
Self-Monitoring and Assumptions Self-Adapting Systems Performance - PowerPoint PPT Presentation
Self-Monitoring and Assumptions Self-Adapting Systems Performance is important. People do not really know how to tune applications and systems. V E R I It would be nice to get some help from the system in tuning. T A S
What do we do with Data? Off-line Analysis • Off-line Analysis • Use data from measurement thread to construct time series usage profile. • Monitors long-term behavior. • Conduct variance analysis. • Identifies common usage profiles. • Detects uncommon usage. • Construct predicted usage profiles. • Suggests thresholds to online system. • Determine resource thresholds from • Conducts feasibility evaluations. predicted profiles. • Online Analysis • Notify online system of thresholds. • Monitor instantaneous resource utilization. • Evaluate traces and logs; derive new • Maintain efficiency statistics. algorithms. • Detect dangerous conditions. • Simulate new algorithms, in situ. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Online Analysis Adaptation Heuristics • Receive threshold and variance • Goal: decrease application latency. information from off-line system. • Paging • Maintain dynamic statistics about: • Collect page access trace. • Cache hit rates. • Look for well-known patterns (linear, cyclic, strided). • Lock contention. • Look for page access correlation. • Disk queue lengths. • Install better prefetching algorithm. • Load averages. • Disk Wait • Context switch rates. • Similar process to paging. • Detect abnormal behavior. • Replace read-ahead for the application(s). • Dynamically trigger trace generation. • CPU Hogs • Examine profile output. • Trigger adaptation heuristics. • Recompile kernel modules in application context. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Adaptation (continued) Conclusions • Interrupt Latency • Self-monitoring is a generally useful idea. • Measure latency between interrupt arrival and delivery to process/thread. • An extensible system just makes it • Look for excessively long intervals or high variance. easier. • Check (fix) scheduling priorities. • Automatic adaptation is a cool idea. • Lock Contention • Challenging to do it correctly. • Measure lock wait times. • An extensible system makes it easier to • Decrease lock granularity on highly contested items. experiment with this. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Self-Monitoring and Assumptions Self-Adapting Systems • Performance is important. • People do not really know how to tune applications and systems. V E R I • It would be nice to get some help from the system in tuning. T A S • Self-monitoring systems gather information about their own Margo I. Seltzer performance. Harvard University Division of Engineering and Applied Sciences Self-Monitoring and Self-Adaptation Outline Self-Monitoring in VINO • Self-Monitoring in VINO. • Measurement thread periodically collects module statistics. • Processing monitor data. • Generate detailed profiling information. • Adapting to system behavior. • Capture module inputs ( traces ) and • Conclusions. outputs ( logs ). • In-situ simulation evaluates competing algorithms and policies. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Measurement Thread Generating Traces and Logs incoming requests measurement output data thread (graft) get_stats graft points Buffer Cache other other file lock txn systems other systems other system system system systems systems outputs VINO kernel Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Generating Traces and Logs In-Situ Simulation incoming requests pass parameters incoming requests to simulator and record real parameters pass- through Buffer Cache Buffer Cache Buffer Cache Simulator outputs simulation results outputs Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
What do we do with Data? Off-line Analysis • Off-line Analysis • Use data from measurement thread to construct time series usage profile. • Monitors long-term behavior. • Conduct variance analysis. • Identifies common usage profiles. • Detects uncommon usage. • Construct predicted usage profiles. • Suggests thresholds to online system. • Determine resource thresholds from • Conducts feasibility evaluations. predicted profiles. • Online Analysis • Notify online system of thresholds. • Monitor instantaneous resource utilization. • Evaluate traces and logs; derive new • Maintain efficiency statistics. algorithms. • Detect dangerous conditions. • Simulate new algorithms, in situ. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Online Analysis Adaptation Heuristics • Receive threshold and variance • Goal: decrease application latency. information from off-line system. • Paging • Maintain dynamic statistics about: • Collect page access trace. • Cache hit rates. • Look for well-known patterns (linear, cyclic, strided). • Lock contention. • Look for page access correlation. • Disk queue lengths. • Install better prefetching algorithm. • Load averages. • Disk Wait • Context switch rates. • Similar process to paging. • Detect abnormal behavior. • Replace read-ahead for the application(s). • Dynamically trigger trace generation. • CPU Hogs • Examine profile output. • Trigger adaptation heuristics. • Recompile kernel modules in application context. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Adaptation (continued) Conclusions • Interrupt Latency • Self-monitoring is a generally useful idea. • Measure latency between interrupt arrival and delivery to process/thread. • An extensible system just makes it • Look for excessively long intervals or high variance. easier. • Check (fix) scheduling priorities. • Automatic adaptation is a cool idea. • Lock Contention • Challenging to do it correctly. • Measure lock wait times. • An extensible system makes it easier to • Decrease lock granularity on highly contested items. experiment with this. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Self-Monitoring and Assumptions Self-Adapting Systems • Performance is important. • People do not really know how to tune applications and systems. V E R I • It would be nice to get some help from the system in tuning. T A S • Self-monitoring systems gather information about their own Margo I. Seltzer performance. Harvard University Division of Engineering and Applied Sciences Self-Monitoring and Self-Adaptation Outline Self-Monitoring in VINO • Self-Monitoring in VINO. • Measurement thread periodically collects module statistics. • Processing monitor data. • Generate detailed profiling information. • Adapting to system behavior. • Capture module inputs ( traces ) and • Conclusions. outputs ( logs ). • In-situ simulation evaluates competing algorithms and policies. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Measurement Thread Generating Traces and Logs incoming requests measurement output data thread (graft) get_stats graft points Buffer Cache other other file lock txn systems other systems other system system system systems systems outputs VINO kernel Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Generating Traces and Logs In-Situ Simulation incoming requests pass parameters incoming requests to simulator and record real parameters pass- through Buffer Cache Buffer Cache Buffer Cache Simulator outputs simulation results outputs Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
What do we do with Data? Off-line Analysis • Off-line Analysis • Use data from measurement thread to construct time series usage profile. • Monitors long-term behavior. • Conduct variance analysis. • Identifies common usage profiles. • Detects uncommon usage. • Construct predicted usage profiles. • Suggests thresholds to online system. • Determine resource thresholds from • Conducts feasibility evaluations. predicted profiles. • Online Analysis • Notify online system of thresholds. • Monitor instantaneous resource utilization. • Evaluate traces and logs; derive new • Maintain efficiency statistics. algorithms. • Detect dangerous conditions. • Simulate new algorithms, in situ. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Online Analysis Adaptation Heuristics • Receive threshold and variance • Goal: decrease application latency. information from off-line system. • Paging • Maintain dynamic statistics about: • Collect page access trace. • Cache hit rates. • Look for well-known patterns (linear, cyclic, strided). • Lock contention. • Look for page access correlation. • Disk queue lengths. • Install better prefetching algorithm. • Load averages. • Disk Wait • Context switch rates. • Similar process to paging. • Detect abnormal behavior. • Replace read-ahead for the application(s). • Dynamically trigger trace generation. • CPU Hogs • Examine profile output. • Trigger adaptation heuristics. • Recompile kernel modules in application context. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Adaptation (continued) Conclusions • Interrupt Latency • Self-monitoring is a generally useful idea. • Measure latency between interrupt arrival and delivery to process/thread. • An extensible system just makes it • Look for excessively long intervals or high variance. easier. • Check (fix) scheduling priorities. • Automatic adaptation is a cool idea. • Lock Contention • Challenging to do it correctly. • Measure lock wait times. • An extensible system makes it easier to • Decrease lock granularity on highly contested items. experiment with this. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Self-Monitoring and Assumptions Self-Adapting Systems • Performance is important. • People do not really know how to tune applications and systems. V E R I • It would be nice to get some help from the system in tuning. T A S • Self-monitoring systems gather information about their own Margo I. Seltzer performance. Harvard University Division of Engineering and Applied Sciences Self-Monitoring and Self-Adaptation Outline Self-Monitoring in VINO • Self-Monitoring in VINO. • Measurement thread periodically collects module statistics. • Processing monitor data. • Generate detailed profiling information. • Adapting to system behavior. • Capture module inputs ( traces ) and • Conclusions. outputs ( logs ). • In-situ simulation evaluates competing algorithms and policies. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Measurement Thread Generating Traces and Logs incoming requests measurement output data thread (graft) get_stats graft points Buffer Cache other other file lock txn systems other systems other system system system systems systems outputs VINO kernel Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Generating Traces and Logs In-Situ Simulation incoming requests pass parameters incoming requests to simulator and record real parameters pass- through Buffer Cache Buffer Cache Buffer Cache Simulator outputs simulation results outputs Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
