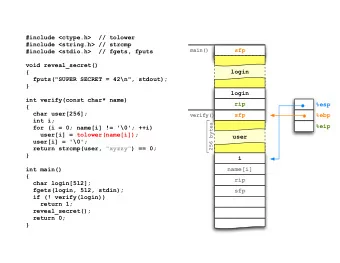
Processes pid = 1000 pid = 1001 stack stack heap heap data/globals data/globals code code file descriptor table: file descriptor table: 1 2 3 … 1 2 3 … saved registers: saved registers: %rax %rbx %rcx %rax %rbx %rcx %rdx %rsp %rip %rdx %rsp %rip Every process has its own PID, virtual address space, fd table, registers, signal handlers, etc… Processes are generally isolated
Processes pid = 1000 pid = 1001 stack stack heap heap data/globals data/globals pipe code code pipe file descriptor table: file descriptor table: 1 2 3 … 1 2 3 … saved registers: saved registers: %rax %rbx %rcx %rax %rbx %rcx %rdx %rsp %rip %rdx %rsp %rip Processes do not share memory (usually), but they can exchange information using pipes
Processes pid = 1000 pid = 1001 SIGSTOP stack stack heap heap data/globals data/globals pipe code code pipe file descriptor table: file descriptor table: 1 2 3 … 1 2 3 … saved registers: saved registers: %rax %rbx %rcx %rax %rbx %rcx %rdx %rsp %rip %rdx %rsp %rip Processes can synchronize using signals
Threads pid = 1000 tid = 1001 stack stack saved registers: heap %rax %rbx %rcx data/globals %rdx %rsp %rip code tid = 1002 file descriptor table: stack 1 2 3 … saved registers: saved registers: %rax %rbx %rcx %rax %rbx %rcx %rdx %rsp %rip %rdx %rsp %rip Threads are similar to processes; they have a separate stack and saved registers (and a handful of other separated things). But they share most resources across the process
Threads pid = 1000 tid = 1001 stack1 stack2 heap data/globals code file descriptor table: file descriptor table: 1 2 3 … 1 2 3 … saved registers: saved registers: %rax %rbx %rcx %rax %rbx %rcx %rdx %rsp %rip %rdx %rsp %rip Under the hood, a thread gets its own “process control block” and is scheduled independently, but it is linked to the process that spawned it
What’s the difference? Considerations in designing a browser: • Speed • Memory usage • Battery/CPU usage • Security, stability
What’s the difference?
Recommend
More recommend
Unleash a World of Digital Possibilities—Browse, Share, and Explore Content Without Boundaries