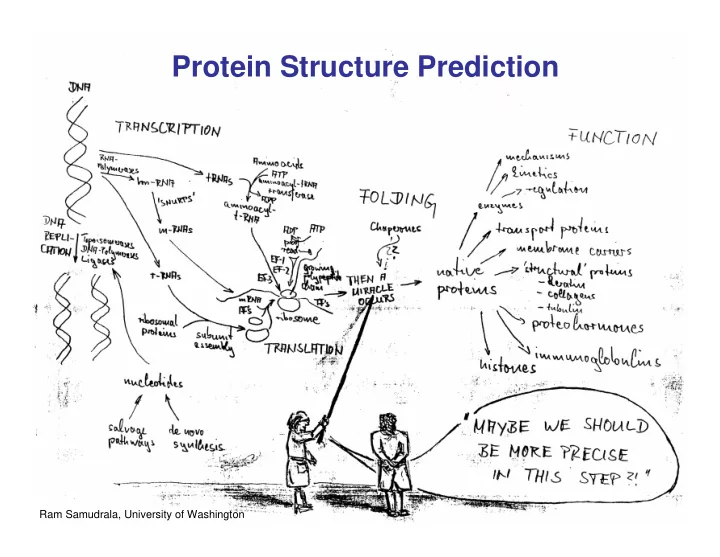
Protein Structure Prediction 1 Ram Samudrala, University of - PowerPoint PPT Presentation
Protein Structure Prediction 1 Ram Samudrala, University of Washington Rationale for Understanding Protein Structure and Function structure determination Protein sequence structure prediction -large numbers of sequences, including Protein
Protein Structure Prediction 1 Ram Samudrala, University of Washington
Rationale for Understanding Protein Structure and Function structure determination Protein sequence structure prediction -large numbers of sequences, including Protein structure whole genomes - three dimensional - complicated ? - mediates function Protein function homology rational mutagenesis biochemical analysis - rational drug design and treatment of disease model studies - protein and genetic engineering - build networks to model cellular pathways - study organismal function and evolution 2
Protein Folding DNA …-CUA-AAA-GAA-GGU-GUU-AGC-AAG-GUU-… protein sequence …-L-K-E-G-V-S-K-D-… one amino acid unfolded protein not unique mobile inactive expanded spontaneous self-organization irregular (~1 second) native state 3
Protein Folding DNA …-CUA-AAA-GAA-GGU-GUU-AGC-AAG-GUU-… protein sequence …-L-K-E-G-V-S-K-D-… one amino acid unfolded protein not unique mobile inactive expanded spontaneous self-organisation irregular (~1 second) unique shape native state precisely ordered stable/functional globular/compact helices and sheets 4
Protein Folding Landscape Large multi-dimensional space of changing conformations J=10 -3 s unfolded barrier free energy height molten globule Δ G * * native J=10 -8 s − Δ * G ∝ jump time (J) e RT 5 folding reaction
Protein Primary Structure twenty types of amino acids two amino acids join by forming a peptide bond R R H O H C H H N OH C α C α C α OH N C N C H H O O H H R each residue in the amino acid main chain has two degrees of freedom ( φ and ψ) R R H O H O H H χ χ ψ φ ψ φ C φ N C φ N C α C α C α C α N C N C ψ ψ χ χ H H O H O H R R 6 the amino acid side chains can have up to four degrees of freedom (χ 1-4 )
Protein Secondary Structure many φ,ψ combinations are not possible β sheet (anti-parallel) +180 β L φ 0 α C -180 0 ψ -180 +180 N β sheet (parallel) α helix C N 7
Protein Tertiary and Quaternary Structures Ribonuclease inhibitor (2bnh) Haemoglobin (1hbh) Hemagglutinin (1hgd) 8
Methods for Determining Protein Structure X-ray crystallography Protein sequence NMR spectroscopy expensive -large numbers of and slow sequences, including Protein structure whole genomes - three dimensional - complicated ? - mediates function Protein function homology rational mutagenesis biochemical analysis - rational drug design and treatment of disease model studies - protein and genetic engineering - build networks to model cellular pathways - study organismal function and evolution 9
A Naïve Approach • Use the first principles to produce the native conformation of a protein • not only the correct structure, but entire energy landscape ab initio !!! • it would explain dynamic behavior of a protein Let’s see how this could work… • there are only 5 atom types (C, H, O, N, S) , so if we can accurately model interactions between them, we could get to the solution of the folding problem So, why is it then so complicated… • atomic interactions cannot be modeled with sufficient accuracy (plus proteins are only marginally stable) • some phenomena are highly non-linear (for example, Van der Waals forces) • large number in the degrees of freedom + modeling water molecules 10
Predictions Needed NOW!!! • Pure ab initio approach is out of reach for a long time • We must adopt a less purist approach What should we do? • use approximations • use all available information • vast number of sequences • large number of structures • functional site information 11
Methods for Predicting Protein Structure comparative modeling fold recognition Protein sequence ab initio prediction -large numbers of sequences, including Protein structure whole genomes - three dimensional - complicated ? - mediates function Protein function homology rational mutagenesis biochemical analysis - rational drug design and treatment of disease model studies - protein and genetic engineering - build networks to model cellular pathways - study organismal function and evolution 12
Overall Approach Protein Sequence Multiple Sequence Database Searching Domain Assignment Alignment Fold Secondary No Recognition Homologue Structure in PDB and Disorder Prediction Yes Yes Comparative Sequence-Structure Predicted Modelling Alignment Fold Ab-initio No Structure 3-D Protein Model Prediction 13 modified from http://bioinf.cs.ucl.ac.uk