What do we do with Data? Off-line Analysis • Off-line Analysis • Use data from measurement thread to construct time series usage profile. • Monitors long-term behavior. • Conduct variance analysis. • Identifies common usage profiles. • Detects uncommon usage. • Construct predicted usage profiles. • Suggests thresholds to online system. • Determine resource thresholds from • Conducts feasibility evaluations. predicted profiles. • Online Analysis • Notify online system of thresholds. • Monitor instantaneous resource utilization. • Evaluate traces and logs; derive new • Maintain efficiency statistics. algorithms. • Detect dangerous conditions. • Simulate new algorithms, in situ. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Online Analysis Adaptation Heuristics • Receive threshold and variance • Goal: decrease application latency. information from off-line system. • Paging • Maintain dynamic statistics about: • Collect page access trace. • Cache hit rates. • Look for well-known patterns (linear, cyclic, strided). • Lock contention. • Look for page access correlation. • Disk queue lengths. • Install better prefetching algorithm. • Load averages. • Disk Wait • Context switch rates. • Similar process to paging. • Detect abnormal behavior. • Replace read-ahead for the application(s). • Dynamically trigger trace generation. • CPU Hogs • Examine profile output. • Trigger adaptation heuristics. • Recompile kernel modules in application context. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Adaptation (continued) Conclusions • Interrupt Latency • Self-monitoring is a generally useful idea. • Measure latency between interrupt arrival and delivery to process/thread. • An extensible system just makes it • Look for excessively long intervals or high variance. easier. • Check (fix) scheduling priorities. • Automatic adaptation is a cool idea. • Lock Contention • Challenging to do it correctly. • Measure lock wait times. • An extensible system makes it easier to • Decrease lock granularity on highly contested items. experiment with this. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Self-Monitoring and Assumptions Self-Adapting Systems • Performance is important. • People do not really know how to tune applications and systems. V E R I • It would be nice to get some help from the system in tuning. T A S • Self-monitoring systems gather information about their own Margo I. Seltzer performance. Harvard University Division of Engineering and Applied Sciences Self-Monitoring and Self-Adaptation Outline Self-Monitoring in VINO • Self-Monitoring in VINO. • Measurement thread periodically collects module statistics. • Processing monitor data. • Generate detailed profiling information. • Adapting to system behavior. • Capture module inputs ( traces ) and • Conclusions. outputs ( logs ). • In-situ simulation evaluates competing algorithms and policies. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Measurement Thread Generating Traces and Logs incoming requests measurement output data thread (graft) get_stats graft points Buffer Cache other other file lock txn systems other systems other system system system systems systems outputs VINO kernel Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Generating Traces and Logs In-Situ Simulation incoming requests pass parameters incoming requests to simulator and record real parameters pass- through Buffer Cache Buffer Cache Buffer Cache Simulator outputs simulation results outputs Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
What do we do with Data? Off-line Analysis • Off-line Analysis • Use data from measurement thread to construct time series usage profile. • Monitors long-term behavior. • Conduct variance analysis. • Identifies common usage profiles. • Detects uncommon usage. • Construct predicted usage profiles. • Suggests thresholds to online system. • Determine resource thresholds from • Conducts feasibility evaluations. predicted profiles. • Online Analysis • Notify online system of thresholds. • Monitor instantaneous resource utilization. • Evaluate traces and logs; derive new • Maintain efficiency statistics. algorithms. • Detect dangerous conditions. • Simulate new algorithms, in situ. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Online Analysis Adaptation Heuristics • Receive threshold and variance • Goal: decrease application latency. information from off-line system. • Paging • Maintain dynamic statistics about: • Collect page access trace. • Cache hit rates. • Look for well-known patterns (linear, cyclic, strided). • Lock contention. • Look for page access correlation. • Disk queue lengths. • Install better prefetching algorithm. • Load averages. • Disk Wait • Context switch rates. • Similar process to paging. • Detect abnormal behavior. • Replace read-ahead for the application(s). • Dynamically trigger trace generation. • CPU Hogs • Examine profile output. • Trigger adaptation heuristics. • Recompile kernel modules in application context. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Adaptation (continued) Conclusions • Interrupt Latency • Self-monitoring is a generally useful idea. • Measure latency between interrupt arrival and delivery to process/thread. • An extensible system just makes it • Look for excessively long intervals or high variance. easier. • Check (fix) scheduling priorities. • Automatic adaptation is a cool idea. • Lock Contention • Challenging to do it correctly. • Measure lock wait times. • An extensible system makes it easier to • Decrease lock granularity on highly contested items. experiment with this. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Self-Monitoring and Assumptions Self-Adapting Systems • Performance is important. • People do not really know how to tune applications and systems. V E R I • It would be nice to get some help from the system in tuning. T A S • Self-monitoring systems gather information about their own Margo I. Seltzer performance. Harvard University Division of Engineering and Applied Sciences Self-Monitoring and Self-Adaptation Outline Self-Monitoring in VINO • Self-Monitoring in VINO. • Measurement thread periodically collects module statistics. • Processing monitor data. • Generate detailed profiling information. • Adapting to system behavior. • Capture module inputs ( traces ) and • Conclusions. outputs ( logs ). • In-situ simulation evaluates competing algorithms and policies. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Measurement Thread Generating Traces and Logs incoming requests measurement output data thread (graft) get_stats graft points Buffer Cache other other file lock txn systems other systems other system system system systems systems outputs VINO kernel Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Generating Traces and Logs In-Situ Simulation incoming requests pass parameters incoming requests to simulator and record real parameters pass- through Buffer Cache Buffer Cache Buffer Cache Simulator outputs simulation results outputs Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
What do we do with Data? Off-line Analysis • Off-line Analysis • Use data from measurement thread to construct time series usage profile. • Monitors long-term behavior. • Conduct variance analysis. • Identifies common usage profiles. • Detects uncommon usage. • Construct predicted usage profiles. • Suggests thresholds to online system. • Determine resource thresholds from • Conducts feasibility evaluations. predicted profiles. • Online Analysis • Notify online system of thresholds. • Monitor instantaneous resource utilization. • Evaluate traces and logs; derive new • Maintain efficiency statistics. algorithms. • Detect dangerous conditions. • Simulate new algorithms, in situ. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Online Analysis Adaptation Heuristics • Receive threshold and variance • Goal: decrease application latency. information from off-line system. • Paging • Maintain dynamic statistics about: • Collect page access trace. • Cache hit rates. • Look for well-known patterns (linear, cyclic, strided). • Lock contention. • Look for page access correlation. • Disk queue lengths. • Install better prefetching algorithm. • Load averages. • Disk Wait • Context switch rates. • Similar process to paging. • Detect abnormal behavior. • Replace read-ahead for the application(s). • Dynamically trigger trace generation. • CPU Hogs • Examine profile output. • Trigger adaptation heuristics. • Recompile kernel modules in application context. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Adaptation (continued) Conclusions • Interrupt Latency • Self-monitoring is a generally useful idea. • Measure latency between interrupt arrival and delivery to process/thread. • An extensible system just makes it • Look for excessively long intervals or high variance. easier. • Check (fix) scheduling priorities. • Automatic adaptation is a cool idea. • Lock Contention • Challenging to do it correctly. • Measure lock wait times. • An extensible system makes it easier to • Decrease lock granularity on highly contested items. experiment with this. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Self-Monitoring and Assumptions Self-Adapting Systems • Performance is important. • People do not really know how to tune applications and systems. V E R I • It would be nice to get some help from the system in tuning. T A S • Self-monitoring systems gather information about their own Margo I. Seltzer performance. Harvard University Division of Engineering and Applied Sciences Self-Monitoring and Self-Adaptation Outline Self-Monitoring in VINO • Self-Monitoring in VINO. • Measurement thread periodically collects module statistics. • Processing monitor data. • Generate detailed profiling information. • Adapting to system behavior. • Capture module inputs ( traces ) and • Conclusions. outputs ( logs ). • In-situ simulation evaluates competing algorithms and policies. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Measurement Thread Generating Traces and Logs incoming requests measurement output data thread (graft) get_stats graft points Buffer Cache other other file lock txn systems other systems other system system system systems systems outputs VINO kernel Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Generating Traces and Logs In-Situ Simulation incoming requests pass parameters incoming requests to simulator and record real parameters pass- through Buffer Cache Buffer Cache Buffer Cache Simulator outputs simulation results outputs Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
