Pipeline Hazards Again Computer System Architecture I-Fet ch - PowerPoint PPT Presentation
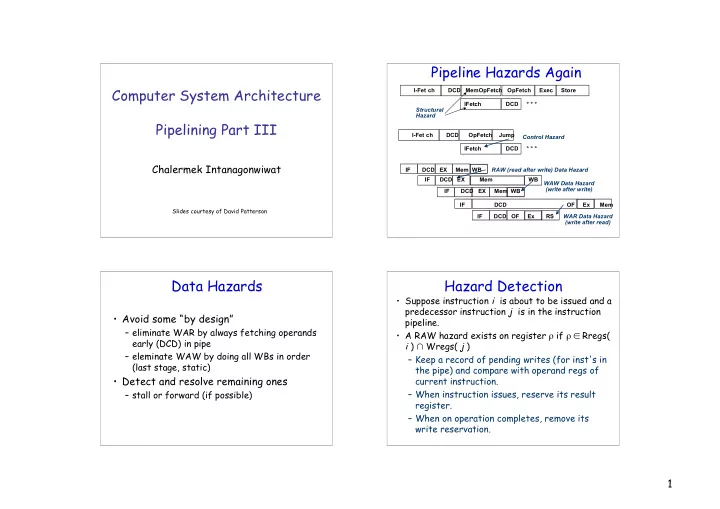
Pipeline Hazards Again Computer System Architecture I-Fet ch DCD MemOpFetch OpFetch Exec Store IFetch DCD Structural Hazard Pipelining Part III I-Fet ch DCD OpFetch Jump Control
Pipeline Hazards Again Computer System Architecture I-Fet ch DCD MemOpFetch OpFetch Exec Store IFetch DCD ° ° ° Structural Hazard Pipelining Part III I-Fet ch DCD OpFetch Jump Control Hazard IFetch DCD ° ° ° Chalermek Intanagonwiwat IF DCD EX Mem WB RAW (read after write) Data Hazard IF DCD EX Mem WB WAW Data Hazard (write after write) IF DCD EX Mem WB IF DCD OF Ex Mem Slides courtesy of David Patterson IF DCD OF Ex RS WAR Data Hazard (write after read) Data Hazards Hazard Detection • Suppose instruction i is about to be issued and a predecessor instruction j is in the instruction • Avoid some “by design” pipeline. – eliminate WAR by always fetching operands • A RAW hazard exists on register ρ if ρ ∈ Rregs( early (DCD) in pipe i ) ∩ Wregs( j ) – eleminate WAW by doing all WBs in order – Keep a record of pending writes (for inst's in (last stage, static) the pipe) and compare with operand regs of • Detect and resolve remaining ones current instruction. – When instruction issues, reserve its result – stall or forward (if possible) register. – When on operation completes, remove its write reservation. 1
Record of Pending Writes Hazard Detection (cont.) IAU • Current operand npc registers • A WAW hazard exists on register ρ if ρ ∈ • Pending writes I mem Wregs( i ) ∩ Wregs( j ) • hazard <= Regs ((rs == rw ex) & • A WAR hazard exists on register ρ if ρ ∈ op rw rs rt PC regW ex ) OR Wregs( i ) ∩ Rregs( j ) ((rs == rw mem) & im n op rw B A regW me ) OR ((rs == rw wb) & alu regW wb ) OR S n op rw ((rt == rw ex) & regW ex ) OR D mem ((rt == rw mem) & m regW me ) OR n op rw ((rt == rw wb ) & Regs regW wb ) Resolve RAW by forwarding What about memory operations? ° If instructions are initiated in IAU • Detect nearest order and operations always valid write op op Rd Ra Rb npc occur in the same stage, there operand register can be no hazards between I mem and forward into memory operations! op latches, Regs op rw rs rt PC ° What does delaying WB on bypassing Forward op Rd Ra Rb arithmetic A B mux remainder of the operations cost? pipe im n op rw B A – cycles ? • Increase muxes – hardware ? alu to add paths from Rd R pipeline registers ° What about data dependence S n op rw on loads? • Data Forwarding R1 <- R4 + R5 D mem = Data Bypassing T Rd R2 <- Mem[ R2 + I ] m R3 <- R2 + R1 n op rw to reg => file Regs "Delayed Loads" 2
What about Interrupts, Compiler Avoiding Load Stalls: Traps, Faults? • External Interrupts: scheduled unscheduled – Allow pipeline to drain, 54% gcc 31% – Load PC with interrupt address 42% spice • Faults (within instruction, restartable) 14% 65% – Force trap instruction into IF tex 25% – disable writes till trap hits WB 0% 20% 40% 60% 80% % loads stalling pipeline – must save multiple PCs or PC + state Refer to MIPS solution Exception Handling Exception Problem IAU • Exceptions/Interrupts: 5 instructions npc executing in 5 stage pipeline I mem detect bad instruction address –How to stop the pipeline? Regs lw $2,20($5) PC –Restart? detect bad instruction im n op rw B A –Who caused the interrupt? detect overflow alu S detect bad data address D mem m Regs Allow exception to take effect 3