Comparative (Homology) Modeling of Protein Structure Aims to produce protein models with high accuracy • • Proteins that have similar sequences (i.e., related by evolution) have similar three- dimensional structures • A model of a protein whose structure is not known can be constructed if the structure of a related protein has been determined by experimental methods • Similarity must be obvious and significant for good models to be built • Need ways to build regions that are not similar between the two related proteins • Need ways to move model closer to the native structure 14
Comparative Modeling of Protein Structure scan align … … KDHPFGFAVPTKNPDGTMNLMNWECAIP KDPPAGIGAPQDN----QNIMLWNAVIP ** * * * * * * * ** construct non-conserved build initial model side chains and main chains refine 15
Let’s Look Closer at Steps of Homology Modeling 1. Template recognition and initial alignment 2. Alignment correction 3. Backbone generation 4. Loop modeling 5. Side-chain modeling 6. Model optimization 7. Model validation 16
Let’s Look Closer at Steps of Homology Modeling 1. Template recognition and initial alignment 2. Alignment correction 3. Backbone generation 4. Loop modeling 5. Side-chain modeling 6. Model optimization 7. Model validation 17
Let’s Look Closer at Steps of Homology Modeling 1. Template recognition and initial alignment 2. Alignment correction 3. Backbone generation 4. Loop modeling 5. Side-chain modeling 6. Model optimization 7. Model validation 18
1. Template Recognition Recognition of similarity between the target and template Target – protein with unknown structure. Template – protein with known structure. Main difficulty – deciding which template to pick, multiple choices/template structures. Template structure can be found by searching for structures in PDB using sequence-sequence alignment methods . 19
Two Zones of Sequence Alignment Sequence identity 100 Safe homology modeling zone 50 Twilight zone 50 100 150 200 Alignment length 20
3. Backbone Generation 1. If alignment between target and template is ready, copy the backbone coordinates of those template residues that are aligned. 2. If two aligned residues are the same, copy their side chain coordinates as well. 21
4. Loop Modeling insertion AHYATPTTT AH---TPSS deletion Occur mostly between secondary structures, in the loop regions. Loop conformations – difficult to predict. Approaches to loop modeling: knowledge-based : searches the PDB for loops with known structure - energy-based : an energy function is used to evaluate the quality of a loop. - Energy minimization or Monte Carlo. 22
4. Loop Modeling – Database Approach Scan database and search protein fragments with correct number of residues and correct end-to-end distances 23
5. Side-Chain Modeling Side chain conformations – rotamers. In similar proteins - side chains have similar conformations. If % identity is high - side chain conformations can be copied from template to target. If % identity is not very high - modeling of side chains using libraries of rotamers and different rotamers are scored with energy functions. Problem: side chain configurations depend on backbone conformation which is predicted, not real E 2 E 3 E = min ( E 1 , E 2 , E 3 ) E 1 24
6. Model Optimization • Energy optimization of entire structure. • Since conformation of backbone depends on conformations of side chains and vice versa - iterative approach Predict rotamers Shift in backbone 25
6. Model Optimization??? CASP5 assessors, homology modeling category: “We are forced to draw the disappointing conclusion that, similarly to what observed in previous editions of the experiment, no model resulted to be closer to the target structure than the template to any significant extent.” The consensus is not to refine the model, as refinement usually pulls the model away from the native structure!! 26
Historical Perspective on Comparative Modeling BC alignment excellent side chain ~ 80% short loops 1.0 Å longer loops 2.0 Å 27
Historical Perspective on Comparative Modeling BC CASP1 alignment excellent poor side chain ~ 80% ~ 50% short loops 1.0 Å ~ 3.0 Å longer loops 2.0 Å > 5.0 Å 28
Prediction for CASP4 target T128/sodm C α RMSD of 1.0 Å for 198 residues (PID 50%) 29
Prediction for CASP4 target T122/trpa C α RMSD of 2.9 Å for 241 residues (PID 33%) 30
Prediction for CASP4 target T125/sp18 C α RMSD of 4.4 Å for 137 residues (PID 24%) 31
Prediction for CASP4 target T112/dhso C α RMSD of 4.9 Å for 348 residues (PID 24%) 32
Prediction for CASP4 target T92/yeco C α RMSD of 5.6 Å for 104 residues (PID 12%) 33
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.