What do we do with Data? Off-line Analysis • Off-line Analysis • Use data from measurement thread to construct time series usage profile. • Monitors long-term behavior. • Conduct variance analysis. • Identifies common usage profiles. • Detects uncommon usage. • Construct predicted usage profiles. • Suggests thresholds to online system. • Determine resource thresholds from • Conducts feasibility evaluations. predicted profiles. • Online Analysis • Notify online system of thresholds. • Monitor instantaneous resource utilization. • Evaluate traces and logs; derive new • Maintain efficiency statistics. algorithms. • Detect dangerous conditions. • Simulate new algorithms, in situ. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Online Analysis Adaptation Heuristics • Receive threshold and variance • Goal: decrease application latency. information from off-line system. • Paging • Maintain dynamic statistics about: • Collect page access trace. • Cache hit rates. • Look for well-known patterns (linear, cyclic, strided). • Lock contention. • Look for page access correlation. • Disk queue lengths. • Install better prefetching algorithm. • Load averages. • Disk Wait • Context switch rates. • Similar process to paging. • Detect abnormal behavior. • Replace read-ahead for the application(s). • Dynamically trigger trace generation. • CPU Hogs • Examine profile output. • Trigger adaptation heuristics. • Recompile kernel modules in application context. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Adaptation (continued) Conclusions • Interrupt Latency • Self-monitoring is a generally useful idea. • Measure latency between interrupt arrival and delivery to process/thread. • An extensible system just makes it • Look for excessively long intervals or high variance. easier. • Check (fix) scheduling priorities. • Automatic adaptation is a cool idea. • Lock Contention • Challenging to do it correctly. • Measure lock wait times. • An extensible system makes it easier to • Decrease lock granularity on highly contested items. experiment with this. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Self-Monitoring and Assumptions Self-Adapting Systems • Performance is important. • People do not really know how to tune applications and systems. V E R I • It would be nice to get some help from the system in tuning. T A S • Self-monitoring systems gather information about their own Margo I. Seltzer performance. Harvard University Division of Engineering and Applied Sciences Self-Monitoring and Self-Adaptation Outline Self-Monitoring in VINO • Self-Monitoring in VINO. • Measurement thread periodically collects module statistics. • Processing monitor data. • Generate detailed profiling information. • Adapting to system behavior. • Capture module inputs ( traces ) and • Conclusions. outputs ( logs ). • In-situ simulation evaluates competing algorithms and policies. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Measurement Thread Generating Traces and Logs incoming requests measurement output data thread (graft) get_stats graft points Buffer Cache other other file lock txn systems other systems other system system system systems systems outputs VINO kernel Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Generating Traces and Logs In-Situ Simulation incoming requests pass parameters incoming requests to simulator and record real parameters pass- through Buffer Cache Buffer Cache Buffer Cache Simulator outputs simulation results outputs Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
What do we do with Data? Off-line Analysis • Off-line Analysis • Use data from measurement thread to construct time series usage profile. • Monitors long-term behavior. • Conduct variance analysis. • Identifies common usage profiles. • Detects uncommon usage. • Construct predicted usage profiles. • Suggests thresholds to online system. • Determine resource thresholds from • Conducts feasibility evaluations. predicted profiles. • Online Analysis • Notify online system of thresholds. • Monitor instantaneous resource utilization. • Evaluate traces and logs; derive new • Maintain efficiency statistics. algorithms. • Detect dangerous conditions. • Simulate new algorithms, in situ. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Online Analysis Adaptation Heuristics • Receive threshold and variance • Goal: decrease application latency. information from off-line system. • Paging • Maintain dynamic statistics about: • Collect page access trace. • Cache hit rates. • Look for well-known patterns (linear, cyclic, strided). • Lock contention. • Look for page access correlation. • Disk queue lengths. • Install better prefetching algorithm. • Load averages. • Disk Wait • Context switch rates. • Similar process to paging. • Detect abnormal behavior. • Replace read-ahead for the application(s). • Dynamically trigger trace generation. • CPU Hogs • Examine profile output. • Trigger adaptation heuristics. • Recompile kernel modules in application context. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Adaptation (continued) Conclusions • Interrupt Latency • Self-monitoring is a generally useful idea. • Measure latency between interrupt arrival and delivery to process/thread. • An extensible system just makes it • Look for excessively long intervals or high variance. easier. • Check (fix) scheduling priorities. • Automatic adaptation is a cool idea. • Lock Contention • Challenging to do it correctly. • Measure lock wait times. • An extensible system makes it easier to • Decrease lock granularity on highly contested items. experiment with this. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Self-Monitoring and Assumptions Self-Adapting Systems • Performance is important. • People do not really know how to tune applications and systems. V E R I • It would be nice to get some help from the system in tuning. T A S • Self-monitoring systems gather information about their own Margo I. Seltzer performance. Harvard University Division of Engineering and Applied Sciences Self-Monitoring and Self-Adaptation Outline Self-Monitoring in VINO • Self-Monitoring in VINO. • Measurement thread periodically collects module statistics. • Processing monitor data. • Generate detailed profiling information. • Adapting to system behavior. • Capture module inputs ( traces ) and • Conclusions. outputs ( logs ). • In-situ simulation evaluates competing algorithms and policies. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Measurement Thread Generating Traces and Logs incoming requests measurement output data thread (graft) get_stats graft points Buffer Cache other other file lock txn systems other systems other system system system systems systems outputs VINO kernel Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Generating Traces and Logs In-Situ Simulation incoming requests pass parameters incoming requests to simulator and record real parameters pass- through Buffer Cache Buffer Cache Buffer Cache Simulator outputs simulation results outputs Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
What do we do with Data? Off-line Analysis • Off-line Analysis • Use data from measurement thread to construct time series usage profile. • Monitors long-term behavior. • Conduct variance analysis. • Identifies common usage profiles. • Detects uncommon usage. • Construct predicted usage profiles. • Suggests thresholds to online system. • Determine resource thresholds from • Conducts feasibility evaluations. predicted profiles. • Online Analysis • Notify online system of thresholds. • Monitor instantaneous resource utilization. • Evaluate traces and logs; derive new • Maintain efficiency statistics. algorithms. • Detect dangerous conditions. • Simulate new algorithms, in situ. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Online Analysis Adaptation Heuristics • Receive threshold and variance • Goal: decrease application latency. information from off-line system. • Paging • Maintain dynamic statistics about: • Collect page access trace. • Cache hit rates. • Look for well-known patterns (linear, cyclic, strided). • Lock contention. • Look for page access correlation. • Disk queue lengths. • Install better prefetching algorithm. • Load averages. • Disk Wait • Context switch rates. • Similar process to paging. • Detect abnormal behavior. • Replace read-ahead for the application(s). • Dynamically trigger trace generation. • CPU Hogs • Examine profile output. • Trigger adaptation heuristics. • Recompile kernel modules in application context. