9 f 0.2 Umbrella t � 1 Umbrella Umbrella t +1 t • First-order Markov assumption not true in real world • Possible fixes: • Increase order of Markov process • Augment state, add temp t , pressure t
Hidden Markov Models Inference for HMMs Learning for HMMs Generating Data with HMMs 1 1 0.5 0.5 �✂✁☎✄ �✝✁✟✞ �✂✁☎✆ 0 0 0 0.5 1 0 0.5 1 • z with 3 latent states, 2 dimensional observation x . • left: contour map of emission probabilities. • right: sample of 50 points.
Hidden Markov Models Inference for HMMs Learning for HMMs Generating Sequences with HMMs • Data are pen trajectory as it is writing the digit. • Train HMM on 45 handwritten digits. • Use HMM to randomly generate 2s.
Hidden Markov Models Inference for HMMs Learning for HMMs Transition Diagram A 22 A 21 A 12 k = 2 A 32 A 23 A 11 k = 1 k = 3 A 31 A 13 A 33 • z n takes one of 3 values • Using one-of- K coding scheme, z nk = 1 if in state k at time n • Transition matrix A where p ( z nk = 1 | z n − 1 , j = 1 ) = A jk
Hidden Markov Models Inference for HMMs Learning for HMMs Lattice / Trellis Representation A 11 A 11 A 11 k = 1 k = 2 k = 3 A 33 A 33 A 33 n − 2 n − 1 n n + 1 • The lattice or trellis representation shows possible paths through the latent state variables z n
Hidden Markov Models Inference for HMMs Learning for HMMs Applications, Pros and Cons HMMs are widely applied. For example: • Speech recognition • Part-of-Speech tagging (e.g., John hit Mary -> NP VP NP). • Gene sequence modelling. Pros • Conceptually simple. • With small number of states, computationally tractable. Cons • Black box, states may not have interpretation. • Complexity grows exponentially in number of states: trade-off between expressiveness and complexity.
Hidden Markov Models Inference for HMMs Learning for HMMs Outline Hidden Markov Models Inference for HMMs Learning for HMMs
Hidden Markov Models Inference for HMMs Learning for HMMs Inference Tasks • Filtering: p ( z t | x 1 : t ) • Estimate current unobservable state given all observations to date • Prediction: p ( z k | x 1 : t ) for k > t • Similar to filtering, without evidence • Smoothing: p ( z k | x 1 : t ) for k < t • Better estimate of past states • Most likely explanation: arg max z 1 : t p ( z 1 : t | x 1 : t ) • e.g. speech recognition, decoding noisy input sequence
Hidden Markov Models Inference for HMMs Learning for HMMs Filtering • Aim: devise a recursive state estimation algorithm: p ( z t + 1 | x 1 : t + 1 ) = f ( x t + 1 , p ( z t | x 1 : t )) p ( z t + 1 | x 1 : t + 1 ) = p ( z t + 1 | x 1 : t , x t + 1 ) ∝ p ( x t + 1 | x 1 : t , z t + 1 ) p ( z t + 1 | x 1 : t ) = p ( x t + 1 | z t + 1 ) p ( z t + 1 | x 1 : t ) • I.e. prediction + estimation. Prediction by summing out z t : � p ( z t + 1 | x 1 : t + 1 ) ∝ p ( x t + 1 | z t + 1 ) p ( z t + 1 , z t | x 1 : t ) z t � = p ( x t + 1 | z t + 1 ) p ( z t + 1 | z t , x 1 : t ) p ( z t | x 1 : t ) z t � = p ( x t + 1 | z t + 1 ) p ( z t + 1 | z t ) p ( z t | x 1 : t ) z t