Resolution: Exception Problem (cont.) Freeze IAU Stage Problem interrupts occurring above & npc IF Page fault on instruction fetch; Bubble I mem misaligned memory access; freeze Regs memory-protection violation op rw rs rt PC Below bubble ID Undefined or illegal opcode im n op rw B A EX Arithmetic exception alu MEM Page fault on data fetch; misaligned S n op rw memory access; memory-protection violation; D mem m memory error n op rw Regs Partitioned Instruction Issue Summary (simple Superscalar) • Pipelines pass control information down the independent int and FP issue to separate pipelines pipe just as data moves down pipe I-Cache • Forwarding/Stalls handled by local control Int Reg Inst Issue FP Reg and Bypass • Exceptions stop the pipeline Operand / • MIPS I instruction set architecture made Result Busses pipeline visible (delayed branch, delayed load) Int Unit Load / FP Add FP Mul Store Unit • More performance from deeper pipelines, D-Cache parallelism Single Issue Total Time = Int Time + FP Time Max Speedup: Total Time MAX(Int Time, FP Time) 4
Example Multiple Pipes/ Harder Superscalar Basic Loop: Cycles load Ra <- Ai 1 load Ry <- Yi 1 Issues: IR0 IR1 Reg. File ports fmult Rm <- Ra*Rx 7 Register faddRs <- Rm+Ry 5 File Detecting Data store Ai <- Rs 1 Dependences Bypassing inc Yi 1 A B B A RAW Hazard dec i 1 WAR Hazard inc Ai 1 branch 1 Multiple load/store ops? R R D$ D$ Total Single Issue Cycles: 19 ( 7 integer, 12 floating point) Branches Minimum with Dual Issue: 12 T T Potential Speedup: 1.6 !!! Unrolled Loop that Minimizes Getting CPI < 1: Issuing Multiple Stalls for Scalar Instructions/Cycle 1 Loop: LD F0,0(R1) Type PipeStages 2 LD F6,-8(R1) 3 LD F10,-16(R1) Int. instruction IF ID EX MEM WB 4 LD F14,-24(R1) 1. Loop: LD F0, 0(R1) 5 FP instruction IF ID EX1 EX2 EX3 MEM WB ADDD F4,F0,F2 2. ADDD F4, F0, F2 6 ADDD F8,F6,F2 3. SD 0(R1), F4 7 ADDD F12,F10,F2 4. SUBI R1, R1, #8 8 ADDD F16,F14,F2 Int. instruction IF ID EX MEM WB 5. BNEZ R1, Loop 9 SD 0(R1),F4 10 SD -8(R1),F8 FP instruction IF ID EX1 EX2 EX3 MEM 11 SD -16(R1),F12 LD to ADDD: 1 Cycle 12 SUBI R1,R1,#32 ADDD to SD: 2 Cycles 13 BNEZ R1,LOOP Int. instruction IF ID EX MEM WB 14 SD 8(R1),F16 ; 8-32 = -24 Delayed Branch FP instruction IF ID EX1 EX2 EX3 14 clock cycles, or 3.5 per iteration 5
Software Pipelining Loop Unrolling in Superscalar • Observation: if iterations from loops are independent, then can get ILP by taking Integer instruction FP instruction Clock cycle Loop: LD F0,0(R1) 1 instructions from different iterations LD F6,-8(R1) 2 • Software pipelining: reorganizes loops so LD F10,-16(R1) ADDD F4,F0,F2 3 LD F14,-24(R1) ADDD F8,F6,F2 4 that each iteration is made from LD F18,-32(R1) ADDD F12,F10,F2 5 instructions chosen from different SD 0(R1),F4 ADDD F16,F14,F2 6 iterations of the original loop ( Tomasulo SD -8(R1),F8 ADDD F20,F18,F2 7 SD -16(R1),F12 8 in SW) Iteration SD -24(R1),F16 9 0 Iteration Iteration 1 SUBI R1,R1,#40 10 2 Iteration Horizontal not Vertical 3 Iteration BNEZ R1,LOOP 11 4 SD -32(R1),F20 12 Software- • Unrolled 5 times to avoid delays (+1 due to SS) pipelined iteration • 12 clocks, or 2.4 clocks per iteration Limits of Superscalar Software Pipelining Example • While Integer/FP split is simple for the HW, get CPI of 0.5 only for programs Before: Unrolled 3 times 1 LD After: Software Pipelined with: F0,0(R1) 2 ADDD F4,F0,F2 (at least 3 iterations) – Exactly 50% FP operations 3 SD SUBI R1,R1,#16 0(R1),F4 LD F0,16(R1) – No hazards ADDD F4,F0,F2 4 LD F0,-8(R1) • If more instructions issue at same time, LD F0,8(R1) 5 ADDD F4,F0,F2 1 SD 16(R1),F4 ; Stores M[i] greater difficulty of decode and issue 6 SD -8(R1),F4 2 ADDD F4,F0,F2 ; Adds to M[i-1] 3 LD F0,0(R1); Loads M[i-2] – Even 2-scalar => examine 2 opcodes, 6 4 SUBI R1,R1,#8 7 LD F0,-16(R1) 5 BNEZ R1,LOOP register specifiers, & decide if 1 or 2 8 ADDD F4,F0,F2 SD 16(R1), F4 instructions can issue 9 SD ADDD F4,F0,F2 -16(R1),F4 SD 8(R1),F4 10 SUBI R1,R1,#24 11 BNEZ R1,LOOP 6
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.