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Adaptation (continued) Conclusions • Interrupt Latency • Self-monitoring is a generally useful idea. • Measure latency between interrupt arrival and delivery to process/thread. • An extensible system just makes it • Look for excessively long intervals or high variance. easier. • Check (fix) scheduling priorities. • Automatic adaptation is a cool idea. • Lock Contention • Challenging to do it correctly. • Measure lock wait times. • An extensible system makes it easier to • Decrease lock granularity on highly contested items. experiment with this. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Self-Monitoring and Assumptions Self-Adapting Systems • Performance is important. • People do not really know how to tune applications and systems. V E R I • It would be nice to get some help from the system in tuning. T A S • Self-monitoring systems gather information about their own Margo I. Seltzer performance. Harvard University Division of Engineering and Applied Sciences Self-Monitoring and Self-Adaptation Outline Self-Monitoring in VINO • Self-Monitoring in VINO. • Measurement thread periodically collects module statistics. • Processing monitor data. • Generate detailed profiling information. • Adapting to system behavior. • Capture module inputs ( traces ) and • Conclusions. outputs ( logs ). • In-situ simulation evaluates competing algorithms and policies. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Measurement Thread Generating Traces and Logs incoming requests measurement output data thread (graft) get_stats graft points Buffer Cache other other file lock txn systems other systems other system system system systems systems outputs VINO kernel Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Generating Traces and Logs In-Situ Simulation incoming requests pass parameters incoming requests to simulator and record real parameters pass- through Buffer Cache Buffer Cache Buffer Cache Simulator outputs simulation results outputs Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
What do we do with Data? Off-line Analysis • Off-line Analysis • Use data from measurement thread to construct time series usage profile. • Monitors long-term behavior. • Conduct variance analysis. • Identifies common usage profiles. • Detects uncommon usage. • Construct predicted usage profiles. • Suggests thresholds to online system. • Determine resource thresholds from • Conducts feasibility evaluations. predicted profiles. • Online Analysis • Notify online system of thresholds. • Monitor instantaneous resource utilization. • Evaluate traces and logs; derive new • Maintain efficiency statistics. algorithms. • Detect dangerous conditions. • Simulate new algorithms, in situ. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Online Analysis Adaptation Heuristics • Receive threshold and variance • Goal: decrease application latency. information from off-line system. • Paging • Maintain dynamic statistics about: • Collect page access trace. • Cache hit rates. • Look for well-known patterns (linear, cyclic, strided). • Lock contention. • Look for page access correlation. • Disk queue lengths. • Install better prefetching algorithm. • Load averages. • Disk Wait • Context switch rates. • Similar process to paging. • Detect abnormal behavior. • Replace read-ahead for the application(s). • Dynamically trigger trace generation. • CPU Hogs • Examine profile output. • Trigger adaptation heuristics. • Recompile kernel modules in application context. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Adaptation (continued) Conclusions • Interrupt Latency • Self-monitoring is a generally useful idea. • Measure latency between interrupt arrival and delivery to process/thread. • An extensible system just makes it • Look for excessively long intervals or high variance. easier. • Check (fix) scheduling priorities. • Automatic adaptation is a cool idea. • Lock Contention • Challenging to do it correctly. • Measure lock wait times. • An extensible system makes it easier to • Decrease lock granularity on highly contested items. experiment with this. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Self-Monitoring and Assumptions Self-Adapting Systems • Performance is important. • People do not really know how to tune applications and systems. V E R I • It would be nice to get some help from the system in tuning. T A S • Self-monitoring systems gather information about their own Margo I. Seltzer performance. Harvard University Division of Engineering and Applied Sciences Self-Monitoring and Self-Adaptation Outline Self-Monitoring in VINO • Self-Monitoring in VINO. • Measurement thread periodically collects module statistics. • Processing monitor data. • Generate detailed profiling information. • Adapting to system behavior. • Capture module inputs ( traces ) and • Conclusions. outputs ( logs ). • In-situ simulation evaluates competing algorithms and policies. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Measurement Thread Generating Traces and Logs incoming requests measurement output data thread (graft) get_stats graft points Buffer Cache other other file lock txn systems other systems other system system system systems systems outputs VINO kernel Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Generating Traces and Logs In-Situ Simulation incoming requests pass parameters incoming requests to simulator and record real parameters pass- through Buffer Cache Buffer Cache Buffer Cache Simulator outputs simulation results outputs Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
What do we do with Data? Off-line Analysis • Off-line Analysis • Use data from measurement thread to construct time series usage profile. • Monitors long-term behavior. • Conduct variance analysis. • Identifies common usage profiles. • Detects uncommon usage. • Construct predicted usage profiles. • Suggests thresholds to online system. • Determine resource thresholds from • Conducts feasibility evaluations. predicted profiles. • Online Analysis • Notify online system of thresholds. • Monitor instantaneous resource utilization. • Evaluate traces and logs; derive new • Maintain efficiency statistics. algorithms. • Detect dangerous conditions. • Simulate new algorithms, in situ. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Online Analysis Adaptation Heuristics • Receive threshold and variance • Goal: decrease application latency. information from off-line system. • Paging • Maintain dynamic statistics about: • Collect page access trace. • Cache hit rates. • Look for well-known patterns (linear, cyclic, strided). • Lock contention. • Look for page access correlation. • Disk queue lengths. • Install better prefetching algorithm. • Load averages. • Disk Wait • Context switch rates. • Similar process to paging. • Detect abnormal behavior. • Replace read-ahead for the application(s). • Dynamically trigger trace generation. • CPU Hogs • Examine profile output. • Trigger adaptation heuristics. • Recompile kernel modules in application context. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Adaptation (continued) Conclusions • Interrupt Latency • Self-monitoring is a generally useful idea. • Measure latency between interrupt arrival and delivery to process/thread. • An extensible system just makes it • Look for excessively long intervals or high variance. easier. • Check (fix) scheduling priorities. • Automatic adaptation is a cool idea. • Lock Contention • Challenging to do it correctly. • Measure lock wait times. • An extensible system makes it easier to • Decrease lock granularity on highly contested items. experiment with this. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Self-Monitoring and Assumptions Self-Adapting Systems • Performance is important. • People do not really know how to tune applications and systems. V E R I • It would be nice to get some help from the system in tuning. T A S • Self-monitoring systems gather information about their own Margo I. Seltzer performance. Harvard University Division of Engineering and Applied Sciences Self-Monitoring and Self-Adaptation Outline Self-Monitoring in VINO • Self-Monitoring in VINO. • Measurement thread periodically collects module statistics. • Processing monitor data. • Generate detailed profiling information. • Adapting to system behavior. • Capture module inputs ( traces ) and • Conclusions. outputs ( logs ). • In-situ simulation evaluates competing algorithms and policies. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Measurement Thread Generating Traces and Logs incoming requests measurement output data thread (graft) get_stats graft points Buffer Cache other other file lock txn systems other systems other system system system systems systems outputs VINO kernel Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Generating Traces and Logs In-Situ Simulation incoming requests pass parameters incoming requests to simulator and record real parameters pass- through Buffer Cache Buffer Cache Buffer Cache Simulator outputs simulation results outputs Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