Hidden Markov Models Inference for HMMs Learning for HMMs Filtering • Aim: devise a recursive state estimation algorithm: p ( z t + 1 | x 1 : t + 1 ) = f ( x t + 1 , p ( z t | x 1 : t )) p ( z t + 1 | x 1 : t + 1 ) = p ( z t + 1 | x 1 : t , x t + 1 ) ∝ p ( x t + 1 | x 1 : t , z t + 1 ) p ( z t + 1 | x 1 : t ) = p ( x t + 1 | z t + 1 ) p ( z t + 1 | x 1 : t ) • I.e. prediction + estimation. Prediction by summing out z t : � p ( z t + 1 | x 1 : t + 1 ) ∝ p ( x t + 1 | z t + 1 ) p ( z t + 1 , z t | x 1 : t ) z t � = p ( x t + 1 | z t + 1 ) p ( z t + 1 | z t , x 1 : t ) p ( z t | x 1 : t ) z t � = p ( x t + 1 | z t + 1 ) p ( z t + 1 | z t ) p ( z t | x 1 : t ) z t
Hidden Markov Models Inference for HMMs Learning for HMMs Filtering • Aim: devise a recursive state estimation algorithm: p ( z t + 1 | x 1 : t + 1 ) = f ( x t + 1 , p ( z t | x 1 : t )) p ( z t + 1 | x 1 : t + 1 ) = p ( z t + 1 | x 1 : t , x t + 1 ) ∝ p ( x t + 1 | x 1 : t , z t + 1 ) p ( z t + 1 | x 1 : t ) = p ( x t + 1 | z t + 1 ) p ( z t + 1 | x 1 : t ) • I.e. prediction + estimation. Prediction by summing out z t : � p ( z t + 1 | x 1 : t + 1 ) ∝ p ( x t + 1 | z t + 1 ) p ( z t + 1 , z t | x 1 : t ) z t � = p ( x t + 1 | z t + 1 ) p ( z t + 1 | z t , x 1 : t ) p ( z t | x 1 : t ) z t � = p ( x t + 1 | z t + 1 ) p ( z t + 1 | z t ) p ( z t | x 1 : t ) z t
Hidden Markov Models Inference for HMMs Learning for HMMs Filtering Example P ( R t ) P ( U t ) R t − 1 R t t 0.7 t 0.9 f 0.3 f 0.2 p ( rain 1 = true ) = 0 . 5 p ( z t + 1 | x 1 : t + 1 ) ∝ p ( x t + 1 | z t + 1 ) � z t p ( z t + 1 | z t ) p ( z t | x 1 : t )
Hidden Markov Models Inference for HMMs Learning for HMMs Filtering - Lattice α ( z n − 1 , 1 ) α ( z n, 1 ) A 11 k = 1 A 21 p ( x n | z n, 1 ) α ( z n − 1 , 2 ) k = 2 A 31 α ( z n − 1 , 3 ) k = 3 n − 1 n • Using notation in PRML, forward message is α ( z n ) , updated probability of time- n state. • Compute α ( z n , i ) using sum over k of α ( z n − 1 , k ) multiplied by A ki , then multiplying in evidence p ( x t | z ni ) • Each step, computing α ( z n ) takes O ( K 2 ) time, with K values for z n
Hidden Markov Models Inference for HMMs Learning for HMMs Smoothing z 1 z 2 z n − 1 z n z n +1 x n − 1 x n +1 x 1 x 2 x n • Divide evidence x 1 : t into x 1 : n − 1 , x n : t . • Intuitively: what is probability of getting to a state by time n − 1 given the previous observations, and what is the probability of continuing with the future observations? p ( z n − 1 | x 1 : t ) = p ( z n − 1 | x 1 : n − 1 , x n : t ) ∝ p ( z n − 1 | x 1 : n − 1 ) p ( x n : t | z n − 1 , x 1 : n − 1 ) = p ( z n − 1 | x 1 : n − 1 ) p ( x n : t | z n − 1 ) ≡ α ( z n − 1 ) β ( z n − 1 ) • Backwards message β ( z n − 1 ) another recursion:
Recommend





















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.