What do we do with Data? Off-line Analysis • Off-line Analysis • Use data from measurement thread to construct time series usage profile. • Monitors long-term behavior. • Conduct variance analysis. • Identifies common usage profiles. • Detects uncommon usage. • Construct predicted usage profiles. • Suggests thresholds to online system. • Determine resource thresholds from • Conducts feasibility evaluations. predicted profiles. • Online Analysis • Notify online system of thresholds. • Monitor instantaneous resource utilization. • Evaluate traces and logs; derive new • Maintain efficiency statistics. algorithms. • Detect dangerous conditions. • Simulate new algorithms, in situ. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Online Analysis Adaptation Heuristics • Receive threshold and variance • Goal: decrease application latency. information from off-line system. • Paging • Maintain dynamic statistics about: • Collect page access trace. • Cache hit rates. • Look for well-known patterns (linear, cyclic, strided). • Lock contention. • Look for page access correlation. • Disk queue lengths. • Install better prefetching algorithm. • Load averages. • Disk Wait • Context switch rates. • Similar process to paging. • Detect abnormal behavior. • Replace read-ahead for the application(s). • Dynamically trigger trace generation. • CPU Hogs • Examine profile output. • Trigger adaptation heuristics. • Recompile kernel modules in application context. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Adaptation (continued) Conclusions • Interrupt Latency • Self-monitoring is a generally useful idea. • Measure latency between interrupt arrival and delivery to process/thread. • An extensible system just makes it • Look for excessively long intervals or high variance. easier. • Check (fix) scheduling priorities. • Automatic adaptation is a cool idea. • Lock Contention • Challenging to do it correctly. • Measure lock wait times. • An extensible system makes it easier to • Decrease lock granularity on highly contested items. experiment with this. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Self-Monitoring and Assumptions Self-Adapting Systems • Performance is important. • People do not really know how to tune applications and systems. V E R I • It would be nice to get some help from the system in tuning. T A S • Self-monitoring systems gather information about their own Margo I. Seltzer performance. Harvard University Division of Engineering and Applied Sciences Self-Monitoring and Self-Adaptation Outline Self-Monitoring in VINO • Self-Monitoring in VINO. • Measurement thread periodically collects module statistics. • Processing monitor data. • Generate detailed profiling information. • Adapting to system behavior. • Capture module inputs ( traces ) and • Conclusions. outputs ( logs ). • In-situ simulation evaluates competing algorithms and policies. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Measurement Thread Generating Traces and Logs incoming requests measurement output data thread (graft) get_stats graft points Buffer Cache other other file lock txn systems other systems other system system system systems systems outputs VINO kernel Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Generating Traces and Logs In-Situ Simulation incoming requests pass parameters incoming requests to simulator and record real parameters pass- through Buffer Cache Buffer Cache Buffer Cache Simulator outputs simulation results outputs Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
What do we do with Data? Off-line Analysis • Off-line Analysis • Use data from measurement thread to construct time series usage profile. • Monitors long-term behavior. • Conduct variance analysis. • Identifies common usage profiles. • Detects uncommon usage. • Construct predicted usage profiles. • Suggests thresholds to online system. • Determine resource thresholds from • Conducts feasibility evaluations. predicted profiles. • Online Analysis • Notify online system of thresholds. • Monitor instantaneous resource utilization. • Evaluate traces and logs; derive new • Maintain efficiency statistics. algorithms. • Detect dangerous conditions. • Simulate new algorithms, in situ. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Online Analysis Adaptation Heuristics • Receive threshold and variance • Goal: decrease application latency. information from off-line system. • Paging • Maintain dynamic statistics about: • Collect page access trace. • Cache hit rates. • Look for well-known patterns (linear, cyclic, strided). • Lock contention. • Look for page access correlation. • Disk queue lengths. • Install better prefetching algorithm. • Load averages. • Disk Wait • Context switch rates. • Similar process to paging. • Detect abnormal behavior. • Replace read-ahead for the application(s). • Dynamically trigger trace generation. • CPU Hogs • Examine profile output. • Trigger adaptation heuristics. • Recompile kernel modules in application context. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Adaptation (continued) Conclusions • Interrupt Latency • Self-monitoring is a generally useful idea. • Measure latency between interrupt arrival and delivery to process/thread. • An extensible system just makes it • Look for excessively long intervals or high variance. easier. • Check (fix) scheduling priorities. • Automatic adaptation is a cool idea. • Lock Contention • Challenging to do it correctly. • Measure lock wait times. • An extensible system makes it easier to • Decrease lock granularity on highly contested items. experiment with this. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Self-Monitoring and Assumptions Self-Adapting Systems • Performance is important. • People do not really know how to tune applications and systems. V E R I • It would be nice to get some help from the system in tuning. T A S • Self-monitoring systems gather information about their own Margo I. Seltzer performance. Harvard University Division of Engineering and Applied Sciences Self-Monitoring and Self-Adaptation Outline Self-Monitoring in VINO • Self-Monitoring in VINO. • Measurement thread periodically collects module statistics. • Processing monitor data. • Generate detailed profiling information. • Adapting to system behavior. • Capture module inputs ( traces ) and • Conclusions. outputs ( logs ). • In-situ simulation evaluates competing algorithms and policies. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Measurement Thread Generating Traces and Logs incoming requests measurement output data thread (graft) get_stats graft points Buffer Cache other other file lock txn systems other systems other system system system systems systems outputs VINO kernel Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Generating Traces and Logs In-Situ Simulation incoming requests pass parameters incoming requests to simulator and record real parameters pass- through Buffer Cache Buffer Cache Buffer Cache Simulator outputs simulation results outputs Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
What do we do with Data? Off-line Analysis • Off-line Analysis • Use data from measurement thread to construct time series usage profile. • Monitors long-term behavior. • Conduct variance analysis. • Identifies common usage profiles. • Detects uncommon usage. • Construct predicted usage profiles. • Suggests thresholds to online system. • Determine resource thresholds from • Conducts feasibility evaluations. predicted profiles. • Online Analysis • Notify online system of thresholds. • Monitor instantaneous resource utilization. • Evaluate traces and logs; derive new • Maintain efficiency statistics. algorithms. • Detect dangerous conditions. • Simulate new algorithms, in situ. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Online Analysis Adaptation Heuristics • Receive threshold and variance • Goal: decrease application latency. information from off-line system. • Paging • Maintain dynamic statistics about: • Collect page access trace. • Cache hit rates. • Look for well-known patterns (linear, cyclic, strided). • Lock contention. • Look for page access correlation. • Disk queue lengths. • Install better prefetching algorithm. • Load averages. • Disk Wait • Context switch rates. • Similar process to paging. • Detect abnormal behavior. • Replace read-ahead for the application(s). • Dynamically trigger trace generation. • CPU Hogs • Examine profile output. • Trigger adaptation heuristics. • Recompile kernel modules in application context. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Adaptation (continued) Conclusions • Interrupt Latency • Self-monitoring is a generally useful idea. • Measure latency between interrupt arrival and delivery to process/thread. • An extensible system just makes it • Look for excessively long intervals or high variance. easier. • Check (fix) scheduling priorities. • Automatic adaptation is a cool idea. • Lock Contention • Challenging to do it correctly. • Measure lock wait times. • An extensible system makes it easier to • Decrease lock granularity on highly contested items. experiment with this. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Self-Monitoring and Assumptions Self-Adapting Systems • Performance is important. • People do not really know how to tune applications and systems. V E R I • It would be nice to get some help from the system in tuning. T A S • Self-monitoring systems gather information about their own Margo I. Seltzer performance. Harvard University Division of Engineering and Applied Sciences Self-Monitoring and Self-Adaptation Outline Self-Monitoring in VINO • Self-Monitoring in VINO. • Measurement thread periodically collects module statistics. • Processing monitor data. • Generate detailed profiling information. • Adapting to system behavior. • Capture module inputs ( traces ) and • Conclusions. outputs ( logs ). • In-situ simulation evaluates competing algorithms and policies. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Measurement Thread Generating Traces and Logs incoming requests measurement output data thread (graft) get_stats graft points Buffer Cache other other file lock txn systems other systems other system system system systems systems outputs VINO kernel Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Generating Traces and Logs In-Situ Simulation incoming requests pass parameters incoming requests to simulator and record real parameters pass- through Buffer Cache Buffer Cache Buffer Cache Simulator outputs simulation results outputs Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
What do we do with Data? Off-line Analysis • Off-line Analysis • Use data from measurement thread to construct time series usage profile. • Monitors long-term behavior. • Conduct variance analysis. • Identifies common usage profiles. • Detects uncommon usage. • Construct predicted usage profiles. • Suggests thresholds to online system. • Determine resource thresholds from • Conducts feasibility evaluations. predicted profiles. • Online Analysis • Notify online system of thresholds. • Monitor instantaneous resource utilization. • Evaluate traces and logs; derive new • Maintain efficiency statistics. algorithms. • Detect dangerous conditions. • Simulate new algorithms, in situ. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Online Analysis Adaptation Heuristics • Receive threshold and variance • Goal: decrease application latency. information from off-line system. • Paging • Maintain dynamic statistics about: • Collect page access trace. • Cache hit rates. • Look for well-known patterns (linear, cyclic, strided). • Lock contention. • Look for page access correlation. • Disk queue lengths. • Install better prefetching algorithm. • Load averages. • Disk Wait • Context switch rates. • Similar process to paging. • Detect abnormal behavior. • Replace read-ahead for the application(s). • Dynamically trigger trace generation. • CPU Hogs • Examine profile output. • Trigger adaptation heuristics. • Recompile kernel modules in application context. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Adaptation (continued) Conclusions • Interrupt Latency • Self-monitoring is a generally useful idea. • Measure latency between interrupt arrival and delivery to process/thread. • An extensible system just makes it • Look for excessively long intervals or high variance. easier. • Check (fix) scheduling priorities. • Automatic adaptation is a cool idea. • Lock Contention • Challenging to do it correctly. • Measure lock wait times. • An extensible system makes it easier to • Decrease lock granularity on highly contested items. experiment with this. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Self-Monitoring and Assumptions Self-Adapting Systems • Performance is important. • People do not really know how to tune applications and systems. V E R I • It would be nice to get some help from the system in tuning. T A S • Self-monitoring systems gather information about their own Margo I. Seltzer performance. Harvard University Division of Engineering and Applied Sciences Self-Monitoring and Self-Adaptation Outline Self-Monitoring in VINO • Self-Monitoring in VINO. • Measurement thread periodically collects module statistics. • Processing monitor data. • Generate detailed profiling information. • Adapting to system behavior. • Capture module inputs ( traces ) and • Conclusions. outputs ( logs ). • In-situ simulation evaluates competing algorithms and policies. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Measurement Thread Generating Traces and Logs incoming requests measurement output data thread (graft) get_stats graft points Buffer Cache other other file lock txn systems other systems other system system system systems systems outputs VINO kernel Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Generating Traces and Logs In-Situ Simulation incoming requests pass parameters incoming requests to simulator and record real parameters pass- through Buffer Cache Buffer Cache Buffer Cache Simulator outputs simulation results outputs Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
What do we do with Data? Off-line Analysis • Off-line Analysis • Use data from measurement thread to construct time series usage profile. • Monitors long-term behavior. • Conduct variance analysis. • Identifies common usage profiles. • Detects uncommon usage. • Construct predicted usage profiles. • Suggests thresholds to online system. • Determine resource thresholds from • Conducts feasibility evaluations. predicted profiles. • Online Analysis • Notify online system of thresholds. • Monitor instantaneous resource utilization. • Evaluate traces and logs; derive new • Maintain efficiency statistics. algorithms. • Detect dangerous conditions. • Simulate new algorithms, in situ. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Online Analysis Adaptation Heuristics • Receive threshold and variance • Goal: decrease application latency. information from off-line system. • Paging • Maintain dynamic statistics about: • Collect page access trace. • Cache hit rates. • Look for well-known patterns (linear, cyclic, strided). • Lock contention. • Look for page access correlation. • Disk queue lengths. • Install better prefetching algorithm. • Load averages. • Disk Wait • Context switch rates. • Similar process to paging. • Detect abnormal behavior. • Replace read-ahead for the application(s). • Dynamically trigger trace generation. • CPU Hogs • Examine profile output. • Trigger adaptation heuristics. • Recompile kernel modules in application context. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Adaptation (continued) Conclusions • Interrupt Latency • Self-monitoring is a generally useful idea. • Measure latency between interrupt arrival and delivery to process/thread. • An extensible system just makes it • Look for excessively long intervals or high variance. easier. • Check (fix) scheduling priorities. • Automatic adaptation is a cool idea. • Lock Contention • Challenging to do it correctly. • Measure lock wait times. • An extensible system makes it easier to • Decrease lock granularity on highly contested items. experiment with this. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Self-Monitoring and Assumptions Self-Adapting Systems • Performance is important. • People do not really know how to tune applications and systems. V E R I • It would be nice to get some help from the system in tuning. T A S • Self-monitoring systems gather information about their own Margo I. Seltzer performance. Harvard University Division of Engineering and Applied Sciences Self-Monitoring and Self-Adaptation Outline Self-Monitoring in VINO • Self-Monitoring in VINO. • Measurement thread periodically collects module statistics. • Processing monitor data. • Generate detailed profiling information. • Adapting to system behavior. • Capture module inputs ( traces ) and • Conclusions. outputs ( logs ). • In-situ simulation evaluates competing algorithms and policies. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Measurement Thread Generating Traces and Logs incoming requests measurement output data thread (graft) get_stats graft points Buffer Cache other other file lock txn systems other systems other system system system systems systems outputs VINO kernel Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Generating Traces and Logs In-Situ Simulation incoming requests pass parameters incoming requests to simulator and record real parameters pass- through Buffer Cache Buffer Cache Buffer Cache Simulator outputs simulation results outputs Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
What do we do with Data? Off-line Analysis • Off-line Analysis • Use data from measurement thread to construct time series usage profile. • Monitors long-term behavior. • Conduct variance analysis. • Identifies common usage profiles. • Detects uncommon usage. • Construct predicted usage profiles. • Suggests thresholds to online system. • Determine resource thresholds from • Conducts feasibility evaluations. predicted profiles. • Online Analysis • Notify online system of thresholds. • Monitor instantaneous resource utilization. • Evaluate traces and logs; derive new • Maintain efficiency statistics. algorithms. • Detect dangerous conditions. • Simulate new algorithms, in situ. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Online Analysis Adaptation Heuristics • Receive threshold and variance • Goal: decrease application latency. information from off-line system. • Paging • Maintain dynamic statistics about: • Collect page access trace. • Cache hit rates. • Look for well-known patterns (linear, cyclic, strided). • Lock contention. • Look for page access correlation. • Disk queue lengths. • Install better prefetching algorithm. • Load averages. • Disk Wait • Context switch rates. • Similar process to paging. • Detect abnormal behavior. • Replace read-ahead for the application(s). • Dynamically trigger trace generation. • CPU Hogs • Examine profile output. • Trigger adaptation heuristics. • Recompile kernel modules in application context. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Adaptation (continued) Conclusions • Interrupt Latency • Self-monitoring is a generally useful idea. • Measure latency between interrupt arrival and delivery to process/thread. • An extensible system just makes it • Look for excessively long intervals or high variance. easier. • Check (fix) scheduling priorities. • Automatic adaptation is a cool idea. • Lock Contention • Challenging to do it correctly. • Measure lock wait times. • An extensible system makes it easier to • Decrease lock granularity on highly contested items. experiment with this. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Self-Monitoring and Assumptions Self-Adapting Systems • Performance is important. • People do not really know how to tune applications and systems. V E R I • It would be nice to get some help from the system in tuning. T A S • Self-monitoring systems gather information about their own Margo I. Seltzer performance. Harvard University Division of Engineering and Applied Sciences Self-Monitoring and Self-Adaptation Outline Self-Monitoring in VINO • Self-Monitoring in VINO. • Measurement thread periodically collects module statistics. • Processing monitor data. • Generate detailed profiling information. • Adapting to system behavior. • Capture module inputs ( traces ) and • Conclusions. outputs ( logs ). • In-situ simulation evaluates competing algorithms and policies. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Measurement Thread Generating Traces and Logs incoming requests measurement output data thread (graft) get_stats graft points Buffer Cache other other file lock txn systems other systems other system system system systems systems outputs VINO kernel Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Generating Traces and Logs In-Situ Simulation incoming requests pass parameters incoming requests to simulator and record real parameters pass- through Buffer Cache Buffer Cache Buffer Cache Simulator outputs simulation results outputs Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
What do we do with Data? Off-line Analysis • Off-line Analysis • Use data from measurement thread to construct time series usage profile. • Monitors long-term behavior. • Conduct variance analysis. • Identifies common usage profiles. • Detects uncommon usage. • Construct predicted usage profiles. • Suggests thresholds to online system. • Determine resource thresholds from • Conducts feasibility evaluations. predicted profiles. • Online Analysis • Notify online system of thresholds. • Monitor instantaneous resource utilization. • Evaluate traces and logs; derive new • Maintain efficiency statistics. algorithms. • Detect dangerous conditions. • Simulate new algorithms, in situ. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Online Analysis Adaptation Heuristics • Receive threshold and variance • Goal: decrease application latency. information from off-line system. • Paging • Maintain dynamic statistics about: • Collect page access trace. • Cache hit rates. • Look for well-known patterns (linear, cyclic, strided). • Lock contention. • Look for page access correlation. • Disk queue lengths. • Install better prefetching algorithm. • Load averages. • Disk Wait • Context switch rates. • Similar process to paging. • Detect abnormal behavior. • Replace read-ahead for the application(s). • Dynamically trigger trace generation. • CPU Hogs • Examine profile output. • Trigger adaptation heuristics. • Recompile kernel modules in application context. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Adaptation (continued) Conclusions • Interrupt Latency • Self-monitoring is a generally useful idea. • Measure latency between interrupt arrival and delivery to process/thread. • An extensible system just makes it • Look for excessively long intervals or high variance. easier. • Check (fix) scheduling priorities. • Automatic adaptation is a cool idea. • Lock Contention • Challenging to do it correctly. • Measure lock wait times. • An extensible system makes it easier to • Decrease lock granularity on highly contested items. experiment with this. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Self-Monitoring and Assumptions Self-Adapting Systems • Performance is important. • People do not really know how to tune applications and systems. V E R I • It would be nice to get some help from the system in tuning. T A S • Self-monitoring systems gather information about their own Margo I. Seltzer performance. Harvard University Division of Engineering and Applied Sciences Self-Monitoring and Self-Adaptation Outline Self-Monitoring in VINO • Self-Monitoring in VINO. • Measurement thread periodically collects module statistics. • Processing monitor data. • Generate detailed profiling information. • Adapting to system behavior. • Capture module inputs ( traces ) and • Conclusions. outputs ( logs ). • In-situ simulation evaluates competing algorithms and policies. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Measurement Thread Generating Traces and Logs incoming requests measurement output data thread (graft) get_stats graft points Buffer Cache other other file lock txn systems other systems other system system system systems systems outputs VINO kernel Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Generating Traces and Logs In-Situ Simulation incoming requests pass parameters incoming requests to simulator and record real parameters pass- through Buffer Cache Buffer Cache Buffer Cache Simulator outputs simulation results outputs Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
What do we do with Data? Off-line Analysis • Off-line Analysis • Use data from measurement thread to construct time series usage profile. • Monitors long-term behavior. • Conduct variance analysis. • Identifies common usage profiles. • Detects uncommon usage. • Construct predicted usage profiles. • Suggests thresholds to online system. • Determine resource thresholds from • Conducts feasibility evaluations. predicted profiles. • Online Analysis • Notify online system of thresholds. • Monitor instantaneous resource utilization. • Evaluate traces and logs; derive new • Maintain efficiency statistics. algorithms. • Detect dangerous conditions. • Simulate new algorithms, in situ. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Online Analysis Adaptation Heuristics • Receive threshold and variance • Goal: decrease application latency. information from off-line system. • Paging • Maintain dynamic statistics about: • Collect page access trace. • Cache hit rates. • Look for well-known patterns (linear, cyclic, strided). • Lock contention. • Look for page access correlation. • Disk queue lengths. • Install better prefetching algorithm. • Load averages. • Disk Wait • Context switch rates. • Similar process to paging. • Detect abnormal behavior. • Replace read-ahead for the application(s). • Dynamically trigger trace generation. • CPU Hogs • Examine profile output. • Trigger adaptation heuristics. • Recompile kernel modules in application context. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Adaptation (continued) Conclusions • Interrupt Latency • Self-monitoring is a generally useful idea. • Measure latency between interrupt arrival and delivery to process/thread. • An extensible system just makes it • Look for excessively long intervals or high variance. easier. • Check (fix) scheduling priorities. • Automatic adaptation is a cool idea. • Lock Contention • Challenging to do it correctly. • Measure lock wait times. • An extensible system makes it easier to • Decrease lock granularity on highly contested items. experiment with this. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Self-Monitoring and Assumptions Self-Adapting Systems • Performance is important. • People do not really know how to tune applications and systems. V E R I • It would be nice to get some help from the system in tuning. T A S • Self-monitoring systems gather information about their own Margo I. Seltzer performance. Harvard University Division of Engineering and Applied Sciences Self-Monitoring and Self-Adaptation Outline Self-Monitoring in VINO • Self-Monitoring in VINO. • Measurement thread periodically collects module statistics. • Processing monitor data. • Generate detailed profiling information. • Adapting to system behavior. • Capture module inputs ( traces ) and • Conclusions. outputs ( logs ). • In-situ simulation evaluates competing algorithms and policies. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Measurement Thread Generating Traces and Logs incoming requests measurement output data thread (graft) get_stats graft points Buffer Cache other other file lock txn systems other systems other system system system systems systems outputs VINO kernel Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Generating Traces and Logs In-Situ Simulation incoming requests pass parameters incoming requests to simulator and record real parameters pass- through Buffer Cache Buffer Cache Buffer Cache Simulator outputs simulation results outputs Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
What do we do with Data? Off-line Analysis • Off-line Analysis • Use data from measurement thread to construct time series usage profile. • Monitors long-term behavior. • Conduct variance analysis. • Identifies common usage profiles. • Detects uncommon usage. • Construct predicted usage profiles. • Suggests thresholds to online system. • Determine resource thresholds from • Conducts feasibility evaluations. predicted profiles. • Online Analysis • Notify online system of thresholds. • Monitor instantaneous resource utilization. • Evaluate traces and logs; derive new • Maintain efficiency statistics. algorithms. • Detect dangerous conditions. • Simulate new algorithms, in situ. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Online Analysis Adaptation Heuristics • Receive threshold and variance • Goal: decrease application latency. information from off-line system. • Paging • Maintain dynamic statistics about: • Collect page access trace. • Cache hit rates. • Look for well-known patterns (linear, cyclic, strided). • Lock contention. • Look for page access correlation. • Disk queue lengths. • Install better prefetching algorithm. • Load averages. • Disk Wait • Context switch rates. • Similar process to paging. • Detect abnormal behavior. • Replace read-ahead for the application(s). • Dynamically trigger trace generation. • CPU Hogs • Examine profile output. • Trigger adaptation heuristics. • Recompile kernel modules in application context. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Adaptation (continued) Conclusions • Interrupt Latency • Self-monitoring is a generally useful idea. • Measure latency between interrupt arrival and delivery to process/thread. • An extensible system just makes it • Look for excessively long intervals or high variance. easier. • Check (fix) scheduling priorities. • Automatic adaptation is a cool idea. • Lock Contention • Challenging to do it correctly. • Measure lock wait times. • An extensible system makes it easier to • Decrease lock granularity on highly contested items. experiment with this. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Self-Monitoring and Assumptions Self-Adapting Systems • Performance is important. • People do not really know how to tune applications and systems. V E R I • It would be nice to get some help from the system in tuning. T A S • Self-monitoring systems gather information about their own Margo I. Seltzer performance. Harvard University Division of Engineering and Applied Sciences Self-Monitoring and Self-Adaptation Outline Self-Monitoring in VINO • Self-Monitoring in VINO. • Measurement thread periodically collects module statistics. • Processing monitor data. • Generate detailed profiling information. • Adapting to system behavior. • Capture module inputs ( traces ) and • Conclusions. outputs ( logs ). • In-situ simulation evaluates competing algorithms and policies. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Measurement Thread Generating Traces and Logs incoming requests measurement output data thread (graft) get_stats graft points Buffer Cache other other file lock txn systems other systems other system system system systems systems outputs VINO kernel Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Generating Traces and Logs In-Situ Simulation incoming requests pass parameters incoming requests to simulator and record real parameters pass- through Buffer Cache Buffer Cache Buffer Cache Simulator outputs simulation results outputs Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
What do we do with Data? Off-line Analysis • Off-line Analysis • Use data from measurement thread to construct time series usage profile. • Monitors long-term behavior. • Conduct variance analysis. • Identifies common usage profiles. • Detects uncommon usage. • Construct predicted usage profiles. • Suggests thresholds to online system. • Determine resource thresholds from • Conducts feasibility evaluations. predicted profiles. • Online Analysis • Notify online system of thresholds. • Monitor instantaneous resource utilization. • Evaluate traces and logs; derive new • Maintain efficiency statistics. algorithms. • Detect dangerous conditions. • Simulate new algorithms, in situ. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Online Analysis Adaptation Heuristics • Receive threshold and variance • Goal: decrease application latency. information from off-line system. • Paging • Maintain dynamic statistics about: • Collect page access trace. • Cache hit rates. • Look for well-known patterns (linear, cyclic, strided). • Lock contention. • Look for page access correlation. • Disk queue lengths. • Install better prefetching algorithm. • Load averages. • Disk Wait • Context switch rates. • Similar process to paging. • Detect abnormal behavior. • Replace read-ahead for the application(s). • Dynamically trigger trace generation. • CPU Hogs • Examine profile output. • Trigger adaptation heuristics. • Recompile kernel modules in application context. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Adaptation (continued) Conclusions • Interrupt Latency • Self-monitoring is a generally useful idea. • Measure latency between interrupt arrival and delivery to process/thread. • An extensible system just makes it • Look for excessively long intervals or high variance. easier. • Check (fix) scheduling priorities. • Automatic adaptation is a cool idea. • Lock Contention • Challenging to do it correctly. • Measure lock wait times. • An extensible system makes it easier to • Decrease lock granularity on highly contested items. experiment with this. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Self-Monitoring and Assumptions Self-Adapting Systems • Performance is important. • People do not really know how to tune applications and systems. V E R I • It would be nice to get some help from the system in tuning. T A S • Self-monitoring systems gather information about their own Margo I. Seltzer performance. Harvard University Division of Engineering and Applied Sciences Self-Monitoring and Self-Adaptation Outline Self-Monitoring in VINO • Self-Monitoring in VINO. • Measurement thread periodically collects module statistics. • Processing monitor data. • Generate detailed profiling information. • Adapting to system behavior. • Capture module inputs ( traces ) and • Conclusions. outputs ( logs ). • In-situ simulation evaluates competing algorithms and policies. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Measurement Thread Generating Traces and Logs incoming requests measurement output data thread (graft) get_stats graft points Buffer Cache other other file lock txn systems other systems other system system system systems systems outputs VINO kernel Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Generating Traces and Logs In-Situ Simulation incoming requests pass parameters incoming requests to simulator and record real parameters pass- through Buffer Cache Buffer Cache Buffer Cache Simulator outputs simulation results outputs Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
What do we do with Data? Off-line Analysis • Off-line Analysis • Use data from measurement thread to construct time series usage profile. • Monitors long-term behavior. • Conduct variance analysis. • Identifies common usage profiles. • Detects uncommon usage. • Construct predicted usage profiles. • Suggests thresholds to online system. • Determine resource thresholds from • Conducts feasibility evaluations. predicted profiles. • Online Analysis • Notify online system of thresholds. • Monitor instantaneous resource utilization. • Evaluate traces and logs; derive new • Maintain efficiency statistics. algorithms. • Detect dangerous conditions. • Simulate new algorithms, in situ. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Online Analysis Adaptation Heuristics • Receive threshold and variance • Goal: decrease application latency. information from off-line system. • Paging • Maintain dynamic statistics about: • Collect page access trace. • Cache hit rates. • Look for well-known patterns (linear, cyclic, strided). • Lock contention. • Look for page access correlation. • Disk queue lengths. • Install better prefetching algorithm. • Load averages. • Disk Wait • Context switch rates. • Similar process to paging. • Detect abnormal behavior. • Replace read-ahead for the application(s). • Dynamically trigger trace generation. • CPU Hogs • Examine profile output. • Trigger adaptation heuristics. • Recompile kernel modules in application context. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Adaptation (continued) Conclusions • Interrupt Latency • Self-monitoring is a generally useful idea. • Measure latency between interrupt arrival and delivery to process/thread. • An extensible system just makes it • Look for excessively long intervals or high variance. easier. • Check (fix) scheduling priorities. • Automatic adaptation is a cool idea. • Lock Contention • Challenging to do it correctly. • Measure lock wait times. • An extensible system makes it easier to • Decrease lock granularity on highly contested items. experiment with this. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Self-Monitoring and Assumptions Self-Adapting Systems • Performance is important. • People do not really know how to tune applications and systems. V E R I • It would be nice to get some help from the system in tuning. T A S • Self-monitoring systems gather information about their own Margo I. Seltzer performance. Harvard University Division of Engineering and Applied Sciences Self-Monitoring and Self-Adaptation Outline Self-Monitoring in VINO • Self-Monitoring in VINO. • Measurement thread periodically collects module statistics. • Processing monitor data. • Generate detailed profiling information. • Adapting to system behavior. • Capture module inputs ( traces ) and • Conclusions. outputs ( logs ). • In-situ simulation evaluates competing algorithms and policies. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Measurement Thread Generating Traces and Logs incoming requests measurement output data thread (graft) get_stats graft points Buffer Cache other other file lock txn systems other systems other system system system systems systems outputs VINO kernel Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Generating Traces and Logs In-Situ Simulation incoming requests pass parameters incoming requests to simulator and record real parameters pass- through Buffer Cache Buffer Cache Buffer Cache Simulator outputs simulation results outputs Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
What do we do with Data? Off-line Analysis • Off-line Analysis • Use data from measurement thread to construct time series usage profile. • Monitors long-term behavior. • Conduct variance analysis. • Identifies common usage profiles. • Detects uncommon usage. • Construct predicted usage profiles. • Suggests thresholds to online system. • Determine resource thresholds from • Conducts feasibility evaluations. predicted profiles. • Online Analysis • Notify online system of thresholds. • Monitor instantaneous resource utilization. • Evaluate traces and logs; derive new • Maintain efficiency statistics. algorithms. • Detect dangerous conditions. • Simulate new algorithms, in situ. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation Online Analysis Adaptation Heuristics • Receive threshold and variance • Goal: decrease application latency. information from off-line system. • Paging • Maintain dynamic statistics about: • Collect page access trace. • Cache hit rates. • Look for well-known patterns (linear, cyclic, strided). • Lock contention. • Look for page access correlation. • Disk queue lengths. • Install better prefetching algorithm. • Load averages. • Disk Wait • Context switch rates. • Similar process to paging. • Detect abnormal behavior. • Replace read-ahead for the application(s). • Dynamically trigger trace generation. • CPU Hogs • Examine profile output. • Trigger adaptation heuristics. • Recompile kernel modules in application context. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Adaptation (continued) Conclusions • Interrupt Latency • Self-monitoring is a generally useful idea. • Measure latency between interrupt arrival and delivery to process/thread. • An extensible system just makes it • Look for excessively long intervals or high variance. easier. • Check (fix) scheduling priorities. • Automatic adaptation is a cool idea. • Lock Contention • Challenging to do it correctly. • Measure lock wait times. • An extensible system makes it easier to • Decrease lock granularity on highly contested items. experiment with this. Self-Monitoring and Self-Adaptation Self-Monitoring and Self-Adaptation
Recommend

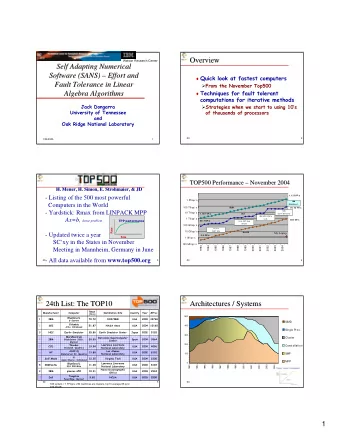





